



𝗛𝗢𝗦𝘁𝟯𝗥: 𝗞𝗲𝘆𝗽𝗼𝗶𝗻𝘁-𝗳𝗿𝗲𝗲 𝗛𝗮𝗻𝗱-𝗢𝗯𝗷𝗲𝗰𝘁 𝟯𝗗 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻 𝗳𝗿𝗼𝗺 𝗥𝗚𝗕 𝗶𝗺𝗮𝗴𝗲𝘀
Anilkumar Swamy, Vincent Leroy, Philippe Weinzaepfel ... Grégory Rogez
arxiv.org/abs/2508.16465
Trending on www.scholar-inbox.com

@gabrielacsurka.bsky.social
Principal research scientist at Naver Labs Europe, I am interested in most aspects of computer vision, including 3D scene reconstruction and understanding, visual localization, image-text joint representation, embodied AI, ...
𝗛𝗢𝗦𝘁𝟯𝗥: 𝗞𝗲𝘆𝗽𝗼𝗶𝗻𝘁-𝗳𝗿𝗲𝗲 𝗛𝗮𝗻𝗱-𝗢𝗯𝗷𝗲𝗰𝘁 𝟯𝗗 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻 𝗳𝗿𝗼𝗺 𝗥𝗚𝗕 𝗶𝗺𝗮𝗴𝗲𝘀
Anilkumar Swamy, Vincent Leroy, Philippe Weinzaepfel ... Grégory Rogez
arxiv.org/abs/2508.16465
Trending on www.scholar-inbox.com




Gaussian Splatting Feature Fields for Privacy-Preserving Visual Localization
Maxime Pietrantoni, @gabrielacsurka.bsky.social, @sattlertorsten.bsky.social
arxiv.org/abs/2507.23569
We extended MUSt3R with semantic awareness and multi-view panoptic segmentation capabilities in PanSt3R, accepted at #ICCV2025
www.arxiv.org/abs/2506.21348

Excited to share our latest work in the *St3R family. PanSt3R, accepted at #ICCV25 proposes a unified and integrated approach for panoptic 3D scene reconstruction and panoptic segmentation in a single forward pass.
www.arxiv.org/abs/2506.21348




I gave two talks @cvprconference.bsky.social #cvpr2025
Slides are now available for those interested
1- Catch me if you can: Manoeuvre the Competition
with Your Unique Abilities
tinyurl.com/StandOut-DD2...
2- Beyond Long Video Understanding
tinyurl.com/BeyondLong-D...

During today's #CVPR2025 workshops, I will present:
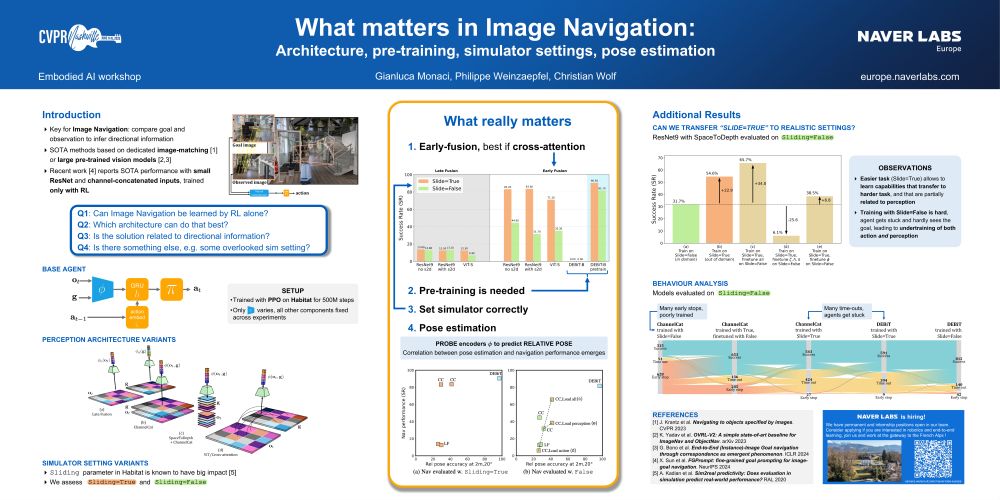
- What matters in ImageNav: architecture, pre-training, sim settings, pose (poster & highlight at the Embodied AI workshop)
- CondiMen: Conditional Multi-person Human Mesh Recovery (Poster at the Rhobin workshop and at the 3D Humans workshop)

Our work on "Reasoning in visual navigation..." presented as a "Highlight" by Boris Chidlovskii and Francesco Giuliari at #cvpr2025!
Interactive site, play around with dynamical models:
europe.naverlabs.com/research/pub...
Thanks @weinzaepfelp.bsky.social for the photo.
@steevenj7.bsky.social
I have created a starter pack with researchers from Naver Labs Europe @naverlabseurope.bsky.social: we are in Grenoble, France, and we do research in AI for robotics, computer vision, NLP, machine learning, HRI.
go.bsky.app/JdTFu4Q
Wanna the outstanding performance of MASt3R while using a ViT-B or ViT-S encoder instead of its ViT-L one? Don't miss how we build DUNE, a single encoder for diverse 2D & 3D tasks, at this afternoon #CVPR2025 poster session (poster #376).
paper: arxiv.org/abs/2503.14405
code: github.com/naver/dune

Excited to share Maxime’s latest work on Privacy Preserving Visual Localization. If interested Maxime will present his work tomorrow at #CVPR2025, Poster Session 1, Poster Number 85 (ExHall D).
12.06.2025 15:35 — 👍 14 🔁 1 💬 0 📌 3For which the code is also available github.com/naver/pow3r
12.06.2025 13:41 — 👍 6 🔁 2 💬 0 📌 1
1/ 📄 Paper 1:
"DUNE: Distilling a UNiversal Encoder from Heterogeneous 2D and 3D Teachers"
We propose DUNE: a ViT-based encoder distilled from multiple specialized 2D & 3D foundation models to unify visual tasks across 2D, 3D and human understanding.
A teaser of the latest 3D DUSt3R based models we’re presenting at @cvprconference.bsky.social
Discover MUSt3R & Pow3R, universal encoder DUNE + research in navigation, vizloc, segmentation & human motion understanding!
All our #CVPR2025 papers are here
➡️ tinyurl.com/4z79ujce

Interestingly, the network generalizes very well to many more images than seen during training.
Code IS available here github.com/naver/must3r
I hope it works in your scenarios and you have as much fun as we do playing around with it!

*3R posts are back! 🧵
Interested in SfM, RGB-SLAM or... both at the same time???
Come see MUSt3R @CVPR25 Friday morning, ExHall D Poster #82.
Jerome and Boris will be there to present how we can adapt DUSt3R to multiple views via a memory mechanism.
If you missed it earlier [...]




















