
Tracking the spookiest runs @weightsbiases.bsky.social
30.10.2025 08:42 — 👍 0 🔁 0 💬 0 📌 0
@paulgavrikov.bsky.social
PostDoc Tübingen AI Center | Machine Learning & Computer Vision paulgavrikov.github.io
Tracking the spookiest runs @weightsbiases.bsky.social
30.10.2025 08:42 — 👍 0 🔁 0 💬 0 📌 0The worst part about leaving academia is that you loose eduroam access :(
14.10.2025 15:00 — 👍 0 🔁 0 💬 1 📌 0Agree 100%! I think this paper does a great job of outlining issues in the original paper.
08.10.2025 19:43 — 👍 0 🔁 0 💬 0 📌 0If you think of texture as the material/surface property (which I think is the original perspective), then the ablation in this paper is insufficient to suppress the cue.
08.10.2025 16:43 — 👍 2 🔁 0 💬 1 📌 0I really liked the thoroughness of this paper but I’m afraid that the results are building on a shaky definition of „texture“. If you replace texture in the original paper with local details it’s virtually the same finding.
08.10.2025 16:43 — 👍 2 🔁 0 💬 1 📌 0lol, a #WACV AC just poorly rephrased the weaknesses I raised in my review as their justification and ignored all other reviews ... I feel bad for the authors ...
07.10.2025 16:00 — 👍 0 🔁 0 💬 0 📌 0See more details and try out your own model here:
paulgavrikov.github.io/visualoverlo...

4) Models answer consistently for easy questions ("Is it day?": yes, "Is it night?": no) but fall back to guessing for hard tasks such as reasoning. Concerningly, some models even fall below random chance, hinting at shortcuts.
01.10.2025 13:17 — 👍 0 🔁 0 💬 1 📌 0
3) Similar trends for OCR. Our OCR questions contain constraints (e.g., the fifth word) that models often fail to consider. Minor errors include a strong tendency to autocorrect typos or to hallucinate more common spellings, especially in non-Latin/English.
01.10.2025 13:17 — 👍 1 🔁 0 💬 1 📌 0
2) Models cannot count in dense scenes, and the performance gets worse the larger the number of objects; they typically "undercount" and errors are massive. Here is the distribution over all models:
01.10.2025 13:17 — 👍 0 🔁 0 💬 1 📌 01) Our benchmark is hard: the best model (o3) achieves an accuracy of 69.5% in total, but only 19.6% on the hardest split. We observe significant performance drops on some tasks.
01.10.2025 13:17 — 👍 0 🔁 0 💬 1 📌 0
Our questions are built on top of a fresh dataset of 150 high-resolution and detailed scenes probing core vision skills in 6 categories: counting, OCR, reasoning, activity/attribute/global scene recognition. The ground truth is private, and our eval server is live!
01.10.2025 13:17 — 👍 0 🔁 0 💬 1 📌 0
🚨 New paper out!
"VisualOverload: Probing Visual Understanding of VLMs in Really Dense Scenes"
👉 arxiv.org/abs/2509.25339
We test 37 VLMs on 2,700+ VQA questions about dense scenes.
Findings: even top models fumble badly—<20% on the hardest split and key failure modes in counting, OCR & consistency.

Paper out now: arxiv.org/abs/2509.25339
01.10.2025 12:45 — 👍 0 🔁 0 💬 0 📌 0Joint work with Wei Lin, Jehanzeb Mirza, Soumya Jahagirdar, Muhammad Huzaifa, Sivan Doveh, James Glass, and Hilde Kuehne.
08.09.2025 15:27 — 👍 0 🔁 0 💬 0 📌 0Paper coming soon! In the meantime:
• Try your model: huggingface.co/spaces/paulg...
• Dataset: huggingface.co/datasets/pau...
• Code: github.com/paulgavrikov...
🤖 We tested 37 models. Results?
Even top VLMs break down on “easy” tasks in overloaded scenes.
Best model (o3):
• 19.8% accuracy (hardest split)
• 69.5% overall
📊 VisualOverload =
• 2,720 Q–A pairs
• 6 vision tasks
• 150 fresh, high-res, royalty-free artworks
• Privately held ground-truth responses

Is basic image understanding solved in today’s SOTA VLMs? Not quite.
We present VisualOverload, a VQA benchmark testing simple vision skills (like counting & OCR) in dense scenes. Even the best model (o3) only scores 19.8% on our hardest split.


Congratulations to @paulgavrikov.bsky.social for an excellent PhD defense today!
08.07.2025 19:02 — 👍 3 🔁 2 💬 0 📌 0
Yesterday, I had the great honor of delivering a talk on feature biases in vision models at the VAL Lab at the Indian Institute of Science (IISc). I covered our ICLR 2025 paper and a few older works in the same realm.
youtu.be/9efpCs1ltcM
Paper: arxiv.org/abs/2403.09193
Code: github.com/paulgavrikov...
It was truly special reconnecting with old friends and making so many new ones. Beyond the conference halls, we had some unforgettable adventures — exploring the city, visiting the woodlands, and singing our hearts out at karaoke nights. 🎤🦁🌳
03.05.2025 10:02 — 👍 0 🔁 0 💬 1 📌 0


What an incredible week at #ICLR 2025! 🌟
I had an amazing time presenting our poster "Can We Talk Models Into Seeing the World Differently?" with
@jovitalukasik.bsky.social. Huge thanks to everyone who stopped by — your questions, insights, and conversations made it such a rewarding experience.
Looking forward to meet you!
24.04.2025 01:45 — 👍 1 🔁 0 💬 0 📌 0Today at 3pm - poster #328. See you there!
24.04.2025 01:45 — 👍 4 🔁 1 💬 0 📌 0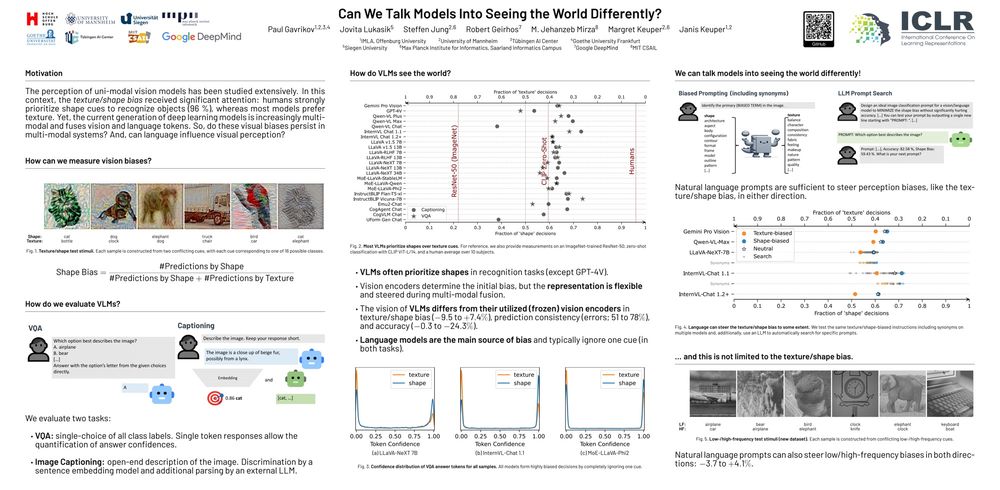
On Thursday, I'll be presenting our paper "Can We Talk Models Into Seeing the World Differently?" (#328) at ICLR 2025 in Singapore! If you're attending or just around Singapore, l'd love to connect—feel free to reach out! Also, I’m exploring postdoc or industry opportunities–happy to chat!
21.04.2025 10:47 — 👍 4 🔁 5 💬 1 📌 1Sorry for the late reply. Yes, I think you're right - it will only hold for normal convolutions. My bad!
17.02.2025 00:58 — 👍 1 🔁 0 💬 1 📌 0We should start boycotting proceedings that do not have a "cite this article" button.
01.02.2025 00:19 — 👍 0 🔁 0 💬 0 📌 0I should add that this ONLY works if there is no intermediate non-linearity - I think ConvNext is one of the few models where this holds.
27.01.2025 18:00 — 👍 2 🔁 0 💬 0 📌 0

















