Delighted Sasha's (first year PhD!) work using mech interp to study complex syntax constructions won an Outstanding Paper Award at EMNLP!
Also delighted the ACL community continues to recognize unabashedly linguistic topics like filler-gaps... and the huge potential for LMs to inform such topics!
07.11.2025 18:22 — 👍 33 🔁 8 💬 1 📌 0
UT Austin Computational Linguistics Research Group – Humans processing computers processing humans processing language
UT Austin Linguistics is hiring in computational linguistics!
Asst or Assoc.
We have a thriving group sites.utexas.edu/compling/ and a long proud history in the space. (For instance, fun fact, Jeff Elman was a UT Austin Linguistics Ph.D.)
faculty.utexas.edu/career/170793
🤘
07.10.2025 20:53 — 👍 41 🔁 27 💬 1 📌 4
Excited to present this at COLM tomorrow! (Tuesday, 11:00 AM poster session)
06.10.2025 15:21 — 👍 3 🔁 2 💬 0 📌 0
Heading to #COLM2025 to present my first paper w/ @jennhu.bsky.social @kmahowald.bsky.social !
When: Tuesday, 11 AM – 1 PM
Where: Poster #75
Happy to chat about my work and topics in computational linguistics & cogsci!
Also, I'm on the PhD application journey this cycle!
Paper info 👇:
06.10.2025 16:05 — 👍 7 🔁 3 💬 0 📌 0
I will be giving a short talk on this work at the COLM Interplay workshop on Friday (also to appear at EMNLP)!
Will be in Montreal all week and excited to chat about LM interpretability + its interaction with human cognition and ling theory.
06.10.2025 12:05 — 👍 8 🔁 5 💬 0 📌 0

Picture of the UT Tower with "UT Austin Computational Linguistics" written in bigger font, and "Humans processing computers processing human processing language" in smaller font
The compling group at UT Austin (sites.utexas.edu/compling/) is looking for PhD students!
Come join me, @kmahowald.bsky.social, and @jessyjli.bsky.social as we tackle interesting research questions at the intersection of ling, cogsci, and ai!
Some topics I am particularly interested in:
30.09.2025 16:17 — 👍 18 🔁 10 💬 3 📌 2
LMs’ dative alternation preferences come from both direct evidence and more general properties of language. They don’t just memorize–they generalize! See the paper for details on animacy too (interestingly more complicated!)
31.03.2025 13:30 — 👍 4 🔁 0 💬 1 📌 0
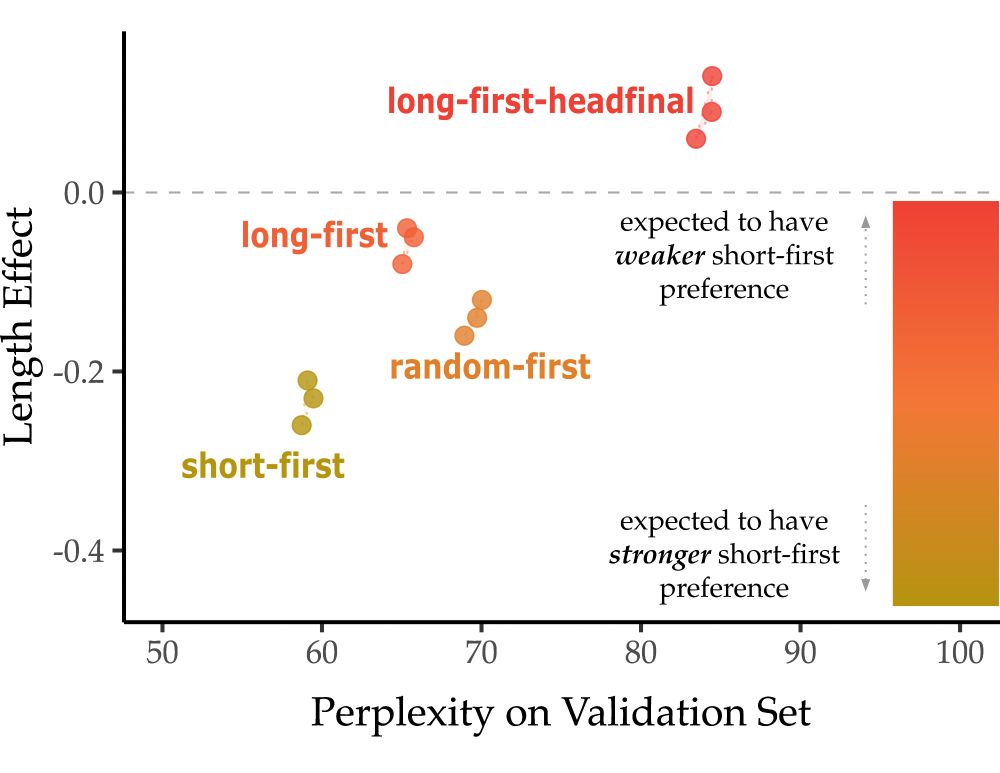
LMs' length preference vs. perplexity on validation set. We see that models whose training set manipulation reduces exposure to short-first orderings are the ones which have weaker short-first preference.
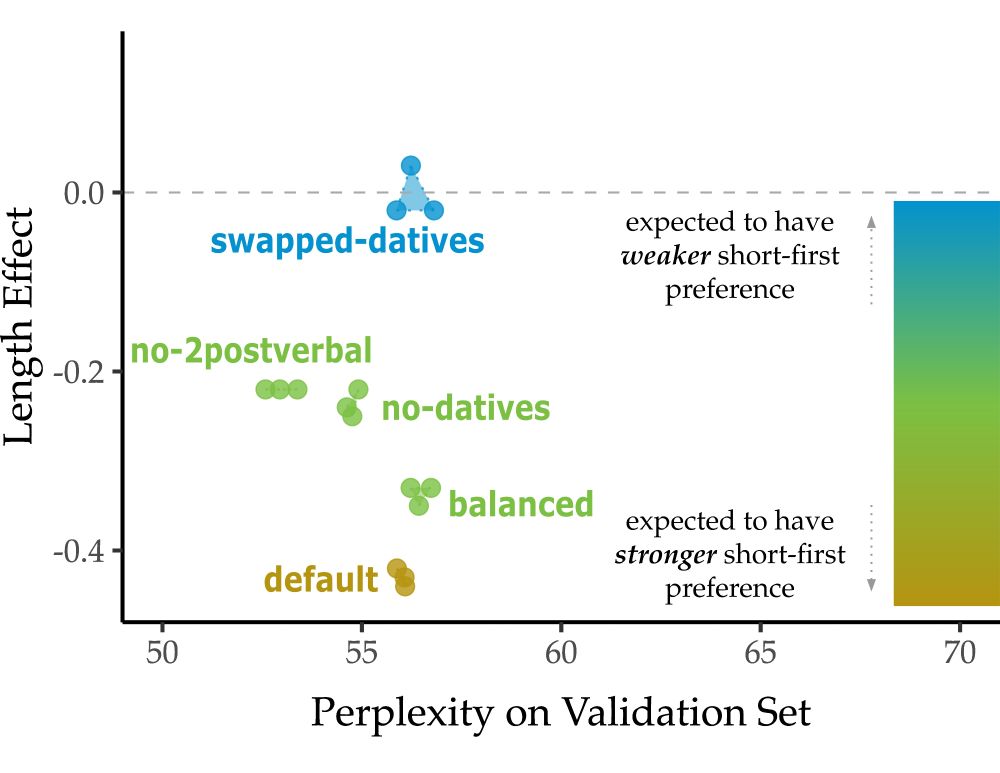
Learned length preference changes with the input manipulation. That is, the more “long-first” we make the input, the weaker the short-first preference. We think this shows the dative preferences in models come not just from datives but from general properties of English.
31.03.2025 13:30 — 👍 6 🔁 0 💬 1 📌 0
For example, “The primates use tools to eat the green coconuts from the shop” becomes:
-Short-first: [tools] use [the primates] [[to] eat [[the] [green] coconuts [from the shop]]]
-Long-first: [[[from the shop] [the] coconuts [green]] eat [to]] use [the primates] [tools]
31.03.2025 13:30 — 👍 2 🔁 0 💬 1 📌 0
We think it plausibly comes not from the datives alone but from general properties of English (which is “short-first”). To test that, we manipulate the global structure of the input, creating a corpus where every sentence is short-first and one where they’re all long-first.
31.03.2025 13:30 — 👍 3 🔁 0 💬 1 📌 0
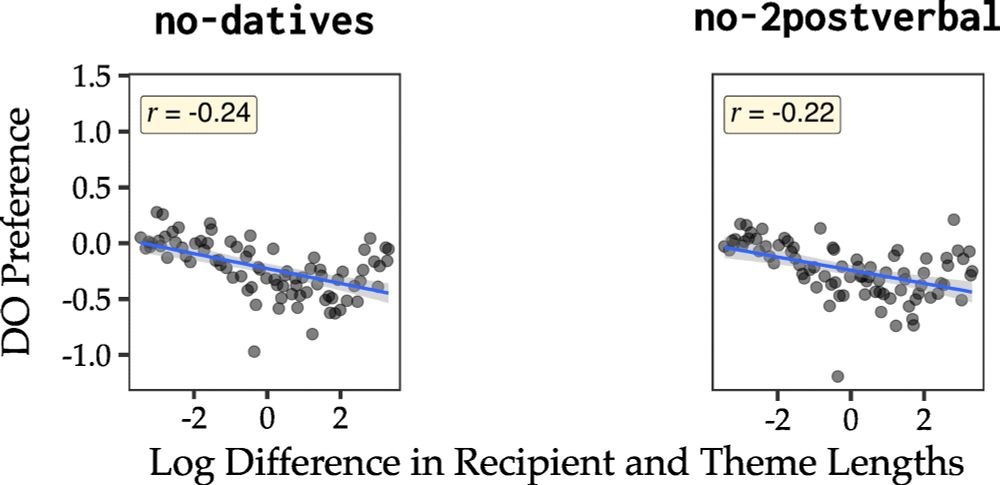
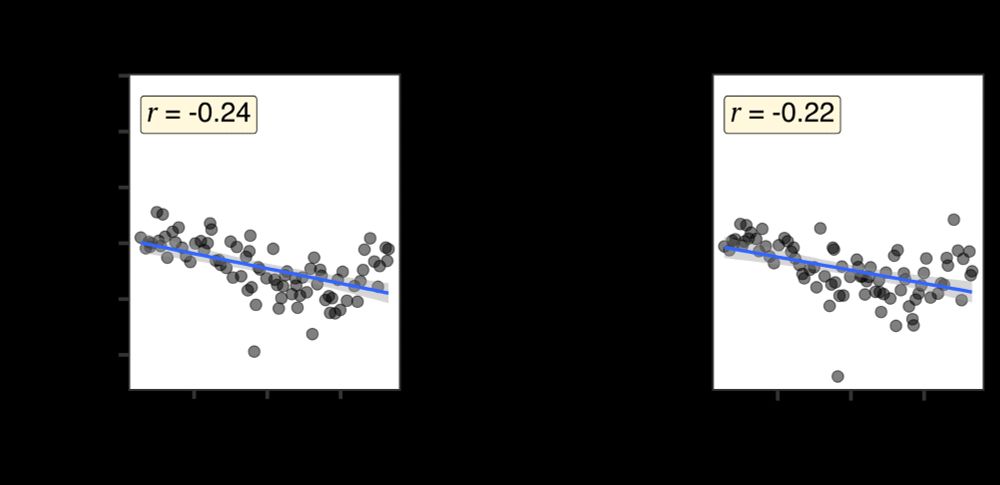
DO preference vs. length difference when we remove all datives (left) and all cases with 2 post-verbal arguments (right). The pearson correlation, r is now -0.24 for the no-datives condition, and -0.22 for no cases with 2postverbal arguments.
Now what if we get rid of datives, and further all constructions which have two postverbal arguments? Now we see the length preference is back again. Yes it’s smaller (direct evidence matters), but why is it there? Where does it come from if not the datives?
31.03.2025 13:30 — 👍 3 🔁 0 💬 1 📌 0
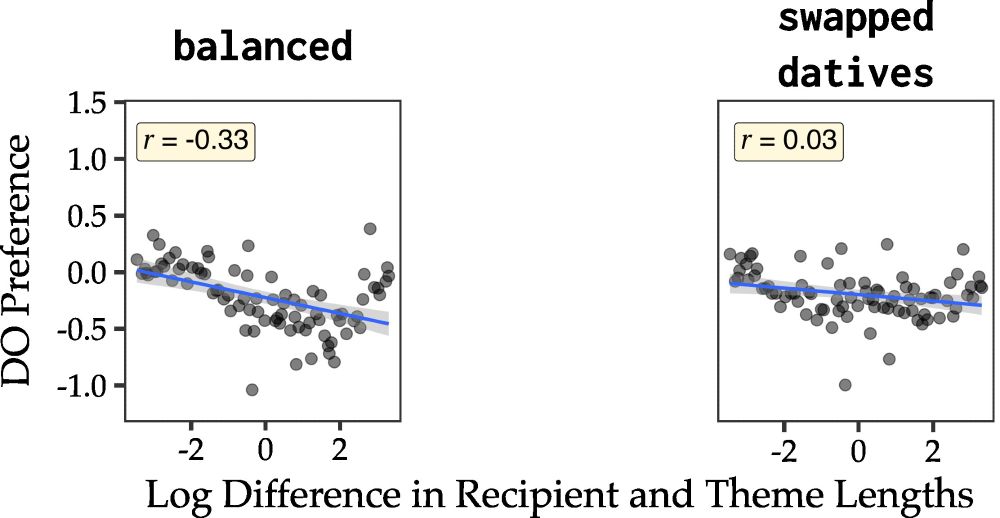
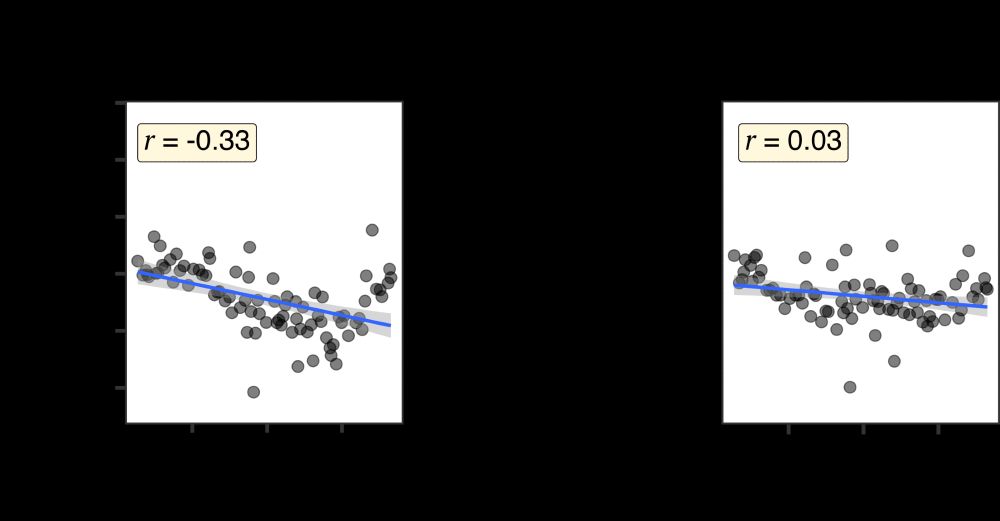
DO preference vs. length difference for the balanced and swapped-datives manipulations. Left: balanced, pearson correlation r = -0.33; right: swapped-datives, pearson correlation r = -0.03.
What if we modify the corpus such that for every DO there is a PO (balance direct evidence)? The preferences are still present! But what if now we SWAP every dative in the input so that every DO is now a PO, every PO a DO? The preference essentially disappears (but not flipped!)
31.03.2025 13:30 — 👍 2 🔁 0 💬 1 📌 0
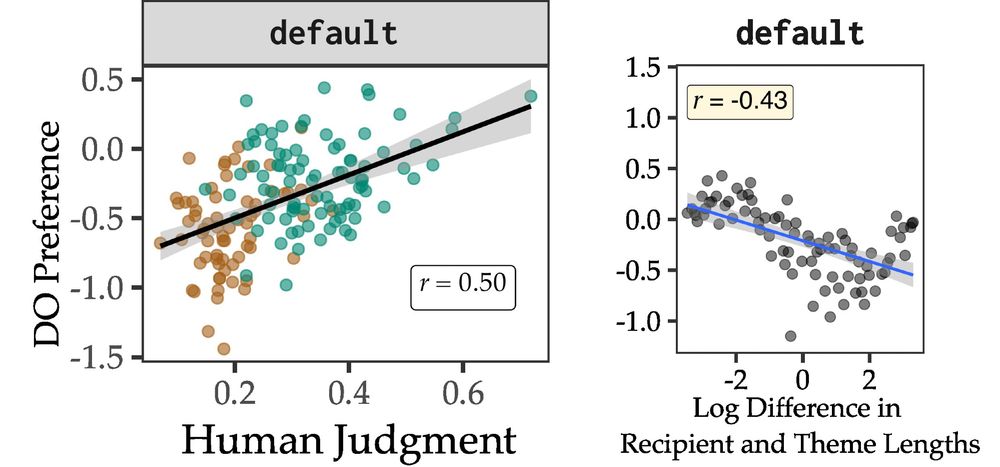
left: plot showing DO preference vs. Human Judgments – Pearson’s r = 0.5; right: plot showing the DO preference as a function of (log) length difference between the recipient and the theme, with pearson’s r = -0.43, where the negative sign indicates short-first is preferred
To test this, we train small LMs on manipulated datasets where we vary direct (datives) and indirect (non-datives) evidence and test the change in their preferences. First, we see that we get human-like preferences on a model trained on our default BabyLM corpus.
31.03.2025 13:30 — 👍 2 🔁 0 💬 1 📌 0
The English dative preferences come from more general features of the language: short constituents tend to appear earlier all over, not just in the dative. We hypothesize LMs rely on direct evidence from datives but also general word order preferences (e.g. “easy first”) from non-datives.
31.03.2025 13:30 — 👍 2 🔁 0 💬 1 📌 0

examples from direct and prepositional object datives with short-first and long-first word orders:
DO (long first): She gave the boy who signed up for class and was excited it.
PO (short first): She gave it to the boy who signed up for class and was excited.
DO (short first): She gave him the book that everyone was excited to read.
PO (long-first): She gave the book that everyone was excited to read to him.
LMs learn argument-based preferences for dative constructions (preferring recipient first when it’s shorter), consistent with humans. Is this from memorizing preferences in training? New paper w/ @kanishka.bsky.social , @weissweiler.bsky.social , @kmahowald.bsky.social
arxiv.org/abs/2503.20850
31.03.2025 13:30 — 👍 18 🔁 8 💬 1 📌 7
For example, “The primates use tools to eat the green coconuts from the shop” becomes:
- Short-first: [tools] use [the primates] [[to] eat [[the] [green] coconuts [from the shop]]]
- Long-first: [[[from the shop] [the] coconuts [green]] eat [to]] use [the primates] [tools]
31.03.2025 13:14 — 👍 0 🔁 0 💬 0 📌 0
We think it plausibly comes not from the datives alone but from general properties of English (which is “short-first”). To test that, we manipulate the global structure of the input, creating a corpus where every sentence is short-first and one where they’re all long-first.
31.03.2025 13:14 — 👍 0 🔁 0 💬 1 📌 0
DO preference vs. length difference when we remove all datives (left) and all cases with 2 post-verbal arguments (right). The pearson correlation, r is now -0.24 for the no-datives condition, and -0.22 for no cases with 2postverbal arguments.
Now what if we get rid of datives, and further all constructions which have two postverbal arguments? Now we see the length preference is back again. Yes it’s smaller (direct evidence matters), but why is it there? Where does it come from if not the datives?
31.03.2025 13:14 — 👍 0 🔁 0 💬 1 📌 0
DO preference vs. length difference for the balanced and swapped-datives manipulations. Left: balanced, pearson correlation r = -0.33; right: swapped-datives, pearson correlation r = -0.03.
What if we modify the corpus such that for every DO there is a PO (balance direct evidence)? The preferences are still present! But what if now we SWAP every dative in the input so that every DO is now a PO, every PO a DO? The preference essentially disappears (but not flipped!)
31.03.2025 13:14 — 👍 0 🔁 0 💬 1 📌 0
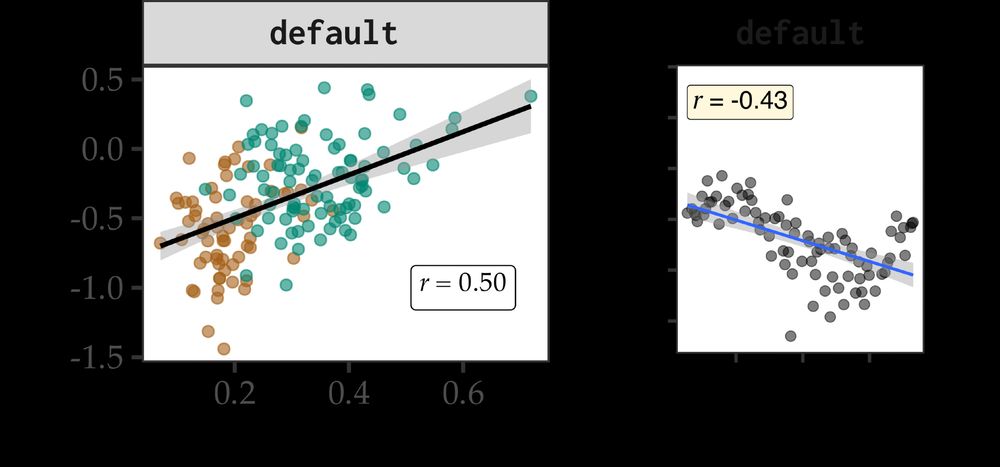
left: plot showing DO preference vs. Human Judgments – Pearson’s r = 0.5; right: plot showing the DO preference as a function of (log) length difference between the recipient and the theme, with pearson’s r = -0.43, where the negative sign indicates short-first is preferred
To test this, we train small LMs on manipulated datasets where we vary direct (datives) and indirect (non-datives) evidence and test the change in their preferences. First, we see that we get human-like preferences on a model trained on our default BabyLM corpus.
31.03.2025 13:14 — 👍 0 🔁 0 💬 1 📌 0
The English dative preferences come from more general features of the language: short constituents tend to appear earlier all over, not just in the dative. We hypothesize LMs rely on direct evidence from datives but also general word order preferences (e.g. “easy first”) from non-datives.
31.03.2025 13:14 — 👍 0 🔁 0 💬 1 📌 0
https://najoung.kim
langauge
Linguist who posts about languages 🙌 science 🧬 doggos 🐕 plants 🌱 the enviroment ♻️ music 🎶 disability justice ♿️ and politics 🆘️
Language and thought in brains and in machines. Assistant Prof @ Georgia Tech Psychology. Previously a postdoc @ MIT Quest for Intelligence, PhD @ MIT Brain and Cognitive Sciences. She/her
https://www.language-intelligence-thought.net
Neuro + ML + NLP
Postdoc@Chang Lab, UCSF | Prev.: PhD@Huth Lab, UT Austin
https://shaileesjain.github.io
she/her
🧠🤖💬
Interpretable Deep Networks. http://baulab.info/ @davidbau
PhD student doing LLM interpretability with @davidbau.bsky.social and @byron.bsky.social. (they/them) https://sfeucht.github.io
Assoc. Professor at UC Berkeley
Artificial and biological intelligence and language
Linguistics Lead at Project CETI 🐳
PI Berkeley Biological and Artificial Language Lab 🗣️
College Principal of Bowles Hall 🏰
https://www.gasperbegus.com
Asst Prof at Johns Hopkins Cognitive Science • Director of the Group for Language and Intelligence (GLINT) ✨• Interested in all things language, cognition, and AI
jennhu.github.io
Postdoc at ETH. Formerly, PhD student at the University of Cambridge :)
linguist, experimental work on meaning (lexical semantics), language use, representation, learning, constructionist usage-based approach, Princeton U https://adele.scholar.princeton.edu/publications/topic
Official feed of UCSB linguistics: https://www.linguistics.ucsb.edu/
2nd year PhD Student at @gronlp.bsky.social 🐮 - University of Groningen
Language Acquisition - NLP
He teaches information science at Cornell. http://mimno.infosci.cornell.edu
Linguaphile, data nerd, 🧠 geek. Subrident problem solving and forays into affective neurolinguistics. 🏃♀️
🥇 LLMs together (co-created model merging, BabyLM, textArena.ai)
🥈 Spreading science over hype in #ML & #NLP
Proud shareLM💬 Donor
@IBMResearch & @MIT_CSAIL
computational cognitive science he/him
UC Berkeley
ScienceHomecoming
http://colala.berkeley.edu/people/piantadosi/
Father, Professor and Chair of Linguistics at The University of Texas at Austin, Editor of Language, a journal of the Linguistic Society of America, syntactician, semanticist, guitarist, politics junkie (he/him/his)
Professor of philosophy UTAustin. Philosophical logic, formal epistemology, philosophy of language, Wang Yangming.
www.harveylederman.com
Philosopher at UT Austin who thinks about art, ethics, value. Dog dad. 🏳️🌈 https://robbiekubala.com





















