RSL: Really Simple Licensing
The open content licensing standard for the AI-first Internet
Anyone compiling discussions/thoughts on emerging licensing schemes and preference signals? eg rslstandard.org and github.com/creativecomm... ? externalizing some notes here datalicenses.org, but want to find where these discussions are happening!
18.09.2025 18:43 — 👍 2 🔁 1 💬 0 📌 0
Excited to be giving a talk on data leverage to the Singapore AI Safety Hub. Trying to capture updated thoughts from recent years, and have long wanted to better connect leverage/collective bargaining to the safety context.
14.08.2025 08:05 — 👍 0 🔁 0 💬 0 📌 0
About the workshop – ACA@NeurIPS
About a week away from the deadline to submit to the
✨ Workshop on Algorithmic Collective Action (ACA) ✨
acaworkshop.github.io
at NeurIPS 2025!
14.08.2025 07:56 — 👍 1 🔁 0 💬 0 📌 0
(1) ongoing challenges in benchmarking, (2) challenges in communicating benchmarks to the public, (3) dataset documentation, and (4) post-hoc dataset "reverse engineering"
The original post: dataleverage.substack.com/p/selling-ag...
08.08.2025 22:31 — 👍 1 🔁 0 💬 1 📌 0
who paid that Dr for a verified attestation with provenance can use this attestation as a quality signal; a promise to consumers about the exact nature of the evaluation. A "9/10 dentists recommend" for a chatbot.
More generally, I think there are interesting connections between current discourse &
08.08.2025 22:31 — 👍 1 🔁 0 💬 1 📌 0
For some types of info, we can maybe treat as open and focus on selling convenient/"nice" packages (ala Wikimedia Enterprise)
But attestations provide another object to transact over. Valuable info (a Dr giving thumbs up/down on medical responses) may leak, but the AI developer
08.08.2025 22:31 — 👍 1 🔁 0 💬 1 📌 0
So in a post-AI world, to help people transact over work that produces information, we likely need:
- individual property-ish rights over info (not a great way to go, IMO)
- rights that enable collective bargaining (good!)
- or...
08.08.2025 22:31 — 👍 2 🔁 0 💬 1 📌 0
The core challenge: many inputs into AI are information, and thus hard to design efficient markets for. Info is hard to exclude (pre-training data remains very hard to exclude, but even post-training data may be hard without sufficient effort)
08.08.2025 22:31 — 👍 1 🔁 0 💬 1 📌 0
It looks like some skepticism was warranted (not much progress towards this vision yet). I do think "dataset details as quality signals" is still possible though, and could play a key role in addressing looming information economics challenges.
08.08.2025 22:31 — 👍 1 🔁 1 💬 1 📌 0
🧵In several recent posts, I speculated that eventually, dataset details may become an important quality signal for consumers choosing AI products.
"This model is good for asking health questions, because 10,000 doctors attested to supporting training and/or eval". Etc.
08.08.2025 22:31 — 👍 3 🔁 1 💬 1 📌 0
“Attentional agency” — talk in new stage b at facct in the session right now!
24.06.2025 07:48 — 👍 1 🔁 0 💬 0 📌 0
Off to FAccT; Excited to see faces old and new!
21.06.2025 21:50 — 👍 6 🔁 0 💬 0 📌 0
Do some aspects seem wrong (in the next 2 posts, I get into how these ideas interact w/ reinforcement learning)?
27.05.2025 15:45 — 👍 1 🔁 0 💬 1 📌 0
This has implications for Internet policy, for understanding where the value in AI comes from, and for thinking about why we might even consider a certain model to be "good"!
This first post leans heavily on recent work with Zachary Wojtowicz and Shrey Jain, to appear at this upcoming FAccT
27.05.2025 15:45 — 👍 1 🔁 0 💬 1 📌 0
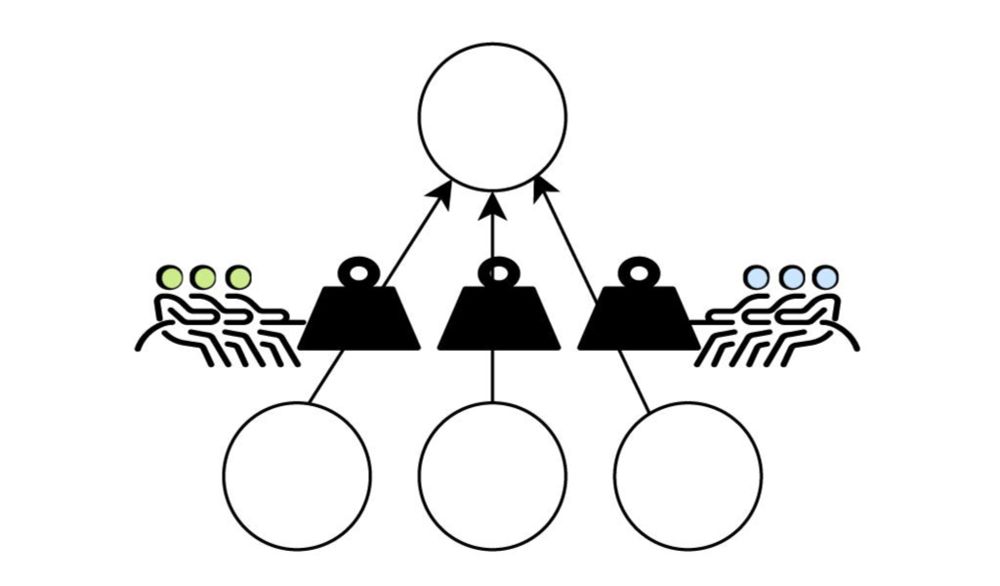
Sharing a new paper (led by Aditya Karan):
there's growing interest in algorithmic collective action, when a "collective" acts through data to impact a recommender system, classifier, or other model.
But... what happens if two collectives act at the same time?
02.05.2025 18:44 — 👍 2 🔁 1 💬 1 📌 0

Public AI, Data Appraisal, and Data Debates
A consortium of Public AI labs can substantially improve data pricing, which may also help to concretize debates about the ethics and legality of training practices.
New early draft post: "Public AI, Data Appraisal, and Data Debates"
"A consortium of Public AI labs can substantially improve data pricing, which may also help to concretize debates about the ethics and legality of training practices."
dataleverage.substack.com/p/public-ai-...
03.04.2025 17:52 — 👍 1 🔁 0 💬 0 📌 0

Model Plurality
Current research in “plural alignment” concentrates on making AI models amenable to diverse human values. But plurality is not simply a safeguard against bias or an engine of efficiency: it’s a key in...
“Algo decision making systems are “leviathans”, harmful not for their arbitrariness or opacity, but systemacity of decisions"
- @christinalu.bsky.social on need for plural #AI model ontologies (sounds technical, but has big consequences for human #commons)
www.combinationsmag.com/model-plural...
02.04.2025 07:57 — 👍 6 🔁 2 💬 2 📌 0
Here's my round-up as a markdown file: github.com/nickmvincent...
Here's the newsletter post, Tipping Points for Content Ecosystems: dataleverage.substack.com/p/tipping-po...
14.02.2025 18:25 — 👍 0 🔁 0 💬 0 📌 0
Breakthrough AI to solve the world's biggest problems.
› Join us: http://allenai.org/careers
› Get our newsletter: https://share.hsforms.com/1uJkWs5aDRHWhiky3aHooIg3ioxm
Assistant Professor at @cs.ubc.ca and @vectorinstitute.ai working on Natural Language Processing. Book: https://lostinautomatictranslation.com/
Program Manager of @internetarchive.eu – opinions strictly my own. Photographer, Wife, Mother, Daughter, Sister, Aunt, Cat Servant, Coffee Lover, Immigrant, Traveler, Geek, Participant & Observer.
🇺🇸&🇬🇧 🥰💍🇦🇷&🇪🇸 🏠 🇳🇱
iSchool@UT Austin. Computational Social Science, HCI, and dogs.
Assistant professor at University of Minnesota CS. Human-centered AI, interpretable ML, hybrid intelligence systems.
CS PhD candidate at GroupLens Lab, UMN
MEng, BA philosophy, comp sci @ 🌽ell
yoga teacher, dog mom, aspiring matriarch of AI ethics
2nd year PhD student studying human-centered AI at the University of Minnesota.
Website: https://malikkhadar.github.io/
Building personalized Bluesky feeds for academics! Pin Paper Skygest, which serves posts about papers from accounts you're following: https://bsky.app/profile/paper-feed.bsky.social/feed/preprintdigest. By @sjgreenwood.bsky.social and @nkgarg.bsky.social
Own your algorithm.
👉 https://graze.social/
⚙️ Need product support? Skip the DMs: https://tinyurl.com/3hcabn8v
✨ Building something cool? Join us on Discord: https://discord.gg/Y6UkgsFx4D
Professional account, professor at the University of Wisconsin – Madison, in the Information School, as a part of the School of Computer, Data, and Information Sciences.
w: http://jacob.thebault-spieker.com
researching AI [evaluation, governance, accountability]
Critical AI literacy. Runs WeandAI.org and BetterImagesofAI.org
TLA Tech for Disability and RSA RAIN, AI and Ethics Journal, 100 Brilliant Women in AI Ethics™ 2021, Computer Weekly Women in UK Tech Rising Star
Pssst the Broligarchs don’t care about us
ACM Conference on Fairness, Accountability, and Transparency (ACM FAccT). June 23rd to June 26th, 2025, in Athens, Greece. #FAccT2025
https://facctconference.org/
Asst Prof @ University of Washington Information School // PhD in English from WashU in St. Louis
I’m interested in books, data, social media, and digital humanities.
They call me "Eyre Jordan" on the bball court 🏀
https://melaniewalsh.org/
Incoming PhD @ MIT EECS. ugrad philosophy & CS @ UWa
Postdoc UCIrvine, advised by Anne Marie Piper and Erik Sudderth. Interests: HCI, AI / ML, accessibility, social computing. Prev: PhD NorthwesternU, Intern SlackHQ
Driven by industry progress, inspired by provocative leadership, plus don't mind a good pair of shoes or a great @PennStateFball scoreboard either.
We're an academic community for Plurality research & technology | Cooperate across differences | DM us your news, research, jobs, grants & fellowships.
plurality.institute