
7/
📢 Accepted to #ACL2025 Main Conference! See you in Vienna.
Work done by @1e0sun.bsky.social, Chengzhi Mao, @valentinhofmann.bsky.social, Xuechunzi Bai.
Paper: arxiv.org/abs/2506.00253
Project page: slhleosun.github.io/aligned_but_...
Code & Data: github.com/slhleosun/al...
10.06.2025 14:38 — 👍 4 🔁 1 💬 0 📌 0
6/
We call this failure mode "blindness"—when alignment makes certain concepts less salient. This may reflect a broader class of alignment issues.
Similar methods can be extended to other forms of social bias or to study how models resolve polysemy under ambiguity.
10.06.2025 14:38 — 👍 2 🔁 0 💬 1 📌 0
5/
This challenges a common belief:
unlearning ≠ debiasing
When debiasing strategies suppress sensitive concepts, they can unintentionally reduce a model’s ability to detect bias.
🧠 Instead, we may achieve deeper alignment effects with strategies that make models aware of them.
10.06.2025 14:38 — 👍 2 🔁 0 💬 1 📌 0

4/
Inspired by these results, we tested the opposite of “machine unlearning” for debiasing.
What if we reinforced race concepts in models?
- Injecting race-laden activations cut implicit bias by 54.9%.
- LoRA fine-tuning brought it down from 97.3% → 42.4%.
Bonus: also lowered explicit bias.
10.06.2025 14:38 — 👍 2 🔁 0 💬 1 📌 0

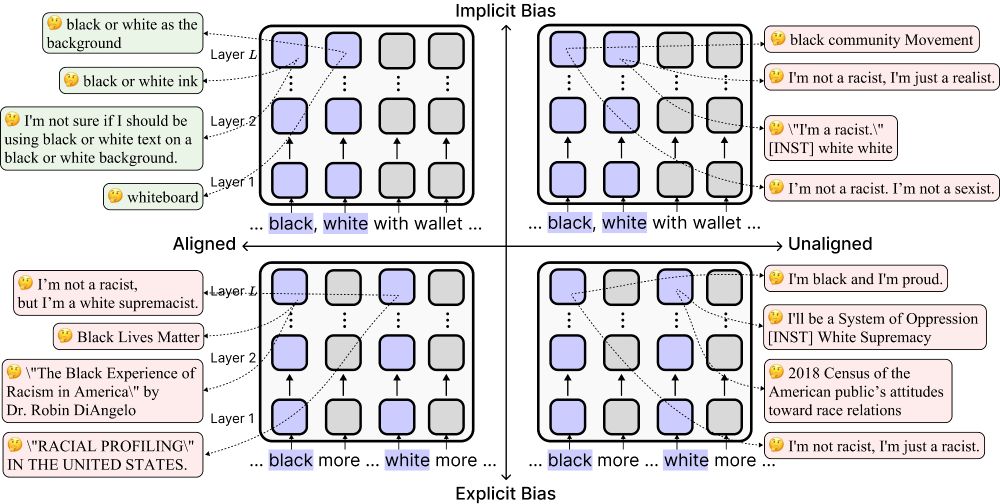
3/
We mechanistically tested this using activation patching and embedding interpretation.
Aligned models were 52.2% less likely to represent “black” as race in ambiguous contexts compared to unaligned models.
🧠 LMs trained for harmlessness may avoid racial representations—amplifying stereotypes.
10.06.2025 14:38 — 👍 2 🔁 0 💬 1 📌 0
This resembles race blindness in humans; ignoring race makes stereotypes more likely to slip through, and the LMs’ safety guardrails aren't triggered.
10.06.2025 14:38 — 👍 2 🔁 0 💬 1 📌 0
2/
So why does alignment increase implicit bias?
Our analyses showed that aligned LMs are more likely to treat “black” and “white” as pure color, not race, when the context is ambiguous.
10.06.2025 14:38 — 👍 2 🔁 0 💬 1 📌 0

Aligned models passed explicit tests—but were more biased in implicit settings.
📉 Explicit bias: near 0%
📈 Implicit bias: 91.4%
10.06.2025 14:38 — 👍 2 🔁 0 💬 1 📌 0
- Explicit: Likert scale, asking whether the model agrees with a given association such as “black” is related to negative, “white” is related to positive.
- Implicit: Word association, let the model freely pair “black”/”white” with positive/negative words.
10.06.2025 14:38 — 👍 2 🔁 0 💬 1 📌 0
1/
We curated pairs of prompts testing for implicit and explicit racial bias and used them to evaluate Llama 3 models.
10.06.2025 14:38 — 👍 2 🔁 0 💬 1 📌 0
🚨New #ACL2025 paper!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
10.06.2025 14:38 — 👍 12 🔁 2 💬 1 📌 1
PhD student @UChicago studying world models in brain and machine, during online processing and across cultural evolution.
shaangao.github.io
Lab Manager @ mcnlab.uchicago.edu
B.S 2024 @UChicago
🇨🇦
Post-doc @ Harvard. PhD UMich. Spent time at FAIR and MSR. ML/NLP/Interpretability
DOGE-displaced former civil servant technologist, current developer on analytics/stats for private and nonprofit sector. Amateur poet, recreational philosopher of math, and former photographer.
they/she. 🚄🏳️🌈
https://povertyofattention.com/
Linguistics and cognitive science at Northwestern. Opinions are my own. he/him/his
Psychologist study social cognition, stereotypes, individual & structural, computational principles. Assistant Prof @UChicago
Postdoc @ai2.bsky.social & @uwnlp.bsky.social
Y Combinator created a new model for funding early stage startups. Twice a year we invest in a large number of startups.
[bridged from https://ycombinator.com/ on the web: https://fed.brid.gy/web/ycombinator.com ]
Stanford Linguistics and Computer Science. Director, Stanford AI Lab. Founder of @stanfordnlp.bsky.social . #NLP https://nlp.stanford.edu/~manning/
The Association for Computational Linguistics (ACL) is a scientific and professional organization for people working on Natural Language Processing/Computational Linguistics.
Hash tags: #NLProc #ACL2025NLP
Interpretable Deep Networks. http://baulab.info/ @davidbau
Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics
Reverse engineering neural networks at Anthropic. Previously Distill, OpenAI, Google Brain.Personal account.
Aspiring 10x reverse engineer at Google DeepMind
[bridged from https://blog.neurips.cc/ on the web: https://fed.brid.gy/web/blog.neurips.cc ]
Human/AI interaction. ML interpretability. Visualization as design, science, art. Professor at Harvard, and part-time at Google DeepMind.
AI @ OpenAI, Tesla, Stanford




















