This thread is a bit long, but I thought it’d be interesting to share just one of the mundane parts of the deep learning stack that break and have to be rethought as models and training scale.
08.06.2025 00:07 — 👍 1 🔁 0 💬 0 📌 0
To save, you need to let each GPU save their own partial safetensors, because communication is slow, and then line up the memory blocks and merge into one file.
08.06.2025 00:07 — 👍 1 🔁 0 💬 1 📌 0
Safetensors are great for hosting checkpoints and make no assumptions about if your model is distributed by saving full unshared parameters. To work natively with safetensors, DCP needs to tell each GPU the exact slice of data to read without loading the full parameter.
08.06.2025 00:07 — 👍 0 🔁 0 💬 1 📌 0
On startup, DCP has to map your old GPU layout to your new one so each GPU knows which file to read from and only read the data they need. But there’s one last problem; when you’re ready to take your model to another tool (serving, eval, etc), it expects safetenors checkpoints.
08.06.2025 00:07 — 👍 0 🔁 0 💬 1 📌 0
Distributed Checkpoints (DCP) solve this by having every GPU save their own checkpoint asynchronously so you can save a checkpoint in less than a second. But this creates a new problem, the next time you want to use the model, you might have a different number of GPUs.
08.06.2025 00:07 — 👍 0 🔁 0 💬 1 📌 0
What goes into saving checkpoints is not something that many people think about, but as models get bigger this becomes a challenge. The biggest open models now have checkpoints over 700gb that can take tens of minutes every time you want to consolidate into a checkpoint.
pytorch.org/blog/hugging...
08.06.2025 00:07 — 👍 6 🔁 2 💬 1 📌 0
I’m enjoying it while it lasts before everything fully homogenizes again
26.02.2025 02:04 — 👍 1 🔁 0 💬 0 📌 0
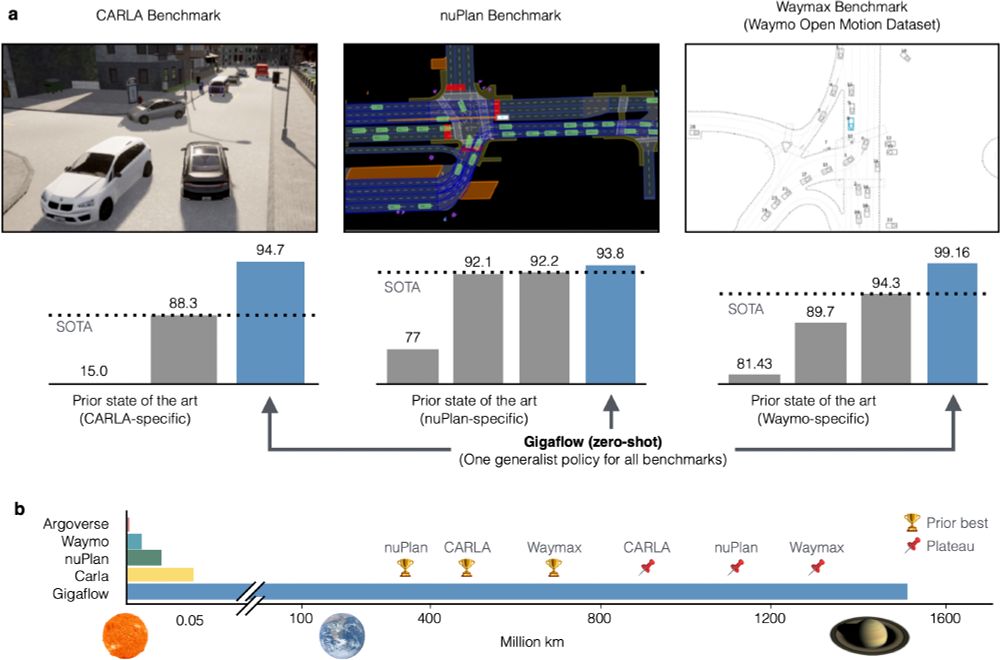
We've built a simulated driving agent that we trained on 1.6 billion km of driving with no human data.
It is SOTA on every planning benchmark we tried.
In self-play, it goes 20 years between collisions.
06.02.2025 18:34 — 👍 298 🔁 55 💬 22 📌 8
Braess's paradox - Wikipedia
Aren’t these two paradoxes functionally the same? en.m.wikipedia.org/wiki/Braess%...
27.01.2025 08:54 — 👍 4 🔁 0 💬 0 📌 0
x.com
Original post here: x.com/jjitsev/stat...
25.01.2025 18:07 — 👍 5 🔁 0 💬 0 📌 0

In the Alice In Wonderland (github.com/LAION-AI/AIW) reasoning and generalization benchmark, DeepSeek R1 appears to perform much more like o1 mini than o1 -preview. (Plot from laion-ai)
25.01.2025 17:25 — 👍 4 🔁 0 💬 2 📌 0
What are the best benchmarks for reasoning models?
20.01.2025 10:32 — 👍 1 🔁 0 💬 0 📌 0
Can we just study LLM activations/behavior because it’s interesting and it can tell us things about language and AI without imbuing artificial importance or meaning on top of it?
14.01.2025 14:05 — 👍 2 🔁 0 💬 0 📌 0
Haha, that wasn’t lost on me. Facebook’s still going strong, but it’s a different site and users from when I was in HS.
13.01.2025 21:14 — 👍 2 🔁 0 💬 0 📌 0
If you can choose who follows you, that sounds more like “friends” from the old Facebook days.
13.01.2025 20:53 — 👍 2 🔁 0 💬 1 📌 0
I found out about Warp because I was on jury duty with one of their devs 😂 It’s been great compared to the Mac’s default terminal.
07.01.2025 23:58 — 👍 4 🔁 0 💬 0 📌 0
How do you add these?
07.01.2025 16:10 — 👍 2 🔁 0 💬 1 📌 0
Maybe let’s go the other direction and include blog posts in CVs too.
07.01.2025 15:30 — 👍 2 🔁 0 💬 1 📌 0
That would imply that we solved self-driving (image recognition) and search (language understanding), among other things.
07.01.2025 02:33 — 👍 2 🔁 0 💬 0 📌 0
This could be a good case for mixed models. The model parsing the text could likely be smaller or be fairly cheap like DeepSeek
04.01.2025 21:45 — 👍 1 🔁 0 💬 1 📌 0
Thankfully in a small startup you only have to sell an idea to a couple of people and you can get going.
03.01.2025 20:34 — 👍 0 🔁 0 💬 0 📌 0
One startup I joined had a model getting 95% on benchmarks but terrible in practice. Spent the first 6 months developing new benchmarks instead of a new model.
03.01.2025 01:30 — 👍 1 🔁 0 💬 1 📌 0
I always set out to propose a new idea and end up having to proposing a new benchmark instead
03.01.2025 00:31 — 👍 4 🔁 0 💬 1 📌 0
What if humanity knows X and wants to understand Z. If a computer can give us Y so that we can understand Z, that would be useful for science. Though I’d say that we still didn’t know Y ourselves yet.
03.01.2025 00:26 — 👍 0 🔁 0 💬 0 📌 0
Imagine if under the hood O1 is just calling “write better code” over and over again 😂
03.01.2025 00:14 — 👍 5 🔁 0 💬 0 📌 0
I posted about this recently. Benchmarks show what models can’t do, not what they can do.
02.01.2025 23:49 — 👍 1 🔁 0 💬 0 📌 0
Plagiarize other people’s research
01.01.2025 00:54 — 👍 1 🔁 0 💬 0 📌 1
Imagine being an editor for an LLM, so much work with low confidence that you’ll have something interesting in the end.
30.12.2024 22:33 — 👍 3 🔁 0 💬 0 📌 0
I remember a lot of focus being on the loss function. My impression was that we thought we had models that would work well if only we had a good perceptual loss to train them with. In comes the GAN
30.12.2024 00:59 — 👍 0 🔁 0 💬 0 📌 0
Base models are closer, but they’re still affected by the company’s decisions on which data to filter out and more indirectly on what data is given free hosting on the internet.
28.12.2024 20:52 — 👍 0 🔁 0 💬 0 📌 0
Patterns. Simulation. Graphics. Compilers. Creative Coding.
mgmalheiros.github.io
PhD in Computer Science. Academic researcher at UEM.
Also at https://mathstodon.xyz/@mgmalheiros
Tensors and neural networks in Python with strong hardware acceleration. PyTorch is an open source project at the Linux Foundation. #PyTorchFoundation
pytorch.org
Iranian-Canadian dude who runs Sanctus.ca and tries to survive other human beings, bro what even is this planet. Works in AI and human biological rejuvenation. Refuses to consider LLMs conscious until they start demanding the Epstein files be released.
Open source LLM fine-tuning! 🦥
Github: http://github.com/unslothai/unsloth Discord: https://discord.gg/unsloth
Easily distracted, currently building open source AI. Living online since FidoNet
Biologist, just fed up at this point because *gestures everywhere*
discontent creator
https://pivot-to-ai.com
davidgerard.co.uk
rocknerd.co.uk
🐘 https://circumstances.run/@davidgerard
books!
https://davidgerard.co.uk/blockchain/book/
https://davidgerard.co.uk/blockchain/libra/
London
he/him
Слава Україна
Kaggle.com - Kaggle is the world's largest data science community with powerful tools and resources to help you achieve your data science goals.
Senior Data Scientist at BuzzFeed in San Francisco // AI content generation ethics and R&D // plotter of pretty charts
https://minimaxir.com
CEO, Expanso. Prev: Protocol Labs, MSFT, K8s, Kubeflow, GOOG, AMZN, etc. 4x founder/CEO. The universe is a vector in Hilbert space.
API @OpenAI | 🏳️🌈 he/him
Associate professor at Télécom Paris in machine listening and audio applied to extended reality
That guy who makes visual essays about software at https://samwho.dev.
Developer Educator @ ngrok.com. Want to pair on something ngrok related? Let's do it! https://cal.com/samwho/workhours
He/him.
Professor, researcher, maker of things
~Book: Atlas of AI
~Installation: Calculating Empires
~NYT video: AI's Real Environmental Impact https://www.nytimes.com/2025/09/26/opinion/ai-quartz-mining-hurricane-helene.html
Alignment & Retrieval @ IBM Research
Competitive Machine Learning director at NVIDIA, 3x Kaggle Grandmaster CPMP, ENS ULM alumni. Kaggle profile: https://www.kaggle.com/cpmpml
Assistant Professor @tticconnect.bsky.social
Understanding intelligence, one pixel at a time.
shiry.ttic.edu
PhD student at UC Santa Cruz working on autonomous cyber-operations. Interested in decision making and it's applications to cybersecurity.
🏳️🌈🩷💜💙