Tomorrow, I’ll give a talk about future predictions in egocentric vision at the #CVPR2025 precognition workshop, in room 107A at 4pm.
I’ll retrace some history and show how precognition enables assistive downstream tasks and representation learning for procedural understanding.
11.06.2025 19:35 — 👍 5 🔁 1 💬 0 📌 0
Excited to be giving a keynote at the #CVPR2025 Workshop on Interactive Video Search and Exploration (IViSE) tomorrow. I'll be sharing our efforts working towards detailed video understanding.
📅 09:45 Thursday 12th June
📍 208 A
👉 sites.google.com/view/ivise2025
11.06.2025 16:36 — 👍 4 🔁 1 💬 0 📌 0

Have you heard about HD-EPIC?
Attending #CVPR2025
Multiple opportunities to know about the most highly-detailed video dataset with a digital twin, long-term object tracks, VQA,…
hd-epic.github.io
1. Find any of the 10 authors attending @cvprconference.bsky.social
– identified by this badge.
🧵
10.06.2025 21:48 — 👍 5 🔁 3 💬 1 📌 0
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
A Highly-Detailed Egocentric Video Dataset
Do you want to prove your Video-Language Model understands fine-grained, long-video, 3D world or anticipates interactions?
Be the 🥇st to win HD-EPIC VQA challenge
hd-epic.github.io/index#vqa-be...
DL 19 May
Winners announced @cvprconference.bsky.social #EgoVis workshop
06.05.2025 10:27 — 👍 8 🔁 3 💬 0 📌 0
Object masks &tracks for HD-EPIC have been released.. This completes our highly-detailed annotations.
Also, HD-EPIC VQA challenge is open [Leaderboard closes 19 May]... can you be 1st winner?
codalab.lisn.upsaclay.fr/competitions...
Btw, HD-EPIC was accepted @cvprconference.bsky.social #CVPR2025
03.04.2025 19:06 — 👍 10 🔁 4 💬 0 📌 0
The HD-EPIC VQA challenge for CVPR 2025 is now live: codalab.lisn.upsaclay.fr/competitions...
See how your model stacks up against Gemini and LLaVA Video on a wide range of video understanding tasks.
05.03.2025 15:55 — 👍 0 🔁 0 💬 0 📌 0
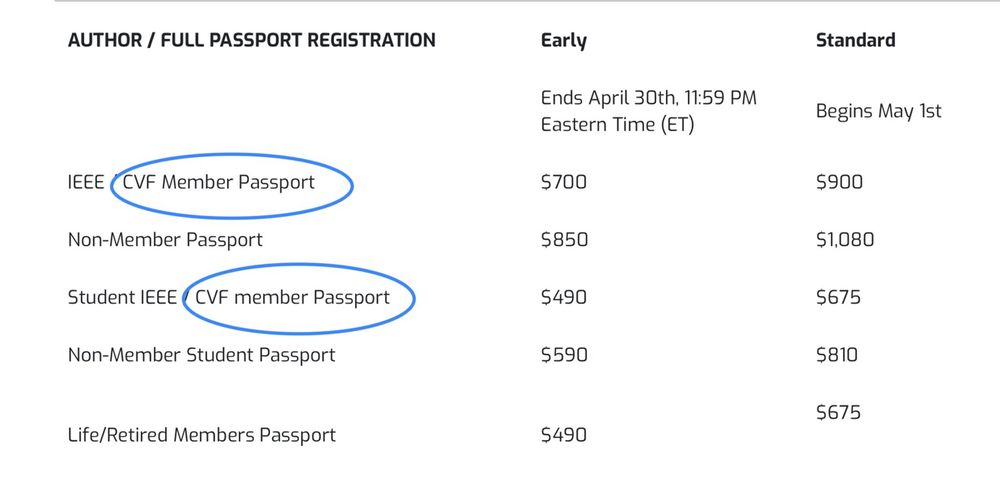
#CVPR2025 PRO TIP: To get a discount on your registration, join the Computer Vision Foundation (CVF). It’s FREE and makes @wjscheirer smile 😉
CVF: thecvf.com
28.02.2025 01:50 — 👍 14 🔁 6 💬 0 📌 1
HD-EPIC - hd-epic.github.io
Egocentric videos 👩🍳 with very rich annotations: the perfect testbed for many egocentric vision tasks 👌
07.02.2025 15:26 — 👍 6 🔁 2 💬 0 📌 0
https://hd-epic.github.io/
This was a monumental effort from a large team across Bristol, Leiden Singapore and Bath.
The VQA benchmark only scratches the surfaces of what is possible to evaluate with this detail of annotations.
Check out the website if you want to know more: hd-epic.github.io
07.02.2025 12:27 — 👍 1 🔁 0 💬 0 📌 0

VQA Benchmark
Our benchmark tests understanding in recipes, ingredients, nutrition, fine-grained actions, 3D perception, object movement and gaze. Current models have a long way to go with a best performance of 38% vs. 90% human baseline.
07.02.2025 12:27 — 👍 1 🔁 0 💬 1 📌 1
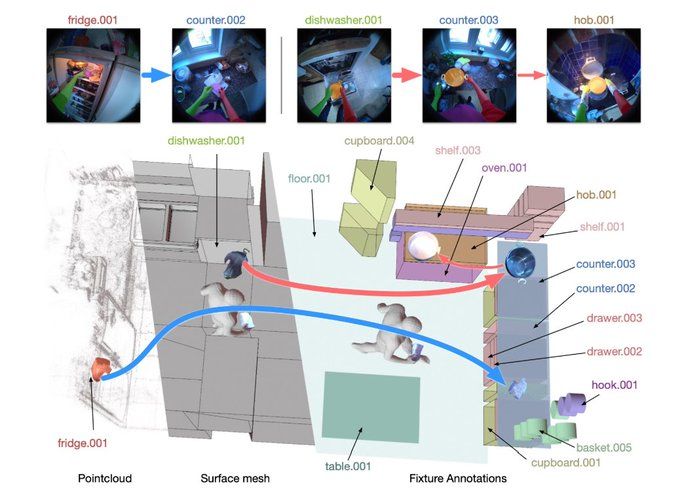
Scene & Object Movements
We reconstruct participants kitchens and annotate every time an object is moved.
07.02.2025 12:27 — 👍 2 🔁 0 💬 1 📌 0


Fine-grained Actions
Every action has a dense description not only describing what happens in detail, but also how and why it happens.
07.02.2025 12:27 — 👍 1 🔁 0 💬 1 📌 0

As well as annotating temporal segments corresponding to each step we also annotate all the preparation needed to complete each step.
07.02.2025 12:27 — 👍 1 🔁 0 💬 1 📌 0

Recipe & Nutrition
We collect details of all the recipes participants chose to perform over 3 days in their own kitchen. Alongside ingredient weights and nutrition.
07.02.2025 12:27 — 👍 1 🔁 0 💬 1 📌 0
📢 Today we're releasing a new highly detailed dataset for video understanding: HD-EPIC
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
07.02.2025 12:27 — 👍 16 🔁 4 💬 1 📌 1
🛑📢
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
arxiv.org/abs/2502.04144
New collected videos
263 annotations/min: recipe, nutrition, actions, sounds, 3D object movement &fixture associations, masks.
26K VQA benchmark to challenge current VLMs
1/N
07.02.2025 11:45 — 👍 33 🔁 6 💬 2 📌 4
We propose a simple baseline using phrase-level negatives and visual prompting to balance coarse- and fine-grained performance. This can easily combined with existing approaches. However, there is much potential for future work.
10.12.2024 06:46 — 👍 1 🔁 0 💬 1 📌 0

Incorporating fine-grained negatives into training does improve fine-grained performance, however it comes at the cost of coarse-grained performance.
10.12.2024 06:46 — 👍 1 🔁 0 💬 1 📌 0
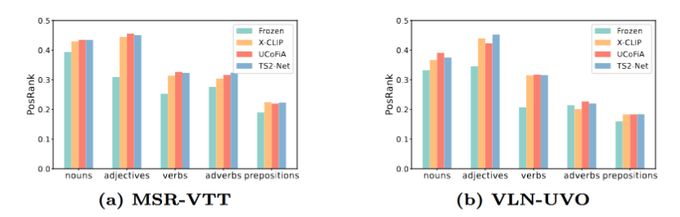
We use this evaluation to investigate current models and find they lack fine-grained understanding, particularly for adverbs and prepositions.
We also see that good coarse-grained performance does not necessarily indicate good fine-grained performance.
10.12.2024 06:46 — 👍 0 🔁 0 💬 1 📌 0

We propose a new fine-grained evaluation approach which analyses a model's sensitivity to individual word variations in different parts-of-speech.
Our approach automatically creates new fine-grained negative captions and can be applied to any existing dataset.
10.12.2024 06:46 — 👍 0 🔁 0 💬 1 📌 0
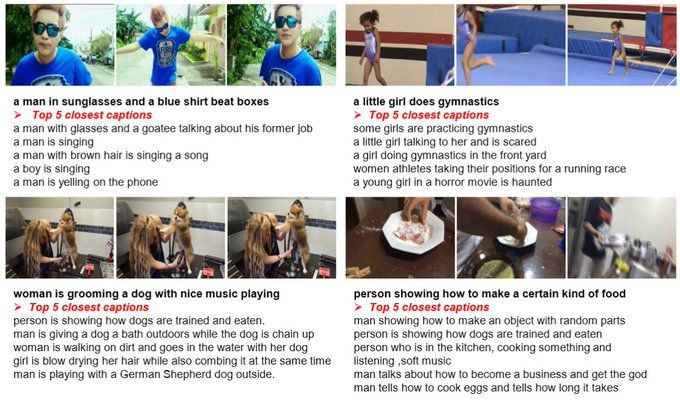
Current video-text retrieval benchmarks focus on coarse-grained differences as they focus on distinguishing the correct caption from captions of other, often irrelevant videos.
Captions thus rarely differ by a single word or concept.
10.12.2024 06:46 — 👍 1 🔁 0 💬 1 📌 0

Our second #ACCV2024 oral: "Beyond Coarse-Grained Matching in Video-Text Retrieval" is also being presented today.
ArXiv: arxiv.org/abs/2410.12407
We go beyond coarse-grained retrieval and explore whether models can discern subtle single-word differences in captions.
10.12.2024 06:46 — 👍 3 🔁 1 💬 1 📌 0
Training a model on the these video-text pairs results in a representation that is beneficial to motion-focused downstream tasks, particularly when little data is available for finetuning.
10.12.2024 06:42 — 👍 1 🔁 0 💬 1 📌 0

Since we know how our synthetic motions have been generated we can also generate captions to describe them using pre-defined phrases. We then diversify the vocabulary and structure of our descriptions with our verb-variation paraphrasing.
10.12.2024 06:42 — 👍 0 🔁 0 💬 1 📌 0
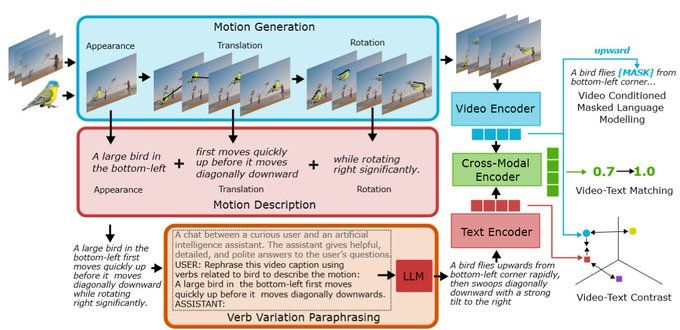
We address this by proposing a method to learn motion-focused representations with available spatial-focused data. We first generate synthetic local object motions and inject this into training videos.
10.12.2024 06:42 — 👍 0 🔁 0 💬 1 📌 0
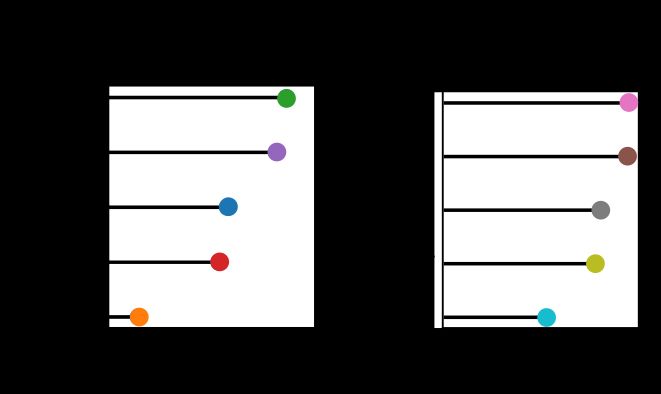
Moreover, large proportion of captions are uniquely identifiable by the nouns alone, meaning a caption can be matched to the correct video clip by only recognizing the correct nouns.
10.12.2024 06:42 — 👍 0 🔁 0 💬 1 📌 0
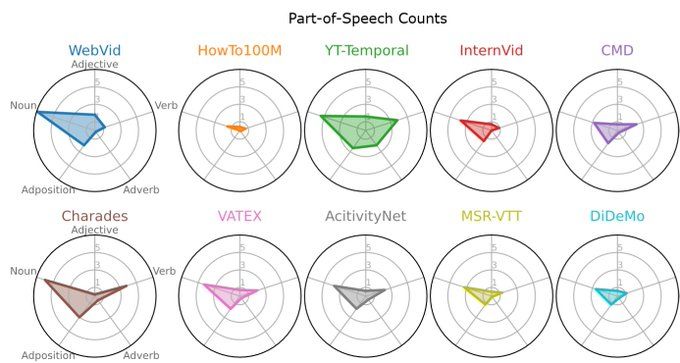
Captions in current video-language pre-training and downstream datasets are spatially focused, with nouns being far more prevalent than verbs or adjectives.
10.12.2024 06:42 — 👍 0 🔁 0 💬 1 📌 0

Today we're presenting out #ACCV2024 Oral "LocoMotion: Learning Motion-Focused Video-Language Representations".
We remove the spatial focus of video-language representations and instead train representations to have a motion focus.
10.12.2024 06:42 — 👍 2 🔁 0 💬 1 📌 0
https://tinyurl.com/BristolCVLectureship
Pls RT
Permanent Assistant Professor (Lecturer) position in Computer Vision @bristoluni.bsky.social [DL 6 Jan 2025]
This is a research+teaching permanent post within MaVi group uob-mavi.github.io in Computer Science. Suitable for strong postdocs or exceptional PhD graduates.
t.co/k7sRRyfx9o
1/2
04.12.2024 17:22 — 👍 23 🔁 14 💬 1 📌 1
EurIPS is a community-organized, NeurIPS-endorsed conference in Copenhagen where you can present papers accepted at @neuripsconf.bsky.social
eurips.cc
Pentagon Pizza Report: Open-source tracking of pizza spot activity around the Pentagon. Updates on where the lines are long.
Principal research scientist at Naver Labs Europe, I am interested in most aspects of computer vision, including 3D scene reconstruction and understanding, visual localization, image-text joint representation, embodied AI, ...
Trending papers in Vision and Graphics on www.scholar-inbox.com.
Scholar Inbox is a personal paper recommender which keeps you up-to-date with the most relevant progress in your field. Follow us and never miss a beat again!
PhD student at the University of Tuebingen. Computer vision, video understanding, multimodal learning.
https://ninatu.github.io/
Created by the University of Bristol, the BVI brings together engineers and scientists from a range of academic disciplines and external partners.
Computer Vision research group @ox.ac.uk
Computer Vision team of LIGM/A3SI @EcoledesPonts ParisTech (ENPC)
Making robots part of our everyday lives. #AI research for #robotics. #computervision #machinelearning #deeplearning #NLProc #HRI Based in Grenoble, France. NAVER LABS R&D
europe.naverlabs.com
Prof. Social and Affective Computing, Utrecht University.
Former institutions: Boğaziçi University, Nagoya University, University of Amsterdam, CWI.
https://webspace.science.uu.nl/~salah006/
Assistant professor in science communication with emphasis at biodiversity & society at Leiden University
Academy Research Fellow leading Helsinki Urban Rat Project at University of Helsinki
XAI and LLM-EC researcher at LIACS, Leiden University.
Fantasy writer.
Koepelvereniging voor 14 bekostigde universiteiten in Nederland
Wij bestuderen al meer dan 200 jaar het leven op aarde. Klein en groot. Springlevend of miljoenen jaren dood. En dat is nu belangrijker dan ooit.
www.naturalis.nl
🇨🇦 🇳🇱 #CitizenScience and #OpenScience are my jam. I run the Citizen Science Lab at Leiden University, and co-lead the CS-NL network.
Faculty of Science | University of Leiden | Discover our research, education & events | Meet the amazing people who work and study with us 🚀🔬📚
#Science #Biodiversity #Sustainability #AI #DrugDiscovery #DrugDevelopment #ComplexNetworks #Quantum #Space
PhD student at MIT. Machine learning, computer vision, ecology, climate. Previously: Co-founder, CTO Ai.Fish; Researcher at Caltech; UC Berkeley. justinkay.github.io
Prize Fellow at the University of Bath. Work website: https://www.davidemoltisanti.com/research. My photos: https://www.davidemoltisanti.com























