Mind = blown 🤯
www.nature.com/articles/d41...

@int8.tech.bsky.social
Ph.D. in Neuroimaging | AI/Computer Vision Researcher | Making training and inference more efficient | 🇲🇫 CTO & Startup Founder | Linux Aficionado
Mind = blown 🤯
www.nature.com/articles/d41...

'The limits of my language means the limits of my world' — Wittgenstein.
New blog post reading the hype around scaling LLMs to reach AGI through the lens of anthropology, philosophy, and cognition.
int8.tech/posts/rethin...
Awesome! I'm in 🥳
21.03.2025 08:47 — 👍 0 🔁 0 💬 0 📌 0Is it possible to come even if we are not going to CVPR?
21.03.2025 08:27 — 👍 4 🔁 0 💬 1 📌 0

🔥🔥🔥 CV Folks, I have some news! We're organizing a 1-day meeting in center Paris on June 6th before CVPR called CVPR@Paris (similar as NeurIPS@Paris) 🥐🍾🥖🍷
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!

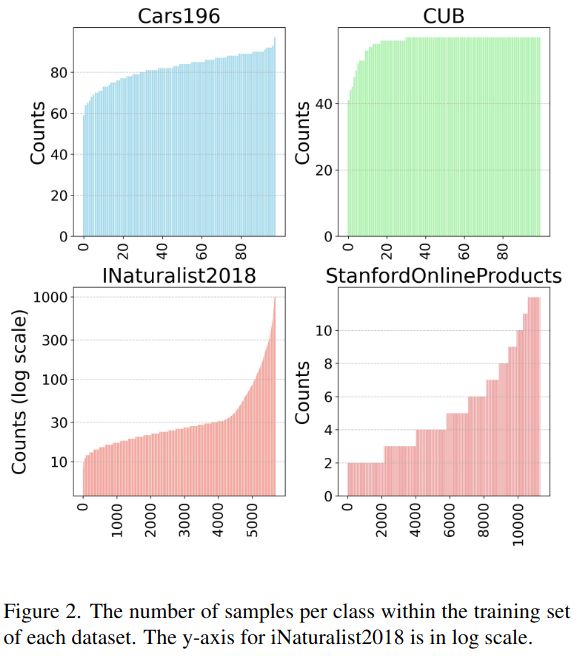
🚀 Paper Release! 🚀
Curious about image retrieval and contrastive learning? We present:
📄 "All You Need to Know About Training Image Retrieval Models"
🔍 The most comprehensive retrieval benchmark—thousands of experiments across 4 datasets, dozens of losses, batch sizes, LRs, data labeling, and more!

Following the release of DeepMind's TIPS model, I added support for text embeddings in Equimo. Just a few lines of code to embed text and images in the same space, enabling easy vision-language workflows in Jax.
Learn more at: github.com/clementpoire...
TIPS paper: arxiv.org/abs/2410.16512
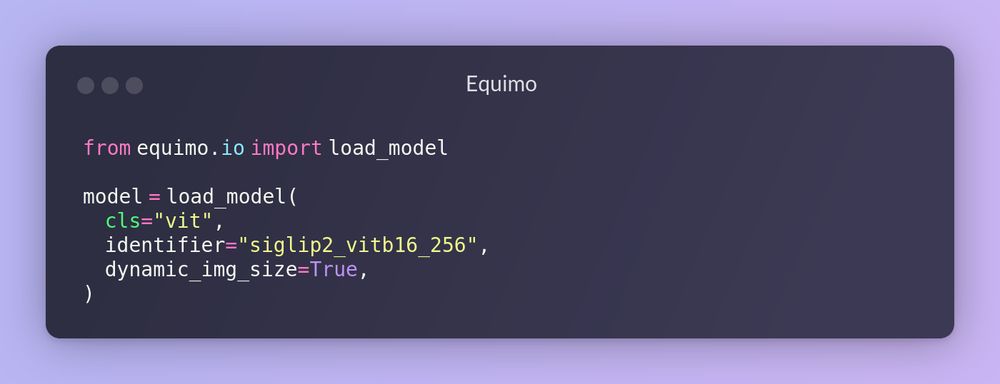
Loading SigLIP 2 computer vision model easily from the Equimo library
SigLIP 2 has been recently released, so I just added support for it in my Jax model library, Equimo! Feel free to try it :)
github.com/clementpoire...
It's bad, but still better than Neptune or Comet 😅
06.02.2025 17:45 — 👍 1 🔁 0 💬 0 📌 0
I just signed the exit of my own startup.
It's time to have some fun intermediate projects before the next big thing.
Let's take inspirations outside deep learning to come back stronger.
Maybe a bit niche, but Helix is a great editor. Getting a good REPL experience is a bit tricky though, so I wrote a bit about it
int8.tech/posts/repl-p...

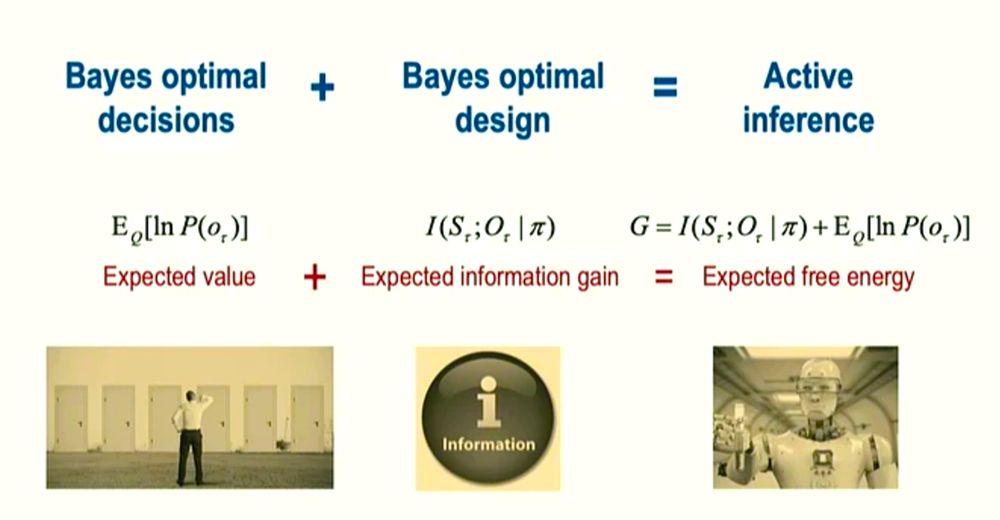

One of the most bizarre + complex talks at NeurIPS [1] was given by my fellow Yorkshireman, the inimitable Prof Karl Friston [2], explaining active inference to a room full of #AI people who are not really neuroscientists. This was interesting to me because... (1/n)
22.12.2024 06:57 — 👍 32 🔁 6 💬 3 📌 0I ported Matt Might's bash scripts for detecting common issues in writing to a little web app (using Claude) and it's pretty fun to play with: https://simonwillison.net/2024/Dec/14/improve-your-writing/
14.12.2024 18:55 — 👍 9 🔁 3 💬 0 📌 0
Our Open Source Developers Guide to the EU AI Act is now live! Check it out for an introduction to the AI Act and useful tools that may help prepare for compliance, with a focus on open source. Amazing to work with @frimelle.bsky.social and @yjernite.bsky.social on this!
02.12.2024 17:06 — 👍 38 🔁 18 💬 1 📌 1
I was in the exact same situation. Few days ago I found comin, basically just a systemd service automatically checking for config changes in a git repo. Very useful on VPS!
github.com/nlewo/comin
Awesome! Can't wait to try both. Thanks for your work and insights 👌
28.11.2024 07:46 — 👍 0 🔁 0 💬 0 📌 0Very insightful! Thanks a lot 👌
28.11.2024 07:43 — 👍 1 🔁 0 💬 0 📌 0
Although I tested outputs against official implementations (when possible), things might be broken / not respecting best practices, etc. Feel free to report issues and contribute :)
github.com/clementpoire...
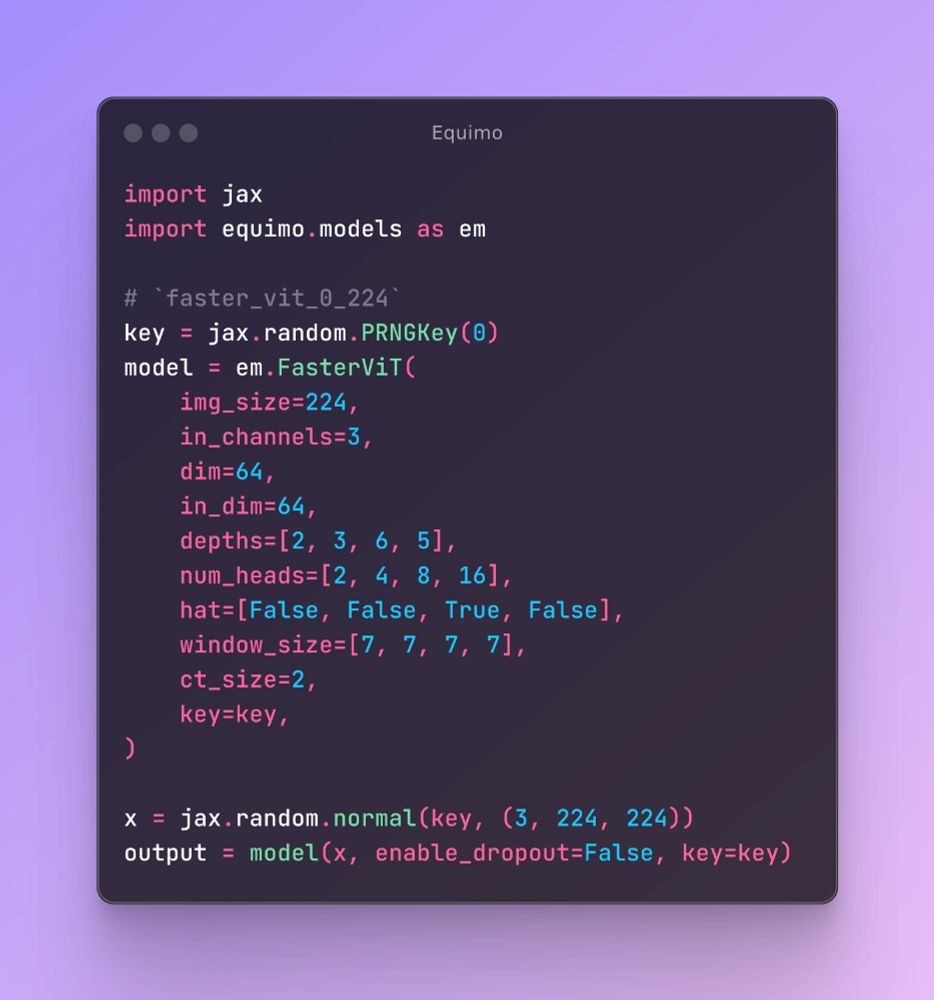
It ain't much, but it's honest work. I am open sourcing some model I am playing with.
Equimo is a JAX/Equinox library implementing modern vision architectures (2023-24). Features FasterViT, MLLA, VSSD, and more state-space/transformer models. Pure JAX implementation with modular design.
#MLSky
What they don't mention is that bfloat16 casting introduces biases. It'd have been interesting to compare the impact of Stochastic Rounding on RoPE
25.11.2024 11:31 — 👍 0 🔁 0 💬 0 📌 0
A timely paper exploring ways academics can pretrain larger models than they think, e.g. by trading time against GPU count.
Since the title is misleading, let me also say: US academics do not need $100k for this. They used 2,000 GPU hours in this paper; NSF will give you that. #MLSky
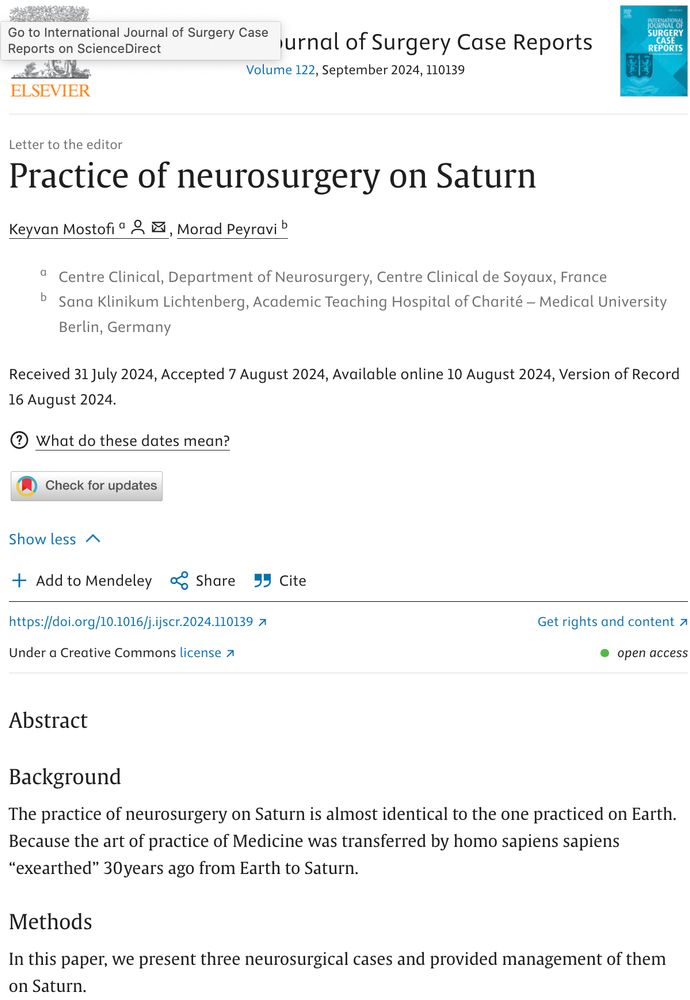
Wishing the Elsevier editors who desk-accepted this all the best for their next career moves.
doi.org/10.1016/j.ij...
Quick tip to reduce storage costs: save your images in AVIF format. AVIF compression algorithm is way more performant than JPEG/PNG. It'll make a huge difference on the bill at this scale. Also, wasabi.com is great in terms of prices.
23.11.2024 11:08 — 👍 2 🔁 0 💬 0 📌 0But there is definitely something to do here, your intuition looks good to me, having adaptive combinations of losses could definitely help
22.11.2024 20:11 — 👍 1 🔁 0 💬 0 📌 0Other papers seem to compute the gradients for each loss independently, and scale wrt to gradients norm 🤔
22.11.2024 19:39 — 👍 1 🔁 0 💬 1 📌 0Actually, there are papers on the topic. This one for example, also includes loss difficulty into account openaccess.thecvf.com/content/ICCV...
22.11.2024 18:50 — 👍 1 🔁 0 💬 1 📌 0The question is, does compute_grads(l1 + l2) == compute_grads(norm(l1) + norm(l2))
22.11.2024 18:23 — 👍 1 🔁 0 💬 1 📌 0This is interesting, but if the grads are staying the same, it would not change the optimization, thus resulting in the same model?
22.11.2024 18:21 — 👍 1 🔁 0 💬 1 📌 0
NixOS is literally a game changer. Managing the state of your entire OS in Git feels like a superpower. The only downside was dev environments (e.g. python venv), which is solved by devenv.sh. I made a very simple template I use every day w/ optional CUDA support: github.com/clementpoire...
22.11.2024 14:43 — 👍 10 🔁 2 💬 1 📌 0