Nowadays ML projects feel like they need to be compressed into a few months. Its refreshing to be able to work on something for a few years!
But also a slog.
10.02.2025 16:57 — 👍 1 🔁 0 💬 0 📌 0
Thanks @sean-mcleish.bsky.social, Neel Jain, jwkirchenbauer.bsky.social, Siddharth Singh, Brian Bartoldson, Bhavya Kailkhu, Abhinav Bhatele.
Superhero @jonasgeiping.bsky.social started architecture search for this two years ago, & wrote a distributed framework from scratch to handle bugs with AMD 🤯
10.02.2025 15:58 — 👍 3 🔁 0 💬 1 📌 0

Huginn is just a proof of concept.
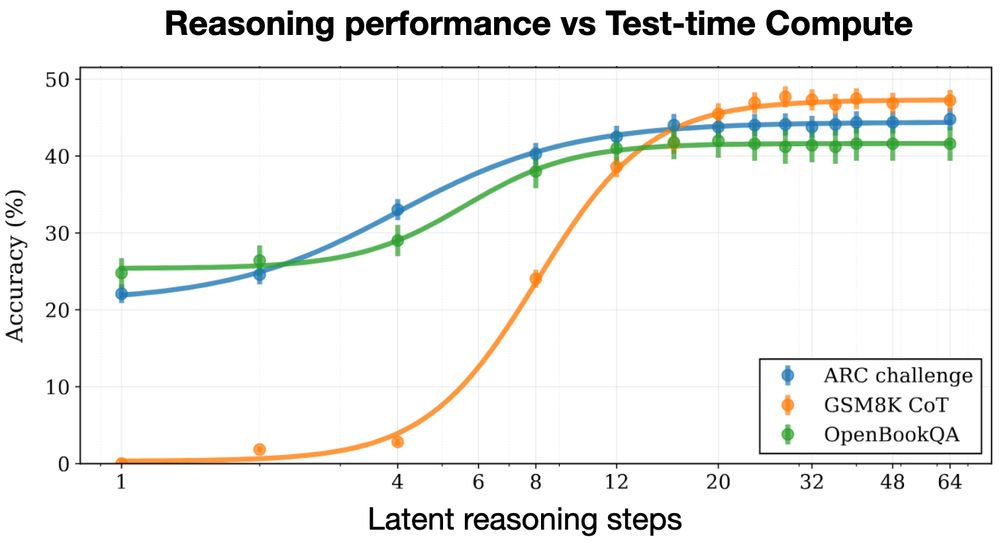
Still, Huggin-3.5B can beat OLMo-7B-0724 (with CoT) at GSM8K by a wide margin (42% vs 29%).
Huginn has half the parameters, 1/3 the training tokens, no explicit fine-tuning, and the LR was never annealed.
Latent reasoning still wins.
10.02.2025 15:58 — 👍 2 🔁 0 💬 1 📌 0

Recurrence improves reasoning a lot. To show this, we did a comparison with a standard architecture.
We train a standard 3.5B LLM from scratch on 180B tokens. Then we train a recurrent 3.5B model on the same tokens.
The recurrent model does 5X better on GSM8K.
10.02.2025 15:58 — 👍 2 🔁 0 💬 1 📌 0

Huginn was built for reasoning from the ground up, not just fine-tuned on CoT.
We built our reasoning system by putting a recurrent block inside the LLM. On a forward pass, we loop this block a random number of times. By looping it more times, we dial up compute.
10.02.2025 15:58 — 👍 2 🔁 0 💬 1 📌 0
New open source reasoning model!
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
10.02.2025 15:58 — 👍 11 🔁 4 💬 1 📌 2
📢PSA: #NeurIPS2024 recordings are now publicly available!
The workshops always have tons of interesting things on at once, so the FOMO is real😵💫 Luckily it's all recorded, so I've been catching up on what I missed.
Thread below with some personal highlights🧵
22.01.2025 21:06 — 👍 128 🔁 33 💬 1 📌 1
Here’s what doesn’t check out. They claim $5.5M by assuming a $2 per GPU-hour “rental cost”. On AWS, an H100 (with the same compute cores as an H800) costs $12.28/hour on demand, and $5.39 with a 3-year reservation. H800s are prob worth less, but…$2/hour? Idunno about that.
29.01.2025 17:12 — 👍 3 🔁 0 💬 0 📌 0
They'd need to eliminate token routing inefficiency and keep communication volume down (their H800 GPUs communicate slower than the H100s in the benchmark). They accomplish this using pipelined training, which industry labs prefer over the Pytorch FSDP implementation.
29.01.2025 17:12 — 👍 1 🔁 0 💬 1 📌 0

In a Pytorch Foundation Benchmark, the H100 rips through 1500 tokens per second.
For 34B, Pytorch Foundation reports throughput of 1500 tokens/sec per GPU.
With this throughput, DeepSeek’s 2.664M GPU-hour pre-training run would rip through 14.3T tokens. DeepSeek claims to have trained on 14.8T tokens.
This part checks out...but only with killer engineering.
29.01.2025 17:12 — 👍 0 🔁 0 💬 1 📌 0
Let’s sanity check DeepSeek’s claim to train on 2048 GPUs for under 2 months, for a cost of $5.6M. It sort of checks out and sort of doesn't.
The v3 model is an MoE with 37B (out of 671B) active parameters. Let's compare to the cost of a 34B dense model. 🧵
29.01.2025 17:12 — 👍 10 🔁 2 💬 1 📌 0
Professor of Psychology @ University of Southern California. Studies brain, body, & behavior changes in new parents. My book Dad Brain: The New Science of Fatherhood and How it Shapes Men's Lives, comes out June 9 on Flatiron Books/Macmillan.
Machine Learning Professor
https://cims.nyu.edu/~andrewgw
CS PhD student at UNC Chapel Hill
Website: http://amartya21.github.io
Postdoctoral fellow at ETH AI Center, working on Computational Social Science + NLP. Previously a PhD in CS at UMD, advised by Philip Resnik. Internships at MSR, AI2. he/him.
On the job market this cycle!
alexanderhoyle.com
ML, trekking, enjoying life
ML/LLM research. Prev @BrownUniversity
AI researcher & engineer @Meta working on @PyTorch torchtune in NYC; interests in generative models, RL, and evolutionary strategies
💻 https://github.com/pbontrager 📝 https://tinyurl.com/philips-papers
Lifelong learner | Exploring topics mostly related to technology & sharing knowledge.
Previously: Intuit Inc.
Ph.D. student at CMU Robotics Institute | Visiting Researcher at FAIR Meta
Opinions expressed are my own
📍Pittsburgh, USA 🔗 akashsharma02.github.io
PhD Student @UW-Madison, working on synthetic data, instruction tuning, and foundation models, @BrownUniversity '24
https://avitrost.github.io/
Professor of EECS and Robotics at University of Michigan. Control theory, hybrid & cyber-physical systems, sys id, algorithms, safe autonomy. More info @ http://web.eecs.umich.edu/~necmiye/
Associate Professor @ Georgia Tech
computer vision & robotics/embodied AI
http://faculty.cc.gatech.edu/~zk15
PhD student at Rice university. Working on deep learning theory and practice.
PhD candidate @UMD | Responsible AI
PhD-ing Clip@UMD
https://houyu0930.github.io/
work on theoretical foundations of AI, MLLM reliability/Eval, optimization, high dimensional probability/statistics, AI for science/healthcare; director of center on AIF4S @USC 🚲🏔️🥾🏊♂️
RS at DeepMind.
willwhitney.com
Machine learning prof at U Toronto. Working on evals and AGI governance.




















