

Up next on stage, Dr. @edoardo-ponti.bsky.social ( @edinburgh-uni.bsky.social / NVIDIA)
🎤 “Adaptive Units of Computation: Towards Sublinear-Memory and Tokenizer-Free Foundation Models”
Fascinating glimpse into the next gen of foundation models.
#FoundationModels #NLP #TokenizerFree #ADSAI2025
09.06.2025 13:16 — 👍 2 🔁 1 💬 1 📌 0
Thanks to the amazing collaborators Adrian Łańcucki, Konrad Staniszewski, and Piotr Nawrot!
It was amazing to spend a year at NVIDIA as a visiting professor!
arXiv: arxiv.org/pdf/2506.05345
Code and models coming soon!
06.06.2025 12:33 — 👍 0 🔁 0 💬 0 📌 0

🏆 We evaluate inference-time hyper-scaling on DeepSeek R1-distilled models of different sizes, increasing accuracy on maths, science, and coding by up to 15 points for a given budget.
06.06.2025 12:33 — 👍 0 🔁 0 💬 1 📌 0

💡The idea behind DMS is to *train* existing LLMs to evict tokens from the KV cache, while delaying the eviction some time after the decision.
This allows LLMs to preserve information while reducing latency and memory size.
06.06.2025 12:33 — 👍 0 🔁 0 💬 1 📌 0

⚖️ The magic works only if accuracy is preserved even at high compression ratios.
Enter Dynamic Memory Sparsification (DMS), which achieves 8x KV cache compression with 1K training steps and retains accuracy better than SOTA methods.
06.06.2025 12:33 — 👍 0 🔁 0 💬 1 📌 0

🚀 By *learning* to compress the KV cache in Transformer LLMs, we can generate more tokens for the same compute budget.
This unlocks *inference-time hyper-scaling*
For the same runtime or memory load, we can boost LLM accuracy by pushing reasoning even further!
06.06.2025 12:33 — 👍 5 🔁 3 💬 1 📌 0
We propose Neurosymbolic Diffusion Models! We find diffusion is especially compelling for neurosymbolic approaches, combining powerful multimodal understanding with symbolic reasoning 🚀
Read more 👇
21.05.2025 10:57 — 👍 92 🔁 27 💬 4 📌 6

4) Finally, we introduce novel scaling laws for sparse attention and validate them on held-out results: evidence that our findings will likely hold true broadly.
Our insights demonstrate that sparse attention will play a key role in next-generation foundation models.
25.04.2025 15:39 — 👍 3 🔁 0 💬 1 📌 0

3) There is no single best strategy across tasks and phases.
However, on average Verticals-Slashes for prefilling and Quest for decoding are the most competitive. Context-aware, and highly adaptive variants are preferable.
25.04.2025 15:39 — 👍 1 🔁 0 💬 1 📌 0

2) Sparsity attainable while statistically guaranteeing accuracy preservation is higher during decoding ✍️ than prefilling 🧠, and correlates with model size in the former.
Importantly, for most settings there is at least one degraded task, even at moderate compressions (<5x).
25.04.2025 15:39 — 👍 1 🔁 0 💬 1 📌 0

1) For very long sequences, *larger and highly sparse models* are preferable to small, dense ones for the same FLOPS budget.
This suggests a strategy shift where scaling up model size must be combined with sparse attention to achieve an optimal trade-off.
25.04.2025 15:39 — 👍 1 🔁 0 💬 1 📌 0
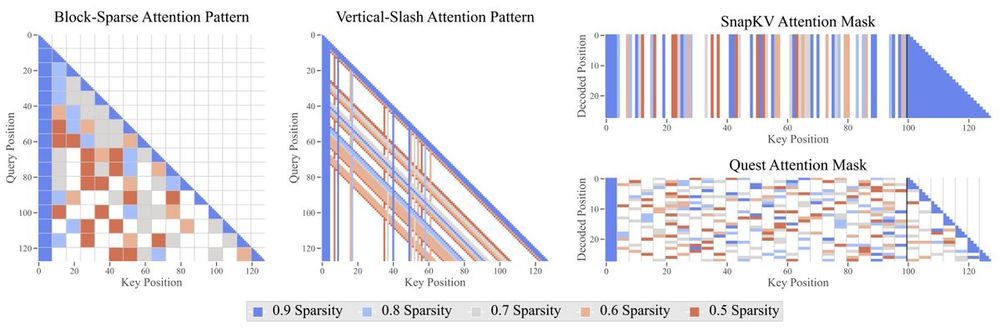
Sparse attention is one of the most promising strategies to unlock long-context processing and long-generation reasoning in LLMs.
We performed the most comprehensive study on training-free sparse attention to date.
Here is what we found:
25.04.2025 15:39 — 👍 24 🔁 6 💬 1 📌 0

🚀 Excited to welcome Dr. @edoardo-ponti.bsky.social to #ADSAI2025! Lecturer in NLP @edinburghuni.bsky.social , Affiliated Lecturer @cambridgeuni.bsky.social & Visiting Prof NVIDIA.
🎟️ Tickets for Advances in Data Science & AI Conference 2025 are live!
🔗Secure your spot: tinyurl.com/yurknk7y
#AI
01.04.2025 13:44 — 👍 4 🔁 3 💬 0 📌 0
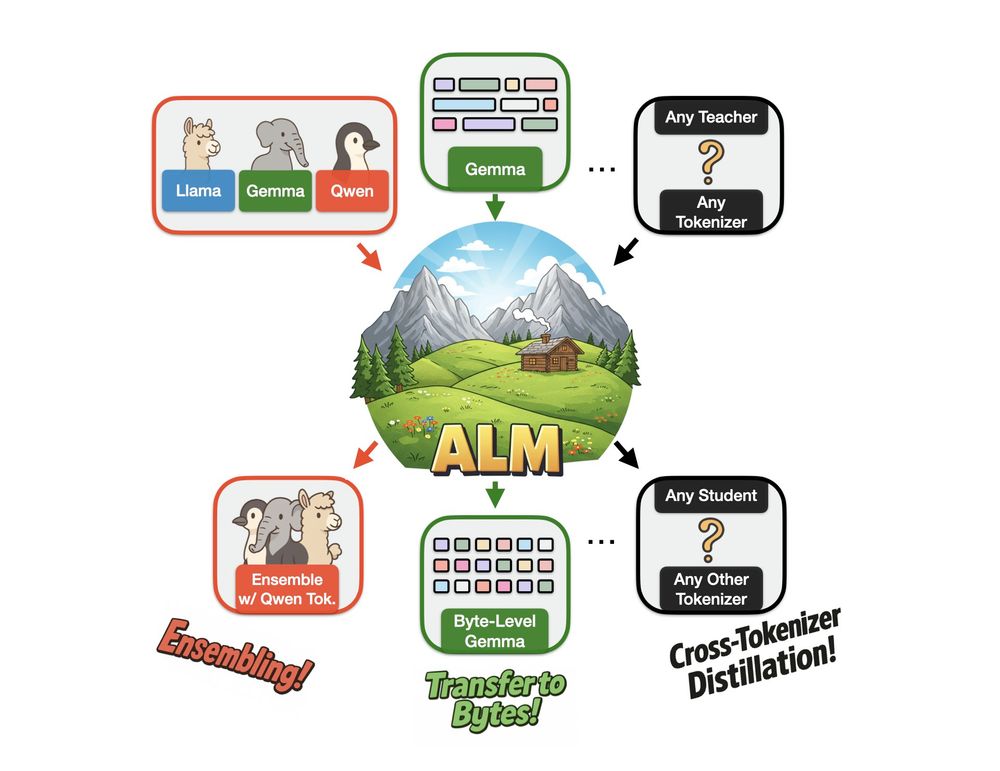
Image illustrating that ALM can enable Ensembling, Transfer to Bytes, and general Cross-Tokenizer Distillation.
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
02.04.2025 06:36 — 👍 26 🔁 14 💬 1 📌 0
I have a scholarship for a PhD in efficient memory and tokenization in LLM architectures at
@edinburgh-uni.bsky.social!
Eligibility: UK home fee status
Starting date: flexible, from July 2025 onwards.
informatics.ed.ac.uk/study-with-u...
Please contact me if you're interested!
31.01.2025 12:20 — 👍 6 🔁 4 💬 0 📌 0

We're hiring a lecturer or reader in embodied NLP at the University of Edinburgh!
Deadline: 31 Jan 2025
Call for applications: elxw.fa.em3.oraclecloud.com/hcmUI/Candid...
22.12.2024 09:46 — 👍 29 🔁 11 💬 0 📌 0

A Grounded Typology of Word Classes
Hosted on the Open Science Framework
What's in the future?
- Richer proxies for meaning, including a temporal dimension and internal agent states
- The study of grammaticalization under the lens of groundedness
We release an extensive dataset to support these studies: osf.io/bdhna/
20.12.2024 20:30 — 👍 3 🔁 0 💬 0 📌 0
We focus on the groundedness of lexical classes and find that it
- follows a continuous cline cross-linguistically: nouns > adjectives > verbs
- is non-zero even for functional classes (e.g., adpositions)
- is contextual, so agrees with psycholinguistic norms only in part
20.12.2024 20:30 — 👍 0 🔁 0 💬 1 📌 0
We leverage advances in multilingual and multimodal foundation models to quantify their surprisal for both form alone and form given function
Their difference (pointwise mutual information) corresponds to the groundedness of a word: the remaining surprisal once function is known
20.12.2024 20:30 — 👍 0 🔁 0 💬 1 📌 0
**Grounded typology**: a new paradigm.
Traditionally, linguists posit functions to compare forms in different languages; however, these are aprioristic and partly arbitrary.
Instead, we resort to perceptual modalities (like vision) as measurable proxies for function.
20.12.2024 20:30 — 👍 4 🔁 0 💬 1 📌 0
Two considerations:
1) reusing / interpolating old token is reminiscent of our FOCUS baseline. Unfortunately it degrades performance as even identical tokens may change their function.
2) you incur a large overhead for calculating the co-occurrence matrix for every new tokenizer.
12.12.2024 22:55 — 👍 0 🔁 0 💬 1 📌 0
Two amazing papers from my students at #NeurIPS today:
⛓️💥 Switch the vocabulary and embeddings of your LLM tokenizer zero-shot on the fly (@bminixhofer.bsky.social)
neurips.cc/virtual/2024...
🌊 Align your LLM gradient-free with spectral editing of activations (Yifu Qiu)
neurips.cc/virtual/2024...
12.12.2024 17:45 — 👍 46 🔁 8 💬 2 📌 0
ML is the fox?
04.12.2024 22:29 — 👍 3 🔁 0 💬 1 📌 0
Plus Edinburgh gets the Saltire, but Cambridge gets the Union Jack. Vexillologists are in shambles
04.12.2024 16:55 — 👍 5 🔁 0 💬 2 📌 0
Several incredible NeurIPS tutorials this year. Worth navigating through the Swifties.
21.11.2024 22:01 — 👍 39 🔁 6 💬 1 📌 0
Thanks, Sasha! Your tutorials are a great source of inspiration for us.
22.11.2024 11:53 — 👍 1 🔁 0 💬 0 📌 0
Associate Professor at the University of Trento, Italy
🏛️ educator, philosopher, strategist, museum nerd
👩🏼🏫 Art & Humanities, Teachers College, Columbia University
⌛️ MoMA/PS1, The Getty, MOCA
🏫 RSA | ICOM | AERA | AAHE | PES | INPE | JDS | IPPA | APA
#aesthetics #museums #philsky #edusky #academicsky #artsky
NLP PhD candidate @ University of Edinburgh
Computational Linguistics | Typology | Morphology | Multimodal NLP | Cognitive Science
(Interpretability + Neurosymbolic models sometimes)
Assistant Professor & Canada CIFAR AI Chair, University of Waterloo & Vector Institute | Excited about "grounding" in any form | Feeder of 🐈 | 🏸, 🏐, 🏂 | she/her
Assistant Professor at Bocconi University in MilaNLP group • Working in #NLP, #HateSpeech and #Ethics • She/her • #ERCStG PERSONAE
Ph.D. in NLP Interpretability from Mila. Previously: independent researcher, freelancer in ML, and Node.js core developer.
Associate Professor of Natural Language Processing & Explainable AI, University of Amsterdam, ILLC
website: https://t.co/ml5yPJjZLO Natural Language Processing and Machine Learning researcher at the University of Cambridge. Member of the PaNLP group: https://www.panlp.org/ and fellow of Fitzwilliam College.
Sr Mgr & Research Scientist @ServiceNowRSRCH, Montreal
Researcher at Google and CIFAR Fellow, working on the intersection of machine learning and neuroscience in Montréal (academic affiliations: @mcgill.ca and @mila-quebec.bsky.social).
🎓 CS Prof at UCLA
🧠 Researching reasoning and learning in artificial intelligence: tactable deep generative models, probabilistic circuits, probabilistic programming, neurosymbolic AI
https://web.cs.ucla.edu/~guyvdb/
PhD student at Cambridge University. Causality & language models. Passionate musician, professional debugger.
pietrolesci.github.io
Machine Learning @ University of Edinburgh | AI4Science | optimization | numerics | networks | co-founder @ MiniML.ai | ftudisco.gitlab.io
Assistant professor at Yale Linguistics. Studying computational linguistics, cognitive science, and AI. He/him.
Research Scientist at Google DeepMind
https://e-bug.github.io
PhD student in ILCC (NLP) program at the University of Edinburgh
Machine Learner by day, 🦮 Statistician at ❤️
In search of statistical intuition for modern ML & simple explanations for complex things👀
Interested in the mysteries of modern ML, causality & all of stats. Opinions my own.
https://aliciacurth.github.io
Research Director, Founding Faculty, Canada CIFAR AI Chair @VectorInst.
Full Prof @UofT - Statistics and Computer Sci. (x-appt) danroy.org
I study assumption-free prediction and decision making under uncertainty, with inference emerging from optimality.
#probabilistic-ml #circuits #tensor-networks
PhD student @ University of Edinburgh
https://loreloc.github.io/
Assistant Professor, University of Copenhagen; interpretability, xAI, factuality, accountability, xAI diagnostics https://apepa.github.io/



























