
Updated link: hyperplane.gumroad.com/l/fine-tunin...
06.05.2025 15:00 — 👍 0 🔁 0 💬 0 📌 0
@hyperplane.bsky.social
Your weekly read. From POC to Production, at scale. 🫵 Follow our substack: https://mlvanguards.substack.com/ 👀 Our Ebook: https://hyperplane.gumroad.com/l/fine-tuning-stt-on-edge
Updated link: hyperplane.gumroad.com/l/fine-tunin...
06.05.2025 15:00 — 👍 0 🔁 0 💬 0 📌 0
Finally made it! It’s been a long ride, but the first real STT guide for kids’ voices on edge devices is here. Check it out on Gumroad if you're curious!
the link for the book mlvanguards.gumroad.com/l/fine-tunin... (it's free)
Without observability, agents are just black boxes making guesses.
With the right tools, they become transparent, testable, improvable systems.
Agentic systems are only as useful as their debug-ability.
MLOps is more than just tools.
Reproducibility, scalability, and observability are a must. Just setting up Kubeflow or MLflow doesn’t make you an MLOps expert.

Launching tomorrow for all subscribers:
open.substack.com/pub/mlvangua...
Raw audio is unpredictable.
Training is expensive.
Inference is a balancing act.
Deployment is… well, never as simple as pip install.
Everyone’s hyped about LLMs and edge deployments, but few talk about what it actually takes to it to production.
So we wrote the guide we wish we had.
Real MLOps doesn’t happen in 1 day or 1 week. Knowing how to use different tools doesn’t make you an MLOps expert.
It takes time to understand the whole process, and it takes time to learn how to have arguments to convince the management, the CEO, or other stakeholders.

🚨 Alert: This article is dangerously true!
mlvanguards.substack.com/p/the-malpra...
Still better than no boat at all!
In all realness, code generation is a great assistant for an already great programmer 🤷

How does GraphRAG work? What are its advantages over other RAG?
Let's return to Michael Hunger's blog post in which he demonstrates its practical application using a hashtag#Neo4j example!
Happy weekend reading!
bit.ly/4f8wLVp
hashtag#knowledgegraphs

We show more in the upcoming eBook, free for all subscribers: mlvanguards.substack.com
26.03.2025 10:55 — 👍 0 🔁 0 💬 0 📌 0- Normalize & clean transcripts (remove garbage text, repeated words, weird artifacts)
- Filter out the junk
- Split (70/15/15) & push to @hf.co for easy access during training
2/2
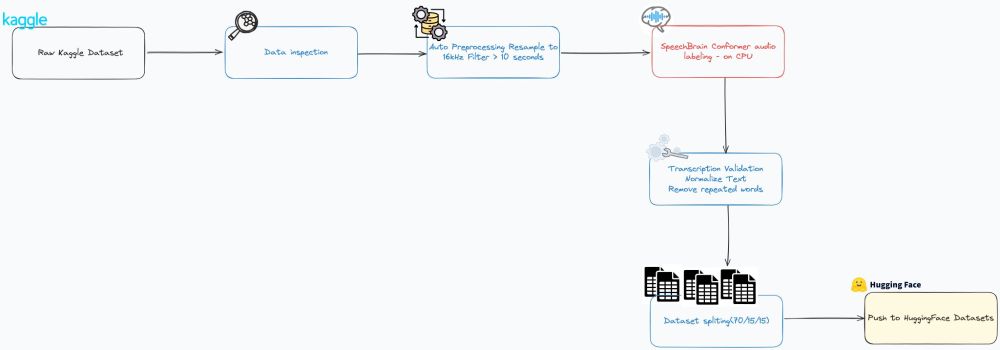
In less than 24 hours, we turned 5K messy files (from @kaggle.com) into a clean dataset of ~3.9K audio+transcription pairs.
Here’s how:
- Resample & filter (standardize to 16kHz, cut long/empty clips)
- Auto-transcribe with SpeechBrain (ran it on CPU — I'm GPU poor 😅)
1/2
In the last 2 years, prompt engineering has been treated as an afterthought, a means to an end.
But in reality, a prompt is the most crucial hyperparameter of any GenAI system. Its design can make or break the output quality, much like tuning a model's parameters determines its performance.
It's kinda free for all newsletter subscribers: mlvanguards.substack.com
24.03.2025 20:43 — 👍 0 🔁 0 💬 0 📌 0
We're launching an ebook on 28th this week 😳
Regular speech-to-text tech struggles with kids’ voices since they’re higher-pitched and less predictable.
We worked on that by creating a smaller, more accurate model that works well with children’s speech, even in noisy or low-power settings.
Read more here: mlvanguards.substack.com/p/data-is-bo...
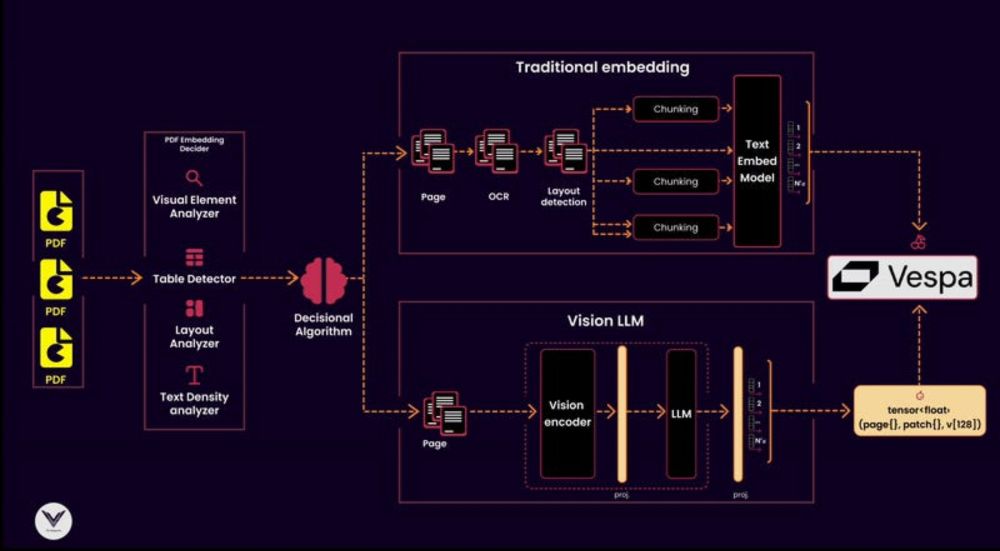
24.03.2025 12:18 — 👍 0 🔁 0 💬 0 📌 06. Vector Database
A vector database like Vespa store sembeddings and enable allowing similarity searches. They also use metadata to improve relevance by associating vectors with key attributes like document type, page number, or detected visual features.
7/7
5. Chunking Strategy
Splits documents into manageable chunks for embedding:
- Layout-based chunking is for visual embeddings.
- Text density and structure for traditional embeddings. This preserving context without overloading the vector database
6/7
4. Embedding Models
For converting document content into vectors.
- Traditional embeddings for documents with clean text extracted via OCR.
- Vision Language Models (VLM) handle multimodal documents with complex visual structures like tables, charts, and diagrams.
5/7
3. Decisional Algorithm
The algorithm is centralized, making informed decisions based on input from the embedding decider.
- Text-heavy documents are processed with OCR and text embedding models.
- Documents with complex layouts use visual language models (eg ColPali) instead, skipping OCR.
4/7
2. PDF Embedding Decider
This decider analyzes the document's structure, using tools like a layout analyzer, visual element detector, or text density analyzer, to classify whether a traditional text embedding or a multimodal vision embedding is appropriate.
3/7
1. PDF Reader
The starting point of any pipeline is the PDF reader. Its job is to extract pages and pass them downstream. A high-quality reader ensures no lost information, whether the content is text-heavy, image-dense, or filled with tables and graphs.
2/7
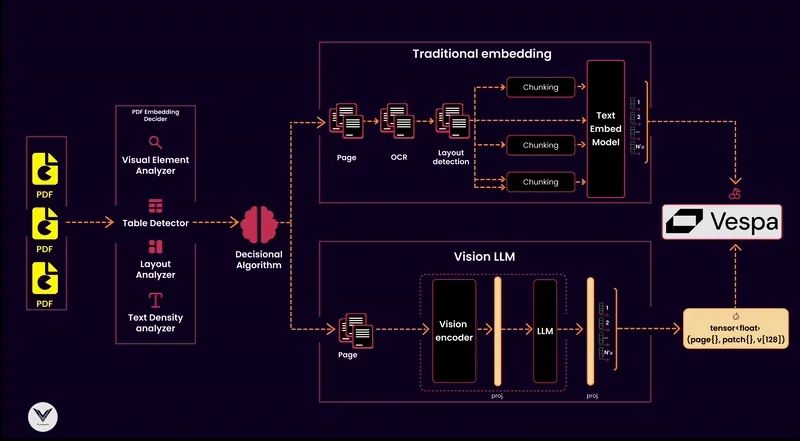
The principles of an indexing pipeline:
1/7
Not all PDFs are created equally. Some PDFs are beautifully structured with clean text, while others are chaotic with dense layouts, tables, or images.
Ignoring these differences means risking ineffective indexing and poor search retrieval.
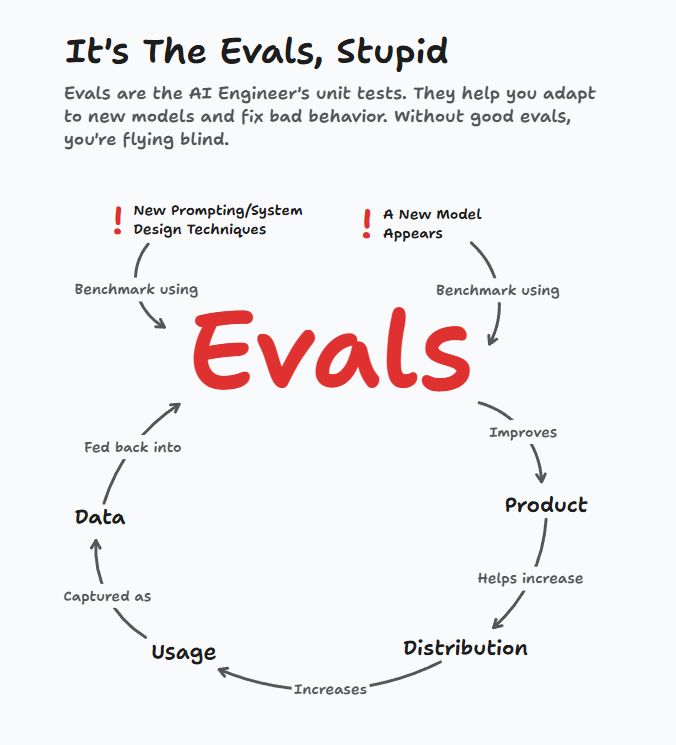
It's the evals, stupid
21.03.2025 11:32 — 👍 27 🔁 1 💬 3 📌 2AI can pretty much do anything, but it lacks that human creativity. Do you prefer quick tasks done or creativity?
#AI #Question
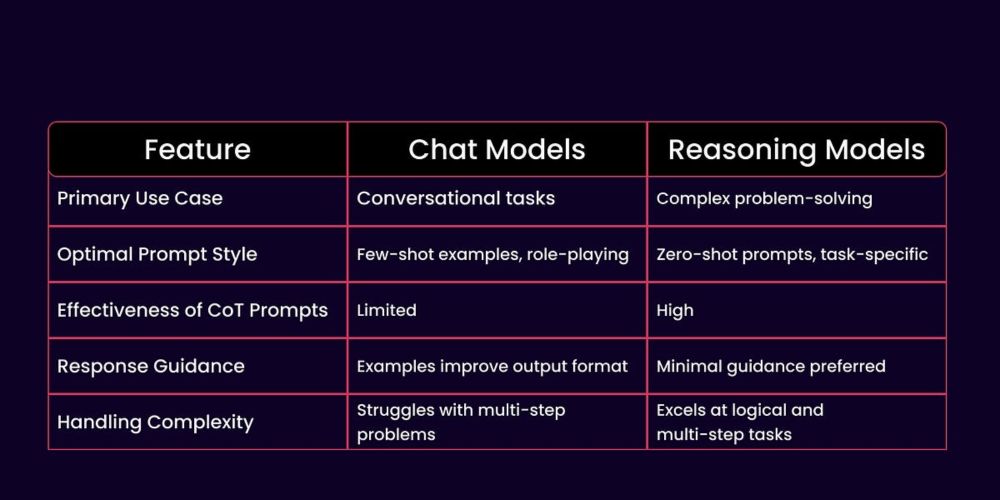
Dspy fixes this. It treats LLMs like actual programmable components instead of "hope this works" spells
signatures, modules, optimizers, whatever, read the thing if you care
we have a new article about it. with code
mlvanguards.substack.com/p/prompts-ar...
"prompt engineering" is just fancy copy-pasting at this point
people tweaking prompts like they're adjusting a car mirror, thinking it'll make them drive better
you’re optimizing nothing, you’re just guessing
It's easy to over use DRY which slooows you down as a dev. Some code bits can be repeated because the end goal is to have maintainable and readable code, and not just unique lines of code
24.02.2025 08:43 — 👍 0 🔁 0 💬 0 📌 0


















