
People often use synthetic corruptions to test model robustness, but do these reflect real-world challenges?
We explore this in detail in our CVPR 2025 Workshop paper:
Are Synthetic Corruptions A Reliable Proxy For Real-World Corruptions?
arxiv.org/abs/2505.04835
by: @margretkeuper.bsky.social
24.07.2025 09:16 — 👍 1 🔁 1 💬 0 📌 0

🚨Deadline Extension Alert!
Our Non-proceedings track is open till August 15th for the eXCV workshop at ICCV.
Our nectar track accepts published papers, as is.
More info at: excv-workshop.github.io
@iccv.bsky.social #ICCV2025
18.07.2025 09:31 — 👍 5 🔁 5 💬 1 📌 0
⏳Still need to wait for your last experiment results?
📣 We're pleased to announce that the deadline for non-proceeding track #CV4DC at @iccv.bsky.social has been extended to August 15, 2025
Looking forward to your submissions! cv4dc.github.io/2025/
24.07.2025 06:20 — 👍 2 🔁 2 💬 0 📌 0
🌀Spatial Reasoners
📄 spatialreasoners.github.io
🔗 github.com/spatialreaso...
13.07.2025 08:00 — 👍 0 🔁 0 💬 0 📌 0
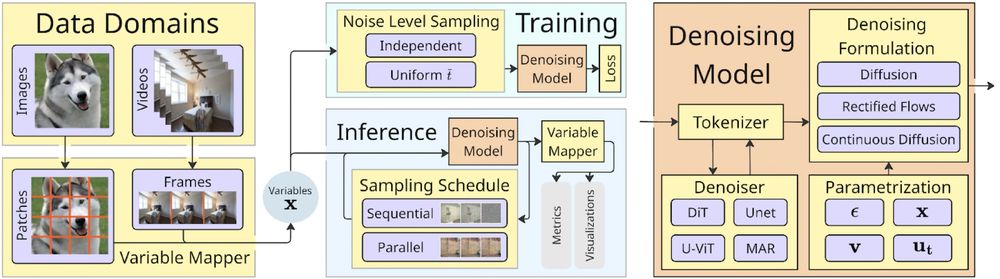
Image for "🌀Spatial Reasoners for Continuous Variables in Any Domains"
4/ "🌀Spatial Reasoners for Continuous Variables in Any Domains" by @bartpog.bsky.social, @chriswewer.bsky.social, Bernt Schiele, and @janericlenssen.bsky.social (CODEML Workshop)
🔍 Software framework for training Spatial Reasoning Models in any domain
13.07.2025 08:00 — 👍 0 🔁 0 💬 1 📌 0
🔍 Can you really trust the explanations your classifier gives you? We show which pixels in the input are provably important to the classifier’s prediction within a radius around the input.
📄 openreview.net/pdf?id=NngoE...
🔗 github.com/AlaaAnani/ce...
13.07.2025 08:00 — 👍 0 🔁 0 💬 1 📌 0
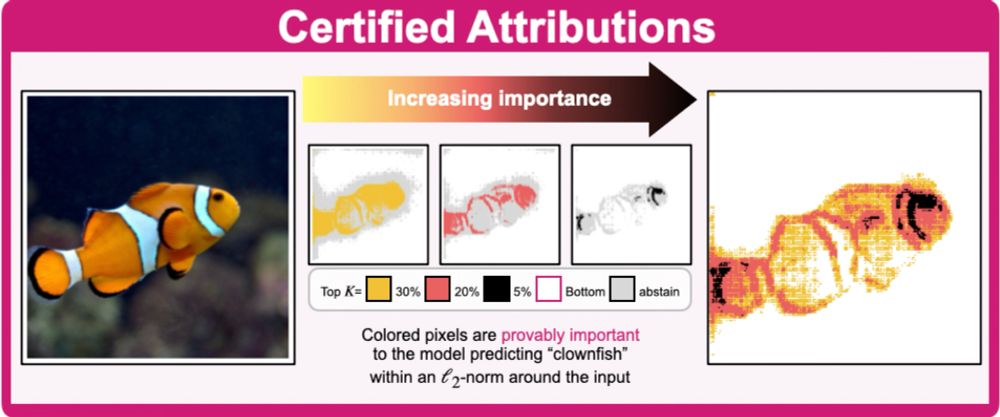
Image for "Pixel-level Certified Explanations via Randomized Smoothing"
3/ "Pixel-level Certified Explanations via Randomized Smoothing" by @aanani.bsky.social, Tobias Lorenz, Mario Fritz, and Bernt Schiele
13.07.2025 08:00 — 👍 1 🔁 0 💬 1 📌 0
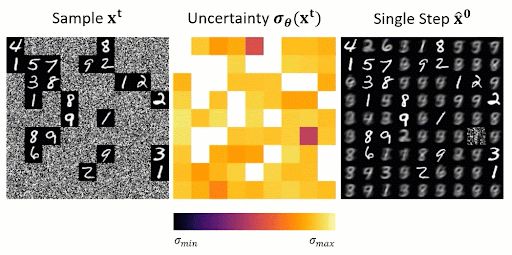
Image for "Spatial Reasoning with Denoising Models"
2/ "Spatial Reasoning with Denoising Models" by @chriswewer.bsky.social, @bartpog.bsky.social, Bernt Schiele, and @janericlenssen.bsky.social
🔍 Can image generators solve visual Sudoku? Naively, no, with sequentialization and the correct order, they can!
13.07.2025 08:00 — 👍 0 🔁 0 💬 1 📌 0
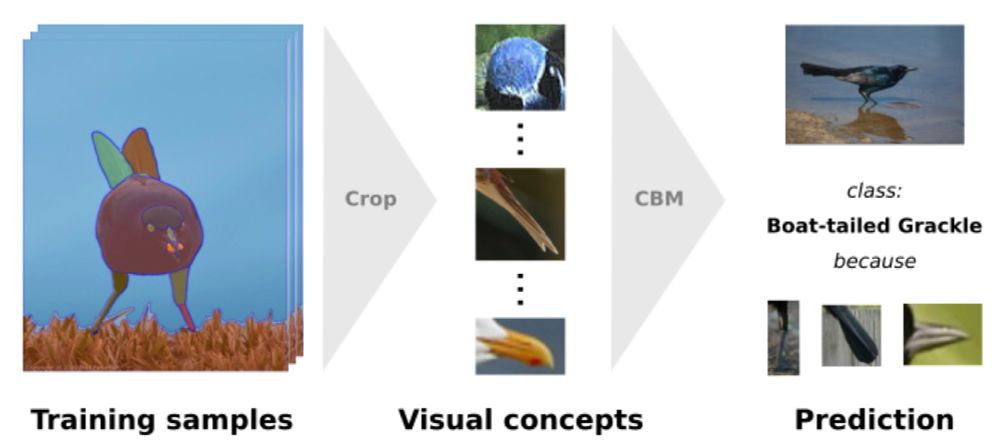
Image for "DCBM: Data-Efficient Visual Concept Bottleneck Models"
1/ "DCBM: Data-Efficient Visual Concept Bottleneck Models" by @katharinaprasse.bsky.social*, @patrickknab.bsky.social*, Sascha Marton, Christian Bartelt, and @margretkeuper.bsky.social
🔍 Data-efficient CBMs (DCBMs) generate concepts from image regions detected by segmentation or detection models
13.07.2025 08:00 — 👍 1 🔁 0 💬 1 📌 0

Papers accepted at ICML 2025 from the Computer Vision and Machine Learning Department at the Max Planck Institute for Informatics.
Papers being presented from our group at #ICML2025!
Congratulations to all the authors! To know more, visit us in the poster sessions!
A 🧵with more details:
@icmlconf.bsky.social @mpi-inf.mpg.de
13.07.2025 08:00 — 👍 21 🔁 5 💬 2 📌 0

📣 Proceeding track's results are out.
🎉 Congratulations to all the authors whose papers were accepted. We can't wait to meet you at @iccv.bsky.social in Hawaii on Oct 19th.
⏰ Our non-proceeding track is still accepting submissions until July 20th! Details in the comments
12.07.2025 09:11 — 👍 7 🔁 2 💬 1 📌 1

🎉 Congrats to Yue Fan on defending his PhD: "Improving Representation Learning from Data and Model Perspectives: Semi-Supervised Learning and Foundation Models" 🧑🎓
He is now at Genmo.ai as a Research Engineer working on video generation! 🚀
More: yue-fan.github.io
All the best!
05.07.2025 20:47 — 👍 8 🔁 0 💬 1 📌 0
Congratulations to our PhD alumna @annakukleva.bsky.social for being awarded the prestigious Otto Hahn Medal by @maxplanck.de! 🎉
01.07.2025 21:44 — 👍 8 🔁 1 💬 0 📌 0
🚀 Just accepted to ICCV 2025!
In DIY-SC, we improve foundational features using a light-weight adapter trained with carefully filtered and refined pseudo-labels.
🔧 Drop-in alternative to plain DINOv2 features!
📦 Code + pre-trained weights available now.
🔥 Try it in your next vision project!
26.06.2025 14:28 — 👍 9 🔁 2 💬 1 📌 0
Submission deadline is today!
26.06.2025 11:03 — 👍 4 🔁 1 💬 0 📌 0
Submission Deadline is extended by 6 days.
#ICCV2025 @iccv.bsky.social
23.06.2025 12:14 — 👍 8 🔁 5 💬 0 📌 0
@mattiasegu.bsky.social
26.06.2025 09:55 — 👍 0 🔁 0 💬 0 📌 0

A heart congratulations to the freshly minted Dr. Mattia Segù on successfully defending his PhD, Congratulazioni!!! 🎉 🎓.
His thesis is titled: Learning to Track: From Limited Supervision to Long-range Sequence Modeling
Checkout his web-page to learn more about his work: mattiasegu.github.io
26.06.2025 09:55 — 👍 5 🔁 0 💬 2 📌 0

Call for papers at the eXCV workshop at ICCV 2025.
Join us in taking stock of the state of the field of explainability in computer vision, at our Workshop on Explainable Computer Vision: Quo Vadis? at #ICCV2025!
@iccv.bsky.social
14.06.2025 15:47 — 👍 13 🔁 5 💬 1 📌 1
At #CVPR2025 and working on consistency in video and multi-view generative models?
Come and visit our poster on Friday afternoon, where I present 𝗠𝗘𝘁𝟯𝗥: 𝗠𝗲𝗮𝘀𝘂𝗿𝗶𝗻𝗴 𝗠𝘂𝗹𝘁𝗶-𝗩𝗶𝗲𝘄 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 𝗶𝗻 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗲𝗱 𝗜𝗺𝗮𝗴𝗲𝘀
@mohammadasim98.bsky.social @wimmerthomas.bsky.social @mpi-inf.mpg.de @cvml.mpi-inf.mpg.de
12.06.2025 22:38 — 👍 17 🔁 1 💬 2 📌 0
7 / 🧵 ...
Workshop: Women in Computer Vision (WiCV)
📱 @sukrutrao.bsky.social @SwetaMahajan @MoritzBoehle
11.06.2025 20:44 — 👍 1 🔁 0 💬 0 📌 0
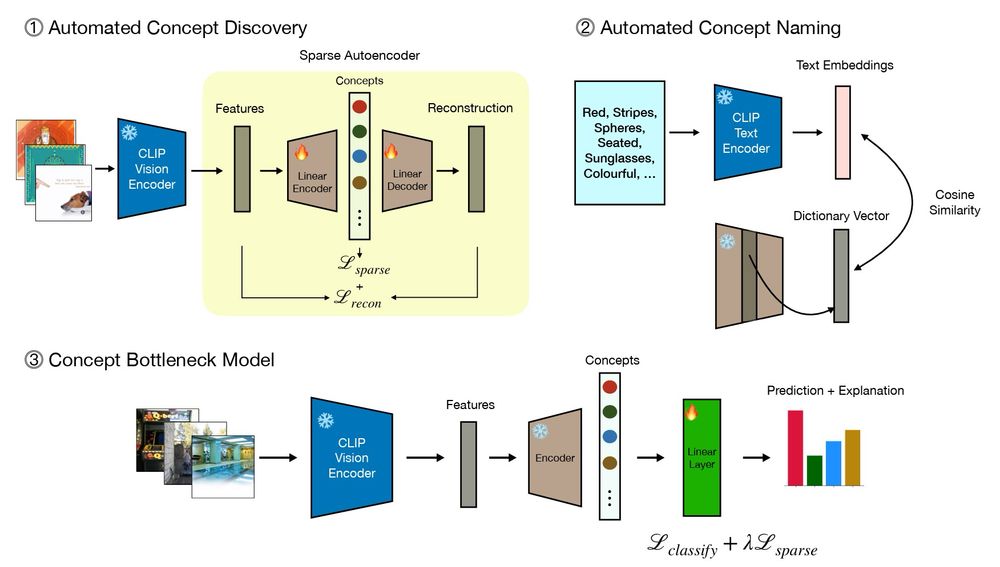
7/ 🧵 Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery
Authors: S. Rao, S. Mahajan, M. Böhle, B. Schiele
🔍 Explore sparse autoencoders to automatically extract and name concepts, enabling performance improvements on downstream tasks.
📚 arxiv.org/abs/2407.14499
11.06.2025 20:44 — 👍 2 🔁 1 💬 1 📌 0
6 / 🧵 ...
Workshop: Women in Computer Vision (WiCV)
📱 @tejaswinimedi.bsky.social @margretkeuper.bsky.social
11.06.2025 20:44 — 👍 3 🔁 1 💬 1 📌 0

6/ 🧵 3D-WAG: Wavelet-Guided Autoregressive Generation for 3D Shapes
Authors: T. Medi*, A. Rampini, P. Reddy, P. K. Jayaraman, M. Keuper
🔍 3D-WAG introduces wavelet-guided autoregressive generation for 3D shapes, aiming for better geometry modeling.
📚 arxiv.org/abs/2411.19037
11.06.2025 20:44 — 👍 3 🔁 1 💬 1 📌 0
5/ 🧵 ...
Workshop: Explainable AI for Computer Vision (XAI4CV)
📱 @katharinaprasse.bsky.social @smarton.bsky.social @margretkeuper.bsky.social
11.06.2025 20:44 — 👍 2 🔁 0 💬 1 📌 0
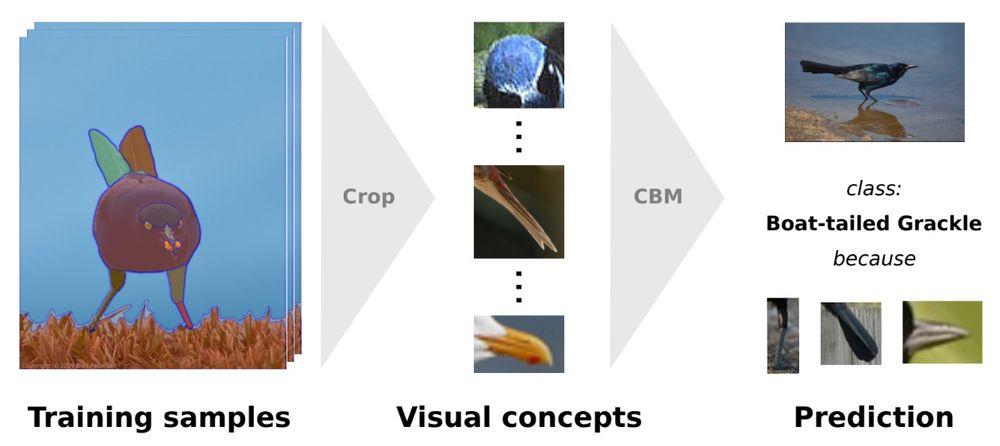
5/ 🧵 Data-Efficient Visual Concept Bottleneck Models
Authors: K. Prasse, P. Knab, S. Marton, C. Bartelt, M. Keuper
🔍 Introducing data-efficient visual concept bottleneck models for improved explainability in CV.
📚 arxiv.org/abs/2412.11576
11.06.2025 20:44 — 👍 2 🔁 0 💬 1 📌 0
4/ 🧵 ...
Workshops: What is Next in Multimodal Foundation Models? | Women in Computer Vision
📱 @maheensaleh.bsky.social @ninashv.bsky.social @annakukleva.bsky.social @hildekuehne.bsky.social
11.06.2025 20:44 — 👍 3 🔁 1 💬 1 📌 1

4/ 🧵 HD-VILA-Caption: A Diverse Video-Text Dataset Derived from ASR Narrations
By: M. Saleh, N. Shvetsova, A. Kukleva, H. Kuehne, B. Schiele
🔍 HD-VILA-Caption is a large-scale, diverse video-text dataset with 10M high-quality captions, built from ASR subtitles for video-language pretraining.
11.06.2025 20:44 — 👍 2 🔁 0 💬 1 📌 0
PhD Student in 3D Computer Vision at the University of Freiburg
https://pschroeppel.github.io/
ELLIS PhD @ MPI & Oxford - Generative Models for Vision
https://odunkel.github.io/
PhD student in explainable AI for computer vision @visinf.bsky.social @tuda.bsky.social - Prev. intern AWS and @maxplanck.de
The German Conference on Pattern Recognition (GCPR) is the annual symposium of the German Association for Pattern Recognition (DAGM). It is the national venue for recent advances in image processing, pattern recognition, and computer vision.
PhD student at the University of Tuebingen. Computer vision, video understanding, multimodal learning.
https://ninatu.github.io/
Institute for Explainable Machine Learning at @www.helmholtz-munich.de and Interpretable and Reliable Machine Learning group at Technical University of Munich and part of @munichcenterml.bsky.social
PhD in Computer Vision
Supervised and Inspired by Prof. Dr.-Ing Margret Keuper
Member of the Data & Web Science Group @ University of Mannheim.
PhD Candidate@Chair for Machine Learning, University of Mannheim.
Working on Machine Learning and Computer Vision.
Webpage: https://www.uni-mannheim.de/dws/people/researchers/phd-students/shashank/
Views are my own 😄
Liesel Beckmann Distinguished Professor of Computer Science at Technical University of Munich and Director of the Institute for Explainable ML at Helmholtz Munich
Professor of Computer Science at @tuda.bsky.social
Computer Vision & Machine Learning
Director @ZuseSchoolELIZA.bsky.social
Director @ellis.eu Unit Darmstadt
#ECCV2024 #CVPR2022 Program Chair
Strengthening Europe's Leadership in AI through Research Excellence | ellis.eu
International Conference on Learning Representations https://iclr.cc/
Official account for IEEE/CVF Conference on Computer Vision & Pattern Recognition. Hosted by @deblinaml @jbhaurum & @CSProfKGD
📍🌎 🔗 cvpr.thecvf.com 🎂 June 19, 1983
Official account for the IEEE/CVF International Conference on Computer Vision. #ICCV2025 Honolulu 🇺🇸 Co-hosted by @natanielruiz @antoninofurnari @yaelvinker @CSProfKGD
Official Account for the European Conference on Computer Vision (ECCV) #ECCV2026, Malmo 🇸🇪 Hosted by @jbhaurum and @CSProfKGD
The Thirty-Eighth Annual Conference on Neural Information Processing Systems will be held in Vancouver Convention Center, on Tuesday, Dec 10 through Sunday, Dec 15.
https://neurips.cc/
Professor for CS at the Tuebingen AI Center and affiliated Professor at MIT-IBM Watson AI lab - Multimodal learning and video understanding - GC for ICCV 2025 - https://hildekuehne.github.io/
PostDoc Tübingen AI Center | Machine Learning & Computer Vision
paulgavrikov.github.io
Research Group Leader at the Max Planck Institute for Informatics, Saarbrücken, Germany
https://people.mpi-inf.mpg.de/~mhaberma/






















