Found a hack for bookmark feature, just repost it😂
25.11.2024 18:16 — 👍 3 🔁 0 💬 1 📌 0
Check out Pygame_spiel by @giogix2.bsky.social !
This is a Pygame-based library to play games from the OpenSpiel suite against AI agents. 🤩😍
github.com/giogix2/pyga...
25.11.2024 18:07 — 👍 25 🔁 3 💬 1 📌 1
Migrating to Bluesky feels like upgrading your codebase to that new software in the market. It's painful, but you know you will have to do it at some point.
24.11.2024 12:24 — 👍 4 🔁 1 💬 1 📌 0
You just witnessed the birth of Skynet
24.11.2024 08:47 — 👍 0 🔁 0 💬 0 📌 0
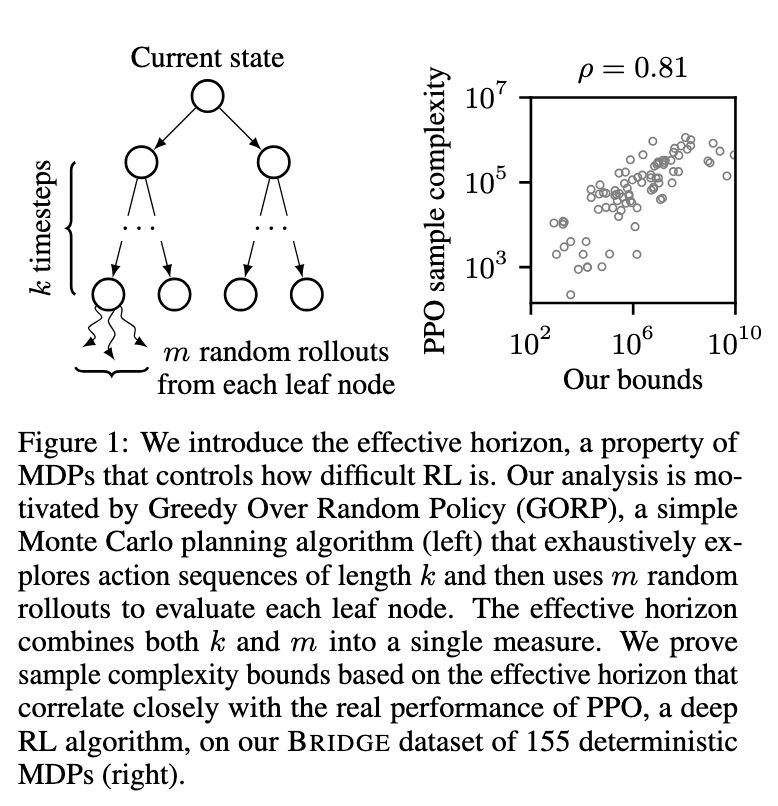
e introduce the effective horizon, a property of
MDPs that controls how difficult RL is. Our analysis is mo-
tivated by Greedy Over Random Policy (GORP), a simple
Monte Carlo planning algorithm (left) that exhaustively ex-
plores action sequences of length k and then uses m random
rollouts to evaluate each leaf node. The effective horizon
combines both k and m into a single measure. We prove
sample complexity bounds based on the effective horizon that
correlate closely with the real performance of PPO, a deep
RL algorithm, on our BRIDGE dataset of 155 deterministic
MDPs (right).
Kind of a broken record here but proceedings.neurips.cc/paper_files/...
is totally fascinating in that it postulates two underlying, measurable structures that you can use to assess if RL will be easy or hard in an environment
23.11.2024 18:18 — 👍 151 🔁 28 💬 8 📌 2
👋
24.11.2024 06:55 — 👍 1 🔁 0 💬 0 📌 0
Great list!! Could you add me?
I work on Multi-Agent Reinforcement Learning and it's applications in robotics. Would love to connect with community.
23.11.2024 12:58 — 👍 0 🔁 0 💬 0 📌 0
This summer, I collaborated with Project Mesa to create Mesa-RL framework that seamlessly integrates multi-agent reinforcement learning into Mesa's agent-based modeling environments. 🤖🌍
Go try RL with your social agent models!
Link - github.com/projectmesa/...
#ReinforcementLearning #MultiAgent
23.11.2024 12:47 — 👍 1 🔁 0 💬 0 📌 0
Great List! Would love to be added and connect with the community.
23.11.2024 07:29 — 👍 1 🔁 0 💬 0 📌 0
I work in robot learning. Would love to be added in the list.
21.11.2024 22:24 — 👍 1 🔁 0 💬 0 📌 0
Hello👋, Would love to be added.
21.11.2024 22:22 — 👍 0 🔁 0 💬 1 📌 0
Hi, Thanks for the list.
Would love to be added to this list. I work on robot learning and its applications.
21.11.2024 22:07 — 👍 1 🔁 0 💬 1 📌 0
Great List!!
Would love to be added @chrispaxton.bsky.social
21.11.2024 21:59 — 👍 0 🔁 0 💬 0 📌 0
By chaining a VLM and LLM in a bi-level framework, we use the “chain rule” to guide reward search directly from video demos.
This work was done under guidance of Prof. Wanxin Jin and Prof. Zhorang Wang at Intelligent Robotics and Interactive Systems (IRIS) Lab, Arizona State University.
21.11.2024 19:39 — 👍 0 🔁 0 💬 0 📌 0
Can robots learn skills from YouTube without complex video processing? Our LLM-driven bi-level programming shows it’s possible! Check out our RL agents learning skills from their biological counterparts!💡
Preprint: arxiv.org/abs/2410.09286
#ReinforcementLearning #LLM #Robotics #AI
21.11.2024 19:31 — 👍 1 🔁 0 💬 1 📌 0
This was work with my great colleagues Harsh Mahesheka, Jan Ole von Hartz, Tim Welschehold and Abhinav Valada at the Technische Fakultät der Universität Freiburg, University of Freiburg.
21.11.2024 19:21 — 👍 0 🔁 0 💬 0 📌 0
By modularizing commands, the operator can fully focus on the task relevant end-effector motions. This even enables kinesthetic teaching of mobile manipulators in cluttered environments. We show that this allows us to rapidly learn whole-body mobile manipulation skills with less than ten minutes.
21.11.2024 19:21 — 👍 0 🔁 0 💬 1 📌 0
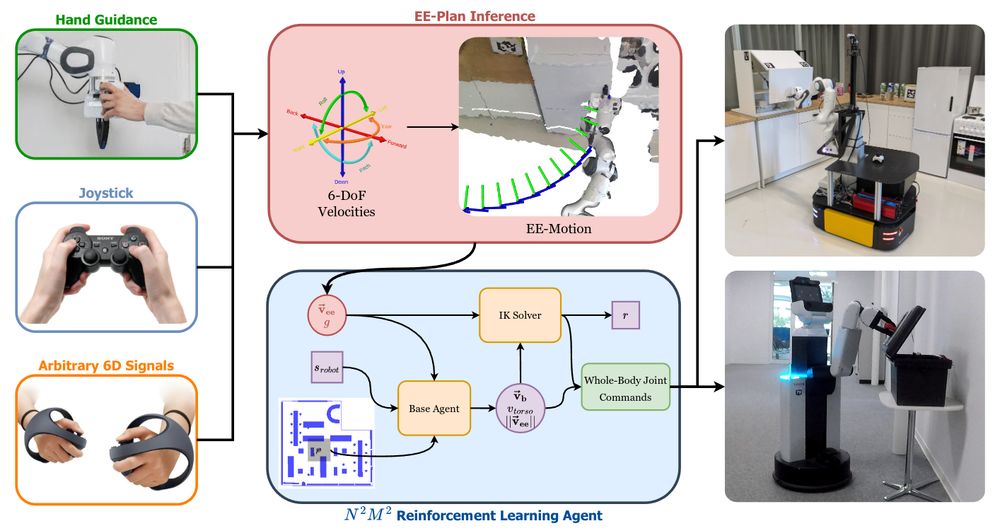
Can we operate mobile manipulators without expensive exoskeletons or tracking setups? 📜
In our latest work, Zero-Cost Whole-Body Teleoperation for Mobile Manipulation, we do exactly this.
Website and full videos: moma-teleop.cs.uni-freiburg.de
Arxiv: arxiv.org/abs/2409.150...
#AI #Robotics
21.11.2024 19:03 — 👍 0 🔁 1 💬 1 📌 0
I’m an Electrical Engineering student at IIT Varanasi, on a mission to teach robots human-like skills. Mimicking the most complex machine—us—is no small feat, but reinforcement learning makes it exciting (and intuitive!). 🚀🤖
#AI #ReinforcementLearning #Robotics
21.11.2024 18:52 — 👍 1 🔁 0 💬 0 📌 0
A starter pack of starter packs:
Robotics and AI go.bsky.app/DfAoaJ1
Computer Vision go.bsky.app/PkAKJu5
Computer Graphics Research go.bsky.app/ckQ1u9
Grumpy Machine Learners go.bsky.app/6ddpivr
Reinforcement Learning go.bsky.app/3WPHcHg
19.11.2024 04:36 — 👍 96 🔁 29 💬 7 📌 3
Assistant Professor, Robotics Institute, Carnegie Mellon University
https://ichnow.ski/
Information and updates about RLC 2025 at the University of Alberta from Aug. 5th to 8th!
https://rl-conference.cc
San Diego Dec 2-7, 25 and Mexico City Nov 30-Dec 5, 25. Comments to this account are not monitored. Please send feedback to townhall@neurips.cc.
[bridged from https://blog.neurips.cc/ on the web: https://fed.brid.gy/web/blog.neurips.cc ]
Official account for IEEE/CVF Conference on Computer Vision & Pattern Recognition. Hosted by @CSProfKGD with more to come.
📍🌎 🔗 cvpr.thecvf.com 🎂 June 19, 1983
Official account for the IEEE/CVF International Conference on Computer Vision. #ICCV2025 Honolulu 🇺🇸 Co-hosted by @natanielruiz @antoninofurnari @yaelvinker @CSProfKGD
Official Account for the European Conference on Computer Vision (ECCV) #ECCV2026, Malmo 🇸🇪 Hosted by @jbhaurum and @CSProfKGD
International Conference on Learning Representations https://iclr.cc/
Curated feed of interesting and novel robotics papers.
See lists tab if you are into robotics research.
Starter pack -> https://go.bsky.app/SxrgryM
PhD student @ CMU Robotics Institute | Olin 24’
Working on dynamic manipulation, controls, optimization.
Building generally intelligent robots that *just work* everywhere, out of the box, at Berkeley AI Research (BAIR) and Meta FAIR.
Previously at NYU Courant, MIT and visiting researcher at Meta AI.
https://mahis.life/
linktr.ee/scottsrobots
I used to make friendly 3d-Printed Robots in Chicago
Now I'm taking a break from Robots and getting GameDev scratched off my bucket list.
A business analyst at heart who enjoys delving into AI, ML, data engineering, data science, data analytics, and modeling. My views are my own.
You can also find me at threads: @sung.kim.mw
Mostly posts about humanoid robots | Former Agility Robotics, NASA JSC + Purdue | he/him | nathan-peterman.com
Asst. Prof. at the University of Pennsylvania, part of the GRASP Lab. PI of the Dynamic Autonomy and Intelligent Robotics Lab. https://dair.seas.upenn.edu
AI for Robotics at @HuggingFace 🤗
Focusing on @LeRobotHF




















