Thrilled to share my first paper! 📄
We prove optimal tokenization is NP-hard on bounded alphabets (like bytes)—even unary for direct tokenization!
Big thanks @tpimentel.bsky.social, @philipwitti.bsky.social & Dennis Komm for the mentorship! Best birthday gift. 🎂
arxiv.org/abs/2511.15709
20.11.2025 15:27 — 👍 6 🔁 1 💬 0 📌 0

Tokenisation over Bounded Alphabets is Hard
Recent works have shown that tokenisation is NP-complete. However, these works assume tokenisation is applied to inputs with unboundedly large alphabets -- an unrealistic assumption, given that in pra...
This was joint work with @vkastreva.bsky.social, @philipwitti.bsky.social, D. Komm! Violeta is a super smart student, who is definitely gonna do lots more interesting work :) It's her first paper, and it's also her birthday today 🥳 so follow her if you like this!
Paper: arxiv.org/abs/2511.15709
20.11.2025 15:05 — 👍 3 🔁 0 💬 1 📌 0
More precisely, we show that: (i) for binary alphabets, not only finding an optimal tokeniser is NP-hard, but also finding arbitrarily good approximations; (ii) for unary alphabets, finding an optimal direct tokeniser is NP-hard!
20.11.2025 15:05 — 👍 2 🔁 0 💬 1 📌 0

Screenshot of paper title: Tokenisation over Bounded Alphabets is Hard.
Tokenisers are a vital part of LLMs, but how hard is it to find an optimal one? 🤔 Considering arbitrarily large alphabets, prior work showed this is NP-hard. But what if we use bytes instead? Or unary strings like a, aa, aaa, ...? In our new paper, we show this is still hard, NP-hard!
20.11.2025 15:05 — 👍 16 🔁 3 💬 1 📌 1

Theory of XAI Workshop
Explainable AI (XAI) is now deployed across a wide range of settings, including high-stakes domains in which misleading explanations can cause real harm. For example, explanations are required by law ...
Interested in provable guarantees and fundamental limitations of XAI? Join us at the "Theory of Explainable AI" workshop Dec 2 in Copenhagen! @ellis.eu @euripsconf.bsky.social
Speakers: @jessicahullman.bsky.social @doloresromerom.bsky.social @tpimentel.bsky.social
Call for Contributions: Oct 15
07.10.2025 12:53 — 👍 8 🔁 5 💬 0 📌 2

Paper title: Language models align with brain regions that represent concepts across modalities.
Authors: Maria Ryskina, Greta Tuckute, Alexander Fung, Ashley Malkin, Evelina Fedorenko.
Affiliations: Maria is affiliated with the Vector Institute for AI, but the work was done at MIT. All other authors are affiliated with MIT.
Email address: maria.ryskina@vectorinstitute.ai.
Interested in language models, brains, and concepts? Check out our COLM 2025 🔦 Spotlight paper!
(And if you’re at COLM, come hear about it on Tuesday – sessions Spotlight 2 & Poster 2)!
04.10.2025 02:15 — 👍 26 🔁 5 💬 1 📌 1
Accepted to EMNLP (and more to come 👀)! The camera ready version is now online---very happy with how this turned out
arxiv.org/abs/2507.01234
24.09.2025 15:21 — 👍 14 🔁 5 💬 0 📌 0
See our paper for more: we have analyses on other models, downstream tasks, and considering only subsets of tokens (e.g., only tokens with a certain part-of-speech)!
01.10.2025 18:08 — 👍 0 🔁 0 💬 1 📌 0
This means that: (1) LMs can get less similar to each other, even while they all get closer to the true distribution; and (2) larger models reconverge faster, while small ones may never reconverge.
01.10.2025 18:08 — 👍 0 🔁 0 💬 1 📌 0
* A sharp-divergence phase, where models diverge as they start using context.
* A slow-reconvergence phase, where predictions slowly become more similar again (especially in larger models).
01.10.2025 18:08 — 👍 0 🔁 0 💬 1 📌 0
Surprisingly, convergence isn’t monotonic. Instead, we find four convergence phases across model training.
* A uniform phase, where all seeds output nearly-uniform distributions.
* A sharp-convergence phase, where models align, largely due to unigram frequency learning.
01.10.2025 18:08 — 👍 0 🔁 0 💬 1 📌 0
In this paper, we define convergence as the similarity between outputs of LMs trained under different seeds, where similarity is measured as a per-token KL divergence. This lets us track whether models trained under identical settings, but different seeds, behave the same.
01.10.2025 18:08 — 👍 0 🔁 0 💬 1 📌 0

Figure showing the four phases of convergence in LM training
LLMs are trained to mimic a “true” distribution—their reducing cross-entropy then confirms they get closer to this target while training. Do similar models approach this target distribution in similar ways, though? 🤔 Not really! Our new paper studies this, finding 4-convergence phases in training 🧵
01.10.2025 18:08 — 👍 24 🔁 4 💬 1 📌 1
Very happy this paper got accepted to NeurIPS 2025 as a Spotlight! 😁
Main takeaway: In mechanistic interpretability, we need assumptions about how DNNs encode concepts in their representations (eg, the linear representation hypothesis). Without them, we can claim any DNN implements any algorithm!
01.10.2025 15:00 — 👍 25 🔁 4 💬 0 📌 0
Honoured to receive two (!!) SAC highlights awards at #ACL2025 😁 (Conveniently placed on the same slide!)
With the amazing: @philipwitti.bsky.social, @gregorbachmann.bsky.social and @wegotlieb.bsky.social,
@cuiding.bsky.social, Giovanni Acampa, @alexwarstadt.bsky.social, @tamaregev.bsky.social
31.07.2025 07:41 — 👍 22 🔁 3 💬 0 📌 0
We are presenting this paper at #ACL2025 😁 Find us at poster session 4 (Wednesday morning, 11h~12h30) to learn more about tokenisation bias!
27.07.2025 11:59 — 👍 11 🔁 2 💬 0 📌 0
@philipwitti.bsky.social will be presenting our paper "Tokenisation is NP-Complete" at #ACL2025 😁 Come to the language modelling 2 session (Wednesday morning, 9h~10h30) to learn more about how challenging tokenisation can be!
27.07.2025 09:41 — 👍 7 🔁 3 💬 0 📌 0
Headed to Vienna for #ACL2025 to present our tokenisation bias paper and co-organise the L2M2 workshop on memorisation in language models. Reach out to chat about tokenisation, memorisation, and all things pre-training (esp. data-related topics)!
27.07.2025 06:40 — 👍 20 🔁 2 💬 2 📌 0

Causal Abstraction, the theory behind DAS, tests if a network realizes a given algorithm. We show (w/ @denissutter.bsky.social, T. Hofmann, @tpimentel.bsky.social ) that the theory collapses without the linear representation hypothesis—a problem we call the non-linear representation dilemma.
17.07.2025 10:57 — 👍 5 🔁 2 💬 1 📌 0
Importantly, despite these results, we still believe causal abstraction is one of the best frameworks available for mech interpretability. Going forward, we should try to better understand how it is impacted by assumptions about how DNNs encode information. Longer🧵soon by @denissutter.bsky.social
14.07.2025 12:15 — 👍 4 🔁 0 💬 0 📌 0
Overall, our results show that causal abstraction (and interventions) is not a silver bullet, as it relies on assumptions about how features are encoded in the DNNs. We then connect our results to the linear representation hypothesis and to older debates in the probing literature.
14.07.2025 12:15 — 👍 2 🔁 0 💬 1 📌 0
We show—both theoretically (under reasonable assumptions) and empirically (on real-world models)—that, if we allow variables to be encoded in arbitrarily complex subspaces of the DNN’s representations, any algorithm can be mapped to any model.
14.07.2025 12:15 — 👍 1 🔁 0 💬 1 📌 0
Causal abstraction identifies this correspondence by finding subspaces in the DNN's hidden states which encode the algorithm’s hidden variables. Given such a map, we say the DNN implements the algorithm if the two behave identically under interventions.
14.07.2025 12:15 — 👍 0 🔁 0 💬 1 📌 0

Paper title "The Non-Linear Representation Dilemma: Is Causal Abstraction Enough for Mechanistic Interpretability?" with the paper's graphical abstract showing how more powerful alignment maps between a DNN and an algorithm allow more complex features to be found and more "accurate" abstractions.
Mechanistic interpretability often relies on *interventions* to study how DNNs work. Are these interventions enough to guarantee the features we find are not spurious? No!⚠️ In our new paper, we show many mech int methods implicitly rely on the linear representation hypothesis🧵
14.07.2025 12:15 — 👍 66 🔁 12 💬 1 📌 1
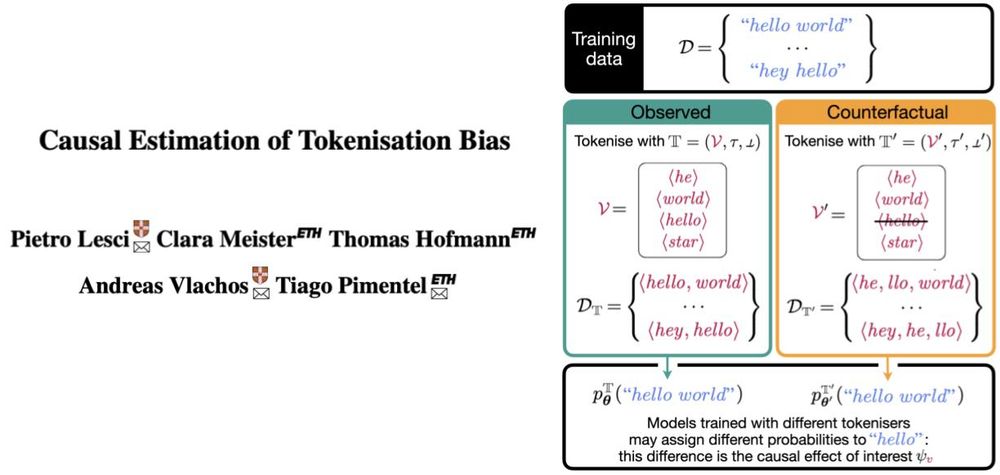
All modern LLMs run on top of a tokeniser, an often overlooked “preprocessing detail”. But what if that tokeniser systematically affects model behaviour? We call this tokenisation bias.
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
05.06.2025 10:43 — 👍 63 🔁 8 💬 1 📌 2
The word "laundry" contains both steps of the laundry process:
1. Undry
2. Dry
04.06.2025 19:14 — 👍 26 🔁 2 💬 1 📌 0
Love this! Especially the explicit operationalization of what “bias” they are measuring via specifying the relevant counterfactual.
Definitely an approach that more papers talking about effects can incorporate to better clarify what the phenomenon they are studying.
04.06.2025 15:55 — 👍 2 🔁 1 💬 0 📌 0
If you use LLMs, tokenisation bias probably affects you:
* Text generation: tokenisation bias ⇒ length bias 🤯
* Psycholinguistics: tokenisation bias ⇒ systematically biased surprisal estimates 🫠
* Interpretability: tokenisation bias ⇒ biased logits 🤔
04.06.2025 14:55 — 👍 7 🔁 0 💬 0 📌 1
Research Intern at ETH Zürich
Professor in Operations Research at Copenhagen Business School. In ❤️ with Sevilla and its Real Betis Balompié.
Ginni Rometty Prof @NorthwesternCS | Fellow @NU_IPR | AI, people, uncertainty, beliefs, decisions, metascience | Blog @statmodeling
Strengthening Europe's Leadership in AI through Research Excellence | ellis.eu
EurIPS is a community-organized, NeurIPS-endorsed conference in Copenhagen where you can present papers accepted at @neuripsconf.bsky.social
eurips.cc
PostDoc @ Uni Tübingen
explainable AI, causality
gunnarkoenig.com
Postdoc @vectorinstitute.ai | organizer @queerinai.com | previously MIT, CMU LTI | 🐀 rodent enthusiast | she/they
🌐 https://ryskina.github.io/
Helping machines make sense of the world. Asst Prof @icepfl.bsky.social; Before: @stanfordnlp.bsky.social @uwnlp.bsky.social AI2 #NLProc #AI
Website: https://atcbosselut.github.io/
Msc at @eth interested in ML interpretability
Assistant Professor in NLP (Fairness, Interpretability and lately interested in Political Science) at the University of Copenhagen ✨
Before: PostDoc in NLP at Uni of CPH, PhD student in ML at TU Berlin
Postdoc at Utrecht University, previously PhD candidate at the University of Amsterdam
Multimodal NLP, Vision and Language, Cognitively Inspired NLP
https://ecekt.github.io/
The largest workshop on analysing and interpreting neural networks for NLP.
BlackboxNLP will be held at EMNLP 2025 in Suzhou, China
blackboxnlp.github.io
PhD student in NLP at ETH Zurich.
anejsvete.github.io
language model pretraining @ai2.bsky.social, co-lead of data research w/ @soldaini.net, statistics @uw, open science, tabletop, seattle, he/him,🧋 kyleclo.com
Posting about research fby and events and news relevant for the Amsterdam NLP community. Account maintained by @wzuidema@bsky.social
MIT Brain and Cognitive Sciences
Postdoc researcher @ Fedorenko lab, MIT. Cognitive neuroscience of language and speech.
Asst Prof. @ UCSD | PI of LeM🍋N Lab | Former Postdoc at ETH Zürich, PhD @ NYU | computational linguistics, NLProc, CogSci, pragmatics | he/him 🏳️🌈
alexwarstadt.github.io
Assistant professor in NLP @UniMelb





















