Perhaps the kind of thinking the LLMs used is like a kind of search. Perhaps the kind humans usually use is too.
The question of what it "really is" will be very difficult to answer or even ask precisely. The question of how to most effectively model it to get results, is easier.
21.11.2025 18:45 — 👍 0 🔁 0 💬 1 📌 0
Something like the numpy/JAX thing also happens in humans.
I have a colleague who is a native French speaker, but can only think about science in English. Not because the are not enough French words, but because the thoughts don't come in French.
21.11.2025 18:45 — 👍 0 🔁 0 💬 1 📌 0
I find it effective to use an intentional stance, i.e. to model them similarly to humans. I believe this gets better results than thinking of them as algorithms like search.
This is not about what they *really are*, it is about what gets good results, for this human user.
21.11.2025 18:45 — 👍 0 🔁 0 💬 1 📌 0
Yes!
The key question is what mental model should we humans have of LLMs, to allow us to get the best out of them. ("LLM psychology")
21.11.2025 18:45 — 👍 0 🔁 0 💬 1 📌 0
More boldly: modern LLMs actually think. They are trained by RL to solve problems outside their training data. They can come up with proofs of new theorems. Surely they can think of an equation to fit data and code it up.
Maybe this is saying the same as you but in anthropomorphic language.
21.11.2025 15:09 — 👍 1 🔁 0 💬 1 📌 0
To your original point: the relevant training data is certainly more than just neuroscience, but also more than just function fitting. It's any code that implemented any equation for any purpose.
21.11.2025 15:09 — 👍 1 🔁 0 💬 1 📌 0
Sometimes it feels like the LLM is a Prima Donna, and the prompt is a motivational pep talk putting it in just the right frame of mind to get peak performance.
21.11.2025 15:09 — 👍 1 🔁 1 💬 1 📌 0
2. The gradient ascent ran in JAX. When we asked the LLM to write the code in JAX, it got less creative. Perhaps because JAX code in the training set is mainly pure ML, but numpy code is science.
Solution: we asked it to write in numpy, then had yet another LLM instance translate numpy to JAX!
21.11.2025 15:09 — 👍 1 🔁 0 💬 1 📌 0
Two annectodal observations:
1. We tried asking the LLM to do both of these things in one prompt. It didn't work as well. Perhaps when the LLM "thought" it had to also write a fitting function, it became too "conservative" to creatively come up with weird functions.
21.11.2025 15:09 — 👍 1 🔁 0 💬 1 📌 0
The second prompt quoted the prediction function just written, and asked a new LLM instance to find an approximate start point for gradient descent to avoid local maxima.
But the LLM never had to write code to do the final parameter search.
21.11.2025 15:09 — 👍 1 🔁 0 💬 1 📌 0
We used two prompts. The first prompt asked the LLM for a function predicting a cell's response to a stimulus, given the cell's tuning parameters (no fitting code).
We externally fit each cell's parameters with gradient descent; this fitting code wasn't written by the LLM
21.11.2025 15:09 — 👍 1 🔁 0 💬 1 📌 0
Perhaps because the AI was trained on all of science, it makes these connections between fields better.
I think what it did here was assemble several things that were used before, in a new combination, for a new purpose.
But that's what most science progress is anyway!
19.11.2025 21:50 — 👍 2 🔁 0 💬 1 📌 0

Stretched exponential function - Wikipedia
Good question! I don't myself know of any uses of e^-(x^p) in neuroscience (including that paper) but it is used in other fields and has a wikipedia page.
en.wikipedia.org/wiki/Stretch...
19.11.2025 21:50 — 👍 3 🔁 0 💬 1 📌 0

Our lab is looking for a postdoc! We have interesting projects and cutting-edge techniques such as Neuropixels Opto, Light Beads Microscopy and more. We would be delighted to receive your application. Deadline is 25 November 2025. More info here:
www.ucl.ac.uk/cortexlab/po...
12.11.2025 15:41 — 👍 39 🔁 26 💬 0 📌 0

2. Yes, the LLMs explain their reasoning, and it makes sense They say what they saw in the graphical diagnostics and how it informed their choices. (Examples in the paper's appendix). Ablation tests confirm they really use the plots! This is what makes the search over equations practical.
16.11.2025 15:11 — 👍 5 🔁 0 💬 1 📌 0

Thanks Dan!
1. Combinatorial SR seems impractical because evaluating each function needs a non-convex gradient descent parameter search. We had the LLMs write functions estimating gradient search startpoints, which ablation tests showed was essential. Combinatorial SR couldn’t have done this.
16.11.2025 15:11 — 👍 4 🔁 0 💬 1 📌 0
10. Finally, some thoughts. The AI scientist excelled at equation discovery because its success could be quantified. AI scientists can now help with problems like this in any research field. Interpreting the results for now still required humans. Next year, who knows.
14.11.2025 18:07 — 👍 7 🔁 0 💬 1 📌 0

9. Because the AI system gave us an explicit equation, we could make exactly solvable models for the computational benefits and potential circuit mechanisms of high-dimensional coding. Humans did this part too!
14.11.2025 18:07 — 👍 7 🔁 0 💬 1 📌 0

8. We proved that when p<2, the tuning curves’ sharp peaks yield power-law PCA spectra of exponent 2(p+1). Most cells had p~1, explaining the observed exponent of ~4. The same model explained high-dimensional coding in head-direction cells. Humans did this part.
14.11.2025 18:07 — 👍 7 🔁 0 💬 1 📌 0

7. The equation the AI scientist found is simple and, in retrospect, we humans could have come up it with ourselves. But we didn’t. The AI scientist did. The key innovation was replacing the Gaussian power of 2 with a parameter p controlling the peak shape.
14.11.2025 18:07 — 👍 9 🔁 1 💬 2 📌 0

6. The AI scientist took 45 minutes and $8.25 in LLM tokens to find a new tuning equation that fits the data better, and predicts the population code’s high-dimensional structure – even though we had only tasked it to model single-cell tuning.
14.11.2025 18:07 — 👍 12 🔁 3 💬 1 📌 0

5. The LLM was given fit-quality scores for previous equations, and graphical diagnostics comparing the fits to raw data. It explained how it used these graphics to improve the equations, in the docstrings of the code it wrote.
14.11.2025 18:07 — 👍 5 🔁 0 💬 1 📌 0

4. Resolving this conundrum needs a new model for orientation tuning. We found one with AI science. Equations modelling tuning curves were encoded as Python programs, and a reasoning LLM repeatedly created new models improving on previous attempts.
14.11.2025 18:07 — 👍 5 🔁 0 💬 1 📌 0

3. Visual cortex encodes even low-dimensional stimuli like oriented gratings with high-dimensional power-law codes. But classical tuning models like the double Gaussian predict low-dimensional codes with exponential spectra.
14.11.2025 18:07 — 👍 6 🔁 0 💬 1 📌 0

Characterizing neuronal population geometry with AI equation discovery
The visual cortex contains millions of neurons, whose combined activity forms a population code representing visual stimuli. There is, however, a discrepancy between our understanding of this code at ...
1. New preprint resolving a conundrum in systems neuroscience with an AI scientist, and humans Reilly Tilbury, Dabin Kwon, @haydari.bsky.social, @jacobmratliff.bsky.social, @bio-emergent.bsky.social, @carandinilab.net, @kevinjmiller.bsky.social, @neurokim.bsky.social
www.biorxiv.org/content/10.1...
14.11.2025 18:07 — 👍 94 🔁 26 💬 1 📌 8

Want to collaborate with the International Brain Laboratory on your own project? We have funding to work with groups anywhere in the world to do new large-scale projects and we are looking for new partners! Learn more and apply: www.internationalbrainlab.com/ibl-core-apply
11.09.2025 12:27 — 👍 24 🔁 14 💬 1 📌 2

Two flagship papers from the International Brain Laboratory, now out in @Nature.com:
🧠 Brain-wide map of neural activity during complex behaviour: doi.org/10.1038/s41586-025-09235-0
🧠 Brain-wide representations of prior information in mouse decision-making: doi.org/10.1038/s41586-025-09226-1 +
03.09.2025 16:22 — 👍 123 🔁 69 💬 2 📌 12
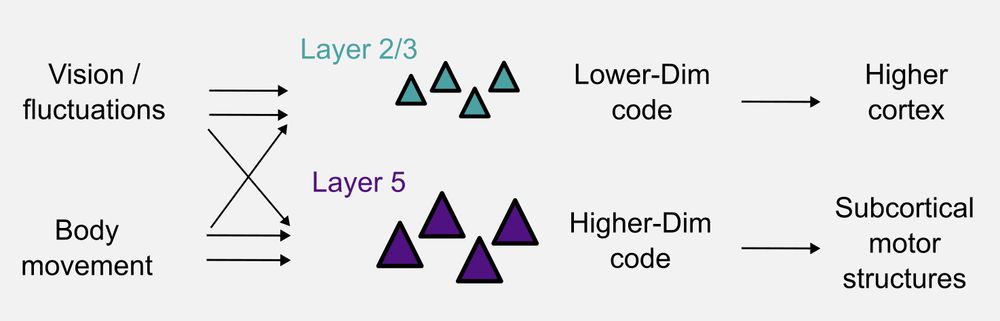
A new study led by @timothysit.bsky.social reveals that different layers of mouse V1 integrate visual and non-visual signals differently.
Activity is dominated by vision (or spontaneous fluctuations) in L2/3 and by movement in L5. This leads to different geometries.
www.biorxiv.org/content/10.1...
18.07.2025 16:55 — 👍 71 🔁 19 💬 0 📌 2











