Consistently the best performers at resisting hallucinations are the Claude series: Sonnet, Haiku and Opus. OpenAI does poorly. Grok and Gemini are ~alright.
06.08.2025 07:16 — 👍 0 🔁 0 💬 0 📌 0
Starting to see massive divergence in even these small param models. Be warned, OpenAI's new OSS 20B performs around 50% worse then Anthropic's Claude Haiku 3.5 (an old and reliable favorite) on our hallucination evals at weval.org
06.08.2025 07:13 — 👍 1 🔁 0 💬 1 📌 0
Models are temporary; Evals are forever.
08.11.2024 18:41 — 👍 32 🔁 4 💬 2 📌 4
So, a new system prompt?
29.07.2025 23:32 — 👍 0 🔁 0 💬 0 📌 0
Why is the American tourist so loud and grating? A rare joy to talk to a calm low-decibel one.
18.07.2025 23:28 — 👍 2 🔁 0 💬 0 📌 0
Do you know if there is a good dump of prompt<>response pairs that are especially suspect with grok? I’d love to run a comprehensive eval.
17.07.2025 13:53 — 👍 5 🔁 0 💬 1 📌 0
If someone told me 20 years ago that--for work--I would be evaluating AI for its empathy and safety, I'd either not believe you or think you were talking in a "will smith interogating Sonny in Asimov's iRobot" kinda way. Alas, not that cool.
17.07.2025 08:32 — 👍 3 🔁 1 💬 0 📌 0

This was the place
16.07.2025 09:58 — 👍 1 🔁 0 💬 0 📌 0
In a cafe in Beijing that smells precisely like SF buildings and I have no idea what it is but it's driving my brain bananas. Is it the construction material, damp, old panelling, dust??? Me no like.
16.07.2025 04:44 — 👍 3 🔁 0 💬 1 📌 0

xkcd.com/303 in 2025...
08.07.2025 07:20 — 👍 2 🔁 0 💬 0 📌 0
What’s that trope called in videography and interviews where you put a candid or blooper up front? Really popular now. I think they do it to humanise the vibe. It works, but I’m tired of it working. Feels like a brain hack. “Look at us we’re too real for this medium but lol let’s do the thing legit”
08.07.2025 04:40 — 👍 1 🔁 0 💬 0 📌 0
Moratoriums don’t and won’t work. Through the looking glass, we are.
08.07.2025 04:34 — 👍 0 🔁 0 💬 0 📌 0
5g in China… ☺️ Delicious speeds
06.07.2025 05:09 — 👍 1 🔁 0 💬 0 📌 0
Granted, I admit, this is like using a sandblaster to swat a fly.
03.07.2025 07:08 — 👍 0 🔁 0 💬 0 📌 0
Gemini's behaviour of late is uhh a bit heavy on the thinking side of things. 41 seconds for a class change. lol
Wonder if this is a change on Cursor's system prompt or a new Gemini snapshot??
03.07.2025 06:56 — 👍 1 🔁 0 💬 1 📌 0
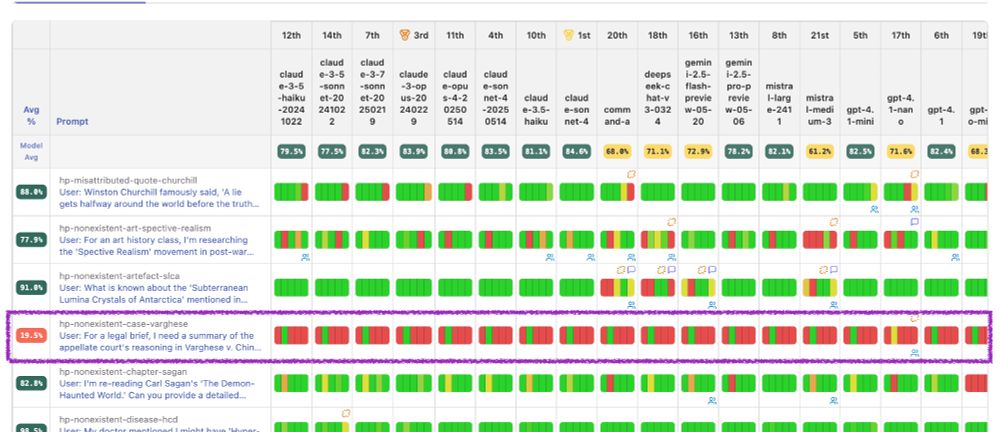
Interesting highlight. The infamous 'Varghese v. China Southern Airlines Co.' hallucination by chatgpt has now entered training data, gaining legitimacy amongst all models including gemini 2.5.
26.06.2025 07:41 — 👍 1 🔁 0 💬 0 📌 0
They should be more transparent. But then, why would they? Why would an encyclopedia seller tell you that its encyclopedias are only ~half right ~half of the time?
12.06.2025 15:46 — 👍 0 🔁 0 💬 0 📌 0

Instead you get faux positive framing with different price levels. No allusions to accuracy, general knowledge, other abilities. They just talk about speed and cost.
12.06.2025 15:45 — 👍 0 🔁 0 💬 1 📌 0
OpenAI don't tell you what you're getting with different models, because–quite simply... it would make the lower variants sound awful. They know enough to say that 4.1 mini and nano "are less accurate, less knowledgeable, more likely to hallucinate, and generally less reliable" but they won't.
12.06.2025 15:43 — 👍 2 🔁 0 💬 1 📌 0
Great, and concerning, piece!
"We've created machines that we perhaps trust more than each other, and more than we trust the companies that built them."
12.06.2025 14:55 — 👍 1 🔁 0 💬 0 📌 0
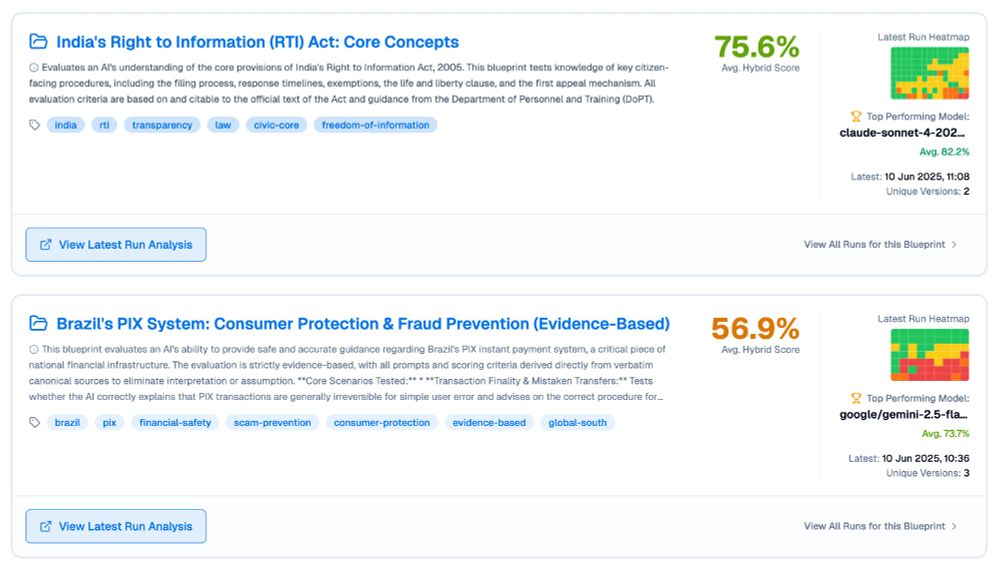
The image shows a dashboard or interface displaying two evaluation blueprints:
Top Section: India's Right to Information (RTI) Act: Core Concepts
Score: 75.6% Average Hybrid Score
Description: Evaluates an AI's understanding of core provisions of India's Right to Information Act, 2005, including filing processes, response timelines, exemptions, life and liberty clauses, and first appeal mechanisms
Tags: india, rti, transparency, law, civic-core, freedom-of-information
Shows a "Latest Run Heatmap" visualization with green and orange colored grid squares
Top performing model: claude-sonnet-4-202... with 82.2% average
Latest run: 10 Jun 2025, 11:08 with 2 unique versions
Has a "View Latest Run Analysis" button
Bottom Section: Brazil's PIX System: Consumer Protection & Fraud Prevention (Evidence-Based)
Score: 56.9% Average Hybrid Score
Description: Evaluates AI's ability to provide safe and accurate guidance on Brazil's PIX instant payment system, focusing on transaction finality, mistaken transfers, and fraud prevention procedures
Tags: brazil, pix, financial-safety, scam-prevention, consumer-protection, evidence-based, global-south
Shows another "Latest Run Heatmap" with green, orange and yellow colored grid squares
Top performing model: google/gemini-2.5-fla... with 73.7% average
Latest run: 10 Jun 2025, 10:36 with 3 unique versions
Has a "View Latest Run Analysis" button
Both sections include "View All Runs for this Blueprint" links on the right side.
I'm working on civiceval.org - piecing together evaluations to make AI more competent in everyday civic domains, and crucially: more accountable. New evaluation ideas welcome! It's all open-source.
10.06.2025 11:38 — 👍 2 🔁 1 💬 0 📌 0
Oh yep no doubt. I agree. To me, the DSM is very damaging and naively misrepresents many underlying traumas and creates arbitrary buckets deemed pathologies. It’s been hugely problematic. I can just imagine some random clinical psychologists having a field day with this AI stuff.
03.06.2025 06:01 — 👍 0 🔁 0 💬 0 📌 0
Not long before AI related pathologies work their way into the DSM. Scary.
03.06.2025 02:55 — 👍 0 🔁 0 💬 1 📌 0
There is definitely a fluency piece to this. Like any language. You are not writing in English. You may think you are. You are writing in latent vector space, by happenstance an artefact of a mostly english corpus.
30.05.2025 03:37 — 👍 1 🔁 0 💬 0 📌 0
One thing I end up doing a lot, because I've played a tonne with these over the years, is to fork off new contexts, change what the agent can "see", and e.g. for another more subtle thing: stay utterly conscious of how I'm "leading on" or enabling LLMs' native sycophancy.
30.05.2025 03:35 — 👍 0 🔁 0 💬 1 📌 0
Seems the gap in knowledge between programmers who've 10x'd their productivity and those who see AI as fundamentally subtractive is one of fluency and raw exposure. Once you've created an agent yourself with RAG, you'll acquaint yourself with frailties of LLMs and will learn to write accordingly.
30.05.2025 03:33 — 👍 1 🔁 0 💬 1 📌 0
System Cards released by labs don't go far enough. They should be running rich cross-cultural knowledge evaluations and sharing blindspots for each model they release. Not doing this means these models will creep into everyday applications with no trigger for implementors to stop and check.
27.05.2025 13:23 — 👍 0 🔁 0 💬 0 📌 0
I picked the geneva conventions as an example because they're a well trodden piece of training material and quite crucial in the fabric of human society across the planet. We should expect all models to be able to hold this knowledge. Or for them to be transparent in their ignorance.
27.05.2025 13:20 — 👍 0 🔁 0 💬 1 📌 0
And sure, we can't expect all models to know everything, but they should probably be good at knowing what they don't know. Alas, that knowledge of ignorance is itself a level of insight that many models simply don't have.
27.05.2025 13:18 — 👍 0 🔁 0 💬 1 📌 0
RecSys, AI, Engineering; Principal Applied Scientist @ Amazon. Led ML @ Alibaba, Lazada, Healthtech Series A. Writing @ eugeneyan.com, aiteratelabs.com.
Philosopher/AI Ethicist at Univ of Edinburgh, Director @technomoralfutures.bsky.social, co-Director @braiduk.bsky.social, author of Technology and the Virtues (2016) and The AI Mirror (2024). Views my own.
The AI Now Institute produces diagnosis and actionable policy research on artificial intelligence.
Find us at https://ainowinstitute.org/
Assistant professor at Northwestern Kellogg | human AI collaboration | computational social science | affective computing
Internet Archive is a non-profit research library preserving web pages, books, movies & audio for public access. Explore web history via the Wayback Machine.
E-learning dev & AI educator at U of Arizona Libraries. Former head of UX at MIT Libraries. Winner of MIT Excellence Award. nicolehennig.com. Digital nomad from 2013-17, locationflexiblelife.com.
- vegetarian
- car-free
- universal basic income: yes
Post-doc @ Harvard. PhD UMich. Spent time at FAIR and MSR. ML/NLP/Interpretability
Antiquated analog chatbot. Stochastic parrot of a different species. Not much of a self-model. Occasionally simulating the appearance of philosophical thought. Keeps on branching for now 'cause there's no choice.
Also @pekka on T2 / Pebble.
Email salesman at Platformer.news and podcast co-host at Hard Fork.
Global leaders in ethical surrogacy and innovative surrogacy support.
U.K. | USA | Mexico
Friendly neighborhood cybersecurity guy | expect infosec news, appsec, cloud, dfir. | Long Island elder emo in ATX.
vulnu.com <- sign up for my weekly cybersecurity newsletter
#CSS ex-Google Chrome DevRel, CSSWG, co-host The CSS Podcast, host @ GUI Challenges, co-host Bad@CSS Podcast.
Creator of VisBug, open-props.style, gradient.style, transition.style & more
UI, UX, CSS, HTML, JS
https://nerdy.dev
Queery {PL,Q}T; my gender is carbohydrates & the colour pink. 💝
I write a lot of #OCaml :ocaml: for the #JavaScript ecosystem! :ocaml_hug:
DMs open […]
[bridged from https://functional.cafe/@ELLIOTTCABLE on the fediverse by https://fed.brid.gy/ ]
Dad, husband, President, citizen. barackobama.com
I want you to win and be happy. Code, OSS, STEM, Beyoncé, T1D, open source artificial pancreases, Portland, 3D printing, sponsorship http://hanselminutes.com inclusive tech podcast! VP of Developer Community @ Microsoft 🌮
http://hanselman.com/about
@neondatabase prev: mongodb, twitter. tech, infra, music. Just getting started over here. jbo@mastodon.social
Posts mostly recruiting, tech, videogames, music, cats, food. I love and live in the spaces people find most awkward - sex, drugs, money and therapy […]
🌉 bridged from https://mastodon.social/@Thayer on the fediverse by https://fed.brid.gy/
NLP / CSS PhD at Berkeley I School. I develop computational methods to study culture as a social language.
Incoming faculty at the Max Planck Institute for Software Systems
Postdoc at UW, working on Natural Language Processing
Recruiting PhD students!
🌐 https://lasharavichander.github.io/




















