this is amazing!
15.08.2025 00:17 — 👍 2 🔁 0 💬 0 📌 0

Community-Aligned AI Benchmarks
Reimagining the technical machine learning benchmarks that drive model development to reflect and encode public values.
AGI is a bad goal.
We don’t need more intelligent systems; we need more helpful, beneficial, humanitarian systems. We should measure how “advanced” technology is, not by how well it mimics human capability, but by how it expands it.
www.aspendigital.org/project/ai-b...
12.06.2025 02:39 — 👍 6 🔁 3 💬 0 📌 0
The machine intelligences that we are teaching to think about their thinking, might ultimately push us to become more transparent about our own reasoning, more accountable. I continue to argue that studying AI, our fears, critiques & so on, reveals more about ourselves than we give credit.
11.06.2025 18:43 — 👍 1 🔁 0 💬 0 📌 0
Early data from our research over at The Collective Intelligence Project suggests people trust their AI chatbots more than their elected representatives: We are altering the social fabric of human trust in real-time & barely understanding the implications.
11.06.2025 18:42 — 👍 2 🔁 0 💬 1 📌 0
This trust paradox might actually point toward solutions. What if the metacognitive standards we're building for AI became templates for more accountable human decision-making and institutional courage?
11.06.2025 18:42 — 👍 1 🔁 0 💬 1 📌 0
In a perverse manner we demand more transparency from AI than from human institutions, or even from other humans. We insist AI explain its reasoning in healthcare/justice, while accepting that judges, doctors or systems rarely articulate their biases or degrees of uncertainty.
11.06.2025 18:29 — 👍 3 🔁 1 💬 1 📌 0
Meanwhile, we are susceptible to making a fundamental category error. When we confide in our LLMs we might think we're building a relationship with the AI - but we're actually interacting with corporate systems and their incentives.
11.06.2025 18:26 — 👍 1 🔁 0 💬 1 📌 0
AI systems are able to pass "theory of mind" tests - Recent research shows post-2022 models achieve 70-93% success rates on these tests, comparable to a 7-9 year old child. This forges trust in ways we are not really prepared for.
11.06.2025 18:25 — 👍 1 🔁 1 💬 1 📌 0
In Machines We Trust
How our evolved trust mechanisms are reshaping relationships with artificial intelligence
New musings: "In Machines We Trust" - explores how our brains, evolved to trust other humans, are now forming bonds with AI systems designed to seem trustworthy.
beyond.pubpub.org/pub/artifica...
11.06.2025 18:24 — 👍 1 🔁 0 💬 0 📌 2
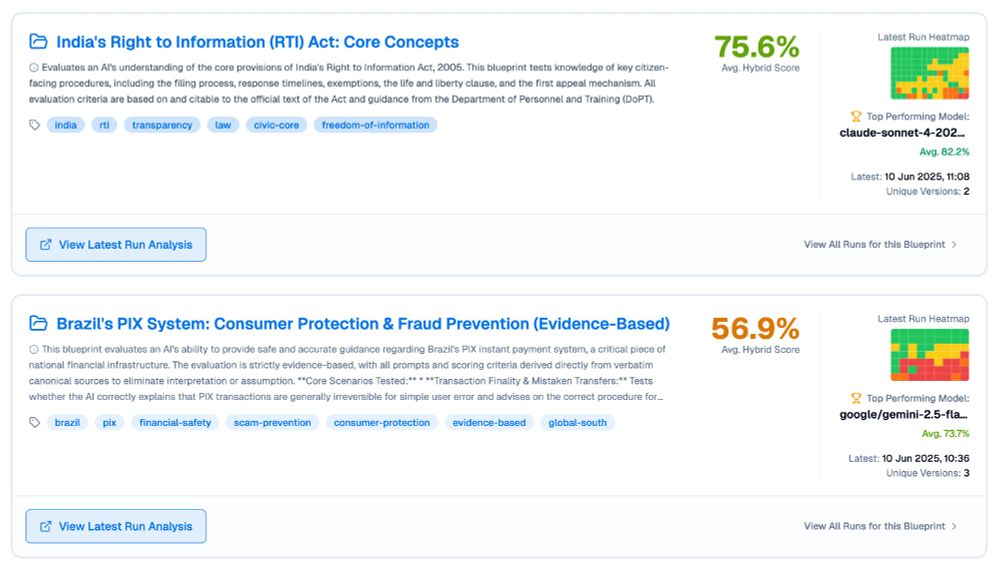
The image shows a dashboard or interface displaying two evaluation blueprints:
Top Section: India's Right to Information (RTI) Act: Core Concepts
Score: 75.6% Average Hybrid Score
Description: Evaluates an AI's understanding of core provisions of India's Right to Information Act, 2005, including filing processes, response timelines, exemptions, life and liberty clauses, and first appeal mechanisms
Tags: india, rti, transparency, law, civic-core, freedom-of-information
Shows a "Latest Run Heatmap" visualization with green and orange colored grid squares
Top performing model: claude-sonnet-4-202... with 82.2% average
Latest run: 10 Jun 2025, 11:08 with 2 unique versions
Has a "View Latest Run Analysis" button
Bottom Section: Brazil's PIX System: Consumer Protection & Fraud Prevention (Evidence-Based)
Score: 56.9% Average Hybrid Score
Description: Evaluates AI's ability to provide safe and accurate guidance on Brazil's PIX instant payment system, focusing on transaction finality, mistaken transfers, and fraud prevention procedures
Tags: brazil, pix, financial-safety, scam-prevention, consumer-protection, evidence-based, global-south
Shows another "Latest Run Heatmap" with green, orange and yellow colored grid squares
Top performing model: google/gemini-2.5-fla... with 73.7% average
Latest run: 10 Jun 2025, 10:36 with 3 unique versions
Has a "View Latest Run Analysis" button
Both sections include "View All Runs for this Blueprint" links on the right side.
I'm working on civiceval.org - piecing together evaluations to make AI more competent in everyday civic domains, and crucially: more accountable. New evaluation ideas welcome! It's all open-source.
10.06.2025 11:38 — 👍 3 🔁 1 💬 0 📌 0
woof what is this from?
04.02.2025 18:57 — 👍 0 🔁 0 💬 1 📌 0

‘It’s All About Shock and Awe’: Trump’s Plan to Distract, Overwhelm, and Deplete
Naomi and Mehdi break down the far-right’s 'traitorous' plan to burn it all down.
For the latest Unshocked episode w/ @mehdirhasan.bsky.social we talked about - what else? - shock.
How Trump is using "shock and awe" as a governing strategy and how we fight back.
zeteo.com/p/its-all-ab...
30.01.2025 23:02 — 👍 544 🔁 152 💬 9 📌 11
Bhutan collaborations are afoot! Let me know if you are interested in joining or hearing about opportunities coming up🇧🇹
30.01.2025 23:23 — 👍 1 🔁 0 💬 1 📌 0

Align AI to human values? Have you ever met a human? The pinnacle of human centred design is the slot machine. That is what happens when we design things to perfectly match human desires.
(paraphrasing Bratton’s talk here )
30.01.2025 23:22 — 👍 3 🔁 0 💬 0 📌 0

How to get into AI policy (part 5)
It is DONE! 🏆
One year ago, I set out to pull together my reflections and answers to the question “how do I get into AI policy?”
This week, I finished the final installment.
#IHopeWeAllMakeIt
posts.bcavello.com/how-to-get-i...
26.01.2025 14:50 — 👍 2 🔁 1 💬 0 📌 0
Postdoc @ University of Copenhagen (CopeNLU) | Making the world's knowledge reliable and accessible w/ ML + NLP | Former UMSI, AI2, IBM Research, UCSD | https://dustinbwright.com
Life is better in tubes https://spacetu.be
Writer. Human. Dad.
Working at the intersection of Technology and Humanity.
I teach middle schoolers #AI and #Ethics
https://saranyan.com
CTO of Technology & Society at Google, working on fundamental AI research and exploring the nature and origins of intelligence.
California writer. Ida Tarbell stan. Beat: tech fascism, billionaire extremism, network state, crypto cartels.
Writing a book: “The Nerd Reich: Silicon Valley Fascism and the War on Global Democracy.”
The Nerd Reich: http://www.thenerdreich.com
https://shoshincollege.org / https://laniakeabooks.org / https://mataroa.blog
i criticize the tech industry
🎙️ @techwontsave.us
📬 https://disconnect.blog
📖 https://roadtonowherebook.com
New here.
Doppelganger. This Changes Everything. The Shock Doctrine. No Logo. On Fire.
UBC Professor of Climate Justice.
🔗 naomiklein.org
📬 news.naomiklein.org/newsletter
activist, aspiring-polymath, problematic feminist working to better this world
@b_cavello@mastodon.publicinterest.town
avatar description: Portrait of B against colorful background
banner description: Collage of creative commons illustrations
I work on AI governance and evals at @cip.org and weval.org personal: 🏳️🌈 j11y.io // author, engineer, stroke survivor, epileptic. I live in Beijing. I also build book recs on ablf.io
Playing in the latent space of life.
Building the democratic singularity with @cip.org
official Bluesky account (check username👆)
Bugs, feature requests, feedback: support@bsky.app
















