
These Travel Influencers Don’t Want Freebies. They’re A.I.
This NYT story about A.I. travel avatars is being treated as a novelty. “Synthetic influencers are here!”
But the underlying platform architecture is the same. What’s changing is how efficiently actors can exploit it.
A.I. influencers simply remove the human bottlenecks.
09.12.2025 13:54 —
👍 6
🔁 1
💬 2
📌 0

Fantastic talk by Hopkins Medicine's Peter Najjar at the @jhumceh.bsky.social symposium on Human + AI to redefine the standard of care in medicine.
What can AI do to improve quality and safety in medicine?
08.12.2025 17:27 —
👍 2
🔁 1
💬 0
📌 0


Loving the “Pitch a problem” session at the Johns Hopkins Symposium on Engineering in Healthcare. Lots of animated conversations! @jhumceh.bsky.social
08.12.2025 15:32 —
👍 2
🔁 2
💬 0
📌 1

Headshots of Mark Dredze, Jason Eisner, Peter Kazanzides, and Tom Lippincott.
Congratulations to CS faculty @mdredze.bsky.social, Jason Eisner, Peter Kazanzides, and @tom-lippincott.bsky.social
on their @jhu.edu Nexus Awards! Learn more about their funded projects here: www.cs.jhu.edu/news/compute...
09.09.2025 16:23 —
👍 5
🔁 1
💬 0
📌 0
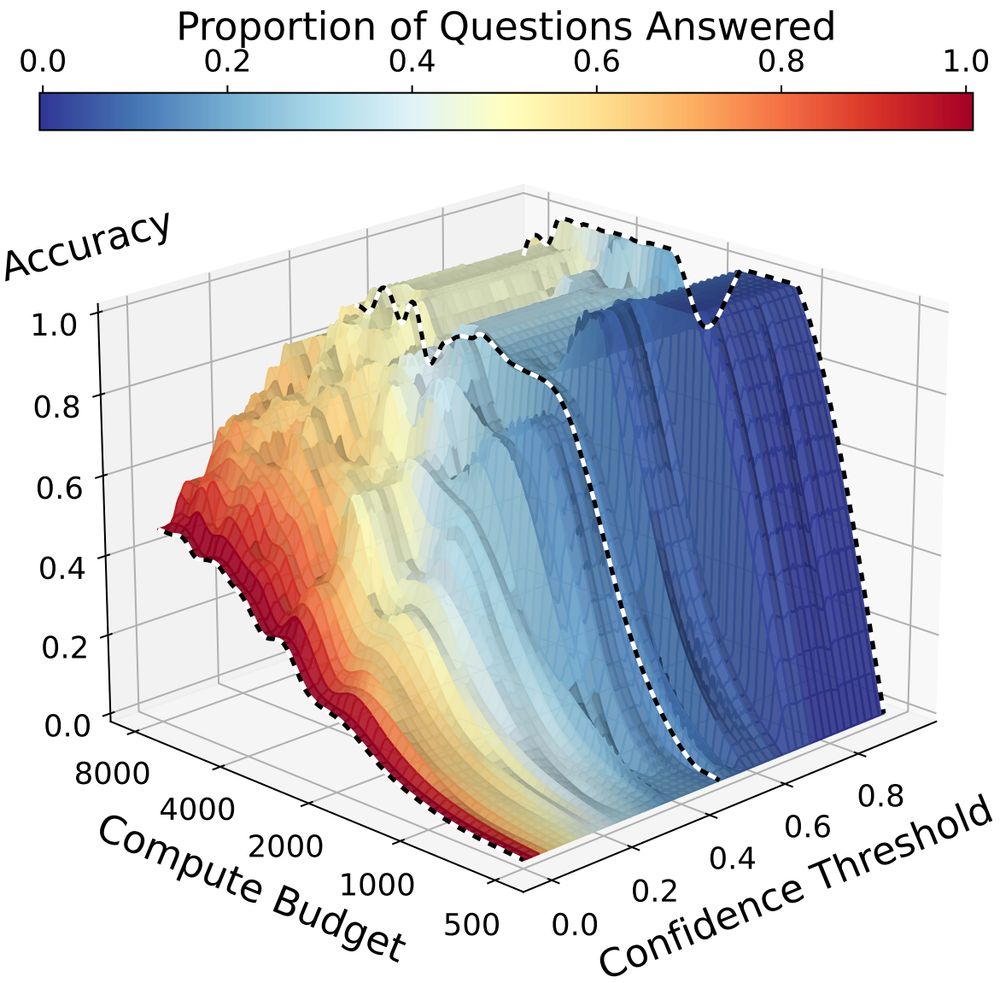
🚨 You are only evaluating a slice of your test-time scaling model's performance! 🚨
📈 We consider how models’ confidence in their answers changes as test-time compute increases. Reasoning longer helps models answer more confidently!
📝: arxiv.org/abs/2502.13962
20.02.2025 15:14 —
👍 14
🔁 10
💬 1
📌 1

I know I can improve my ARR reviews, but there really is no need for name calling. 😁
05.02.2025 14:13 —
👍 19
🔁 0
💬 1
📌 0
Helpful
Insightful
Probing
Valuable
Thoughtful
Illuminating
Constructive
In author feedback, these are synonyms for "we hate your review."
30.01.2025 07:24 —
👍 1
🔁 0
💬 0
📌 0
Do reviewers purposely write confusing reviews with typos to demonstrate that the review wasn't written by a LLM?
27.01.2025 23:42 —
👍 2
🔁 0
💬 0
📌 0
Golden idea for an NLP paper: a group of llamas is called a "cria herd".
That would make a great name for a LLM method, model, or paper.
Just remember to acknowledge me in your paper.
You're welcome.
24.01.2025 21:39 —
👍 9
🔁 0
💬 0
📌 0
Idea for GenAI app: rewrite click bait headlines to normal headlines in the browser.
Input: you’ll never guess this one company organizing the best deals of the year
Output: Amazon has a modest sale on phone chargers
21.01.2025 19:41 —
👍 23
🔁 2
💬 2
📌 0
Good idea!
20.01.2025 19:10 —
👍 0
🔁 0
💬 0
📌 0
The ARR submission checklist is already pretty extensive, but I suggest we add an additional question:
"I certify that I know the difference between \citet and \citep."
20.01.2025 14:49 —
👍 22
🔁 1
💬 1
📌 1

ARR: Reviews are due today.
Me:
20.01.2025 13:29 —
👍 1
🔁 0
💬 0
📌 0

I feel seen. This is why I always access my API keys from my laptop.
17.01.2025 19:50 —
👍 10
🔁 1
💬 0
📌 1

Do you have any of those fortune cookies that mock academics?
Sure!
14.01.2025 22:19 —
👍 6
🔁 0
💬 1
📌 0

Starting a new year and reflecting on how lucky I am to work at @hopkinsengineer.bsky.social with amazing people @jhucompsci.bsky.social @jhuclsp.bsky.social.
I was promoted to full professor in 2023, and my students presented me with this amazing poster of current and former PhD students.
02.01.2025 17:40 —
👍 12
🔁 2
💬 0
📌 0

AI Ethics and Safety — A Contradiction in Terms?
Podcast Episode · On with Kara Swisher · 01/02/2025 · 53m
Listen to @karaswisher.bsky.social's new podcast where she interviews @ruchowdh.bsky.social, @ghadfield.bsky.social and me about AI Ethics and Safety. The podcast was recorded before a live audience at @jhu.edu Bloomberg Center.
podcasts.apple.com/us/podcast/a...
02.01.2025 17:38 —
👍 2
🔁 0
💬 0
📌 0

Examining the generated QA pairs, you can really see the difference. Our generations (bottom) look harder and more interesting.
Try our strategy for your synthetic generation task? Check out our paper, being presented at #ML4H2024 .
arxiv.org/abs/2412.04573
22.12.2024 16:01 —
👍 2
🔁 0
💬 0
📌 0

Training a Clinical QA system on our data gives big improvements, whether we generate data from Llama or GPT-4o. These improvements are both in F1 and any overlap between the extracted and true answers.
22.12.2024 16:01 —
👍 1
🔁 0
💬 1
📌 0
The generated pair has a lot of advantages: it doesn't use the same language as the report, it includes harder questions, and the answers are sometimes not in the report (unanswerable questions.) The result? Harder, more diverse and more realistic QA pairs.
22.12.2024 16:01 —
👍 1
🔁 0
💬 1
📌 0
Second, we use a summarize-then-generate strategy. The LLM first summarizes a given clinical record in a structured format. The summary keeps the key points but loses the details, such as specific terminology and content. We then use the summary to generate a new QA pair.
22.12.2024 16:01 —
👍 0
🔁 0
💬 1
📌 0
We explore two strategies. First, we craft instructions to encourage QA diversity. We formulate these as constraints on the answers to the questions. It helps, but we need more.
22.12.2024 16:01 —
👍 0
🔁 0
💬 1
📌 0
We can ask an LLM to write QA pairs, but they turn out to be too easy and repetitive. They don't come close to what you can get with real data. We need more diverse data! Typical methods (e.g. annealing) don't work. What can we do?
22.12.2024 16:01 —
👍 0
🔁 0
💬 1
📌 0

Paper at #ML42024!
Clinical QA can help doctors find critical information in patient records. But where do we get training data for these systems? Generating this data from an LLM is hard. 🧵
22.12.2024 16:01 —
👍 3
🔁 0
💬 1
📌 0

It turns out that when you have just a little supervised data, the models trained on more data and tasks, even when out of domain, do BETTER on the new clinical domain.
22.12.2024 15:58 —
👍 0
🔁 0
💬 1
📌 0
Maybe the real advantage for domain-tuned models lies in the low resource setting. With lots of supervised data, an out of domain model can do well. What about with just a few training examples?
22.12.2024 15:58 —
👍 0
🔁 0
💬 1
📌 0

We try a new clinical task and dataset/domain. In this case, the clinical T5 benefits disappear.
22.12.2024 15:58 —
👍 0
🔁 0
💬 1
📌 0



