Had a really great and fun time with @yanai.bsky.social, Niloofar Mireshghallah, and Reza Shokri discussing memorisation at the @l2m2workshop.bsky.social panel. Thanks to the entire organising team and attendees for making this such a fantastic workshop! #ACL2025
02.08.2025 17:02 —
👍 8
🔁 1
💬 0
📌 0
@philipwitti.bsky.social will be presenting our paper "Tokenisation is NP-Complete" at #ACL2025 😁 Come to the language modelling 2 session (Wednesday morning, 9h~10h30) to learn more about how challenging tokenisation can be!
27.07.2025 09:41 —
👍 7
🔁 3
💬 0
📌 0
Just arrived in Vienna for ACL 2025 🇦🇹 Excited to be here and to finally meet so many people in person!
We have several papers this year and many from @milanlp.bsky.social are around, come say hi!
Here are all the works I'm involved in ⤵️
#ACL2025 #ACL2025NLP
27.07.2025 10:29 —
👍 20
🔁 4
💬 1
📌 0
Also, got burning questions about memorisation? Send them my way—we'll make sure to pose them to our panelists during the workshop!
27.07.2025 06:41 —
👍 0
🔁 0
💬 0
📌 0
Headed to Vienna for #ACL2025 to present our tokenisation bias paper and co-organise the L2M2 workshop on memorisation in language models. Reach out to chat about tokenisation, memorisation, and all things pre-training (esp. data-related topics)!
27.07.2025 06:40 —
👍 20
🔁 2
💬 2
📌 0
Also, we find that:
– Tokenisation bias appears early in training
– Doesn’t go away as models improve or with scale
We hope this approach can support:
– More principled vocabulary design
– Better understanding of generalisation trade-offs
– Fairer and more stable LMs
05.06.2025 10:43 —
👍 1
🔁 0
💬 1
📌 0
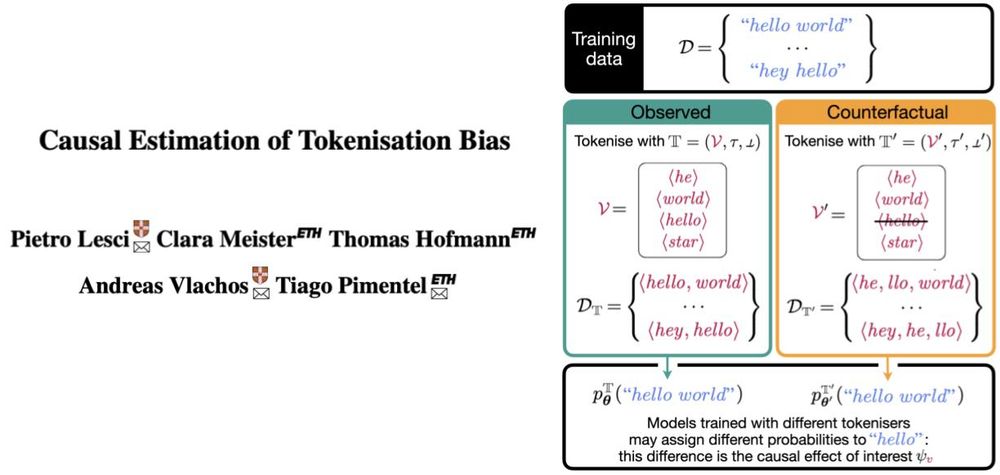
As our main result, we find that when a token is in a model’s vocabulary—i.e., when its characters are tokenised as a single symbol—the model may assign it up to 17x more probability than if it had been split into two tokens instead
05.06.2025 10:43 —
👍 2
🔁 1
💬 1
📌 0

The trick: tokenisers build vocabs incrementally up to a fixed size (e.g., 32k). This defines a "cutoff": tokens near it are similar (e.g., frequency), but those inside appear as one while those outside as two symbols. Perfect setup for regression discontinuity! Details in 📄!
05.06.2025 10:43 —
👍 4
🔁 0
💬 1
📌 0
So, did we train thousands of models, with and without each token in our vocabulary? No! Our method works observationally! 👀📊
05.06.2025 10:43 —
👍 1
🔁 0
💬 1
📌 0
While intuitive, this question is tricky. We can’t just compare
1️⃣ in- vs. out-of-vocab words (like "hello" vs "appoggiatura") as they differ systematically, e.g., in frequency
2️⃣ different tokenisations (e.g., ⟨he,llo⟩or ⟨hello⟩) as the model only sees one during training
05.06.2025 10:43 —
👍 1
🔁 0
💬 2
📌 0
In our paper, we estimate a specific type of tokenisation bias: What’s the effect of including a token (e.g., ⟨hello⟩) in the tokeniser’s vocabulary on the log-probability this model assigns to its characters (“hello”)?
05.06.2025 10:43 —
👍 2
🔁 0
💬 1
📌 0
Most language models assign probabilities to raw strings (like "hello") by first tokenising them (like ⟨he, llo⟩ or ⟨hello⟩). Ideally, different tokenisations shouldn't change these models’ outputs. In practice, they do. We call this difference **tokenisation bias**
05.06.2025 10:43 —
👍 2
🔁 0
💬 1
📌 0
All modern LLMs run on top of a tokeniser, an often overlooked “preprocessing detail”. But what if that tokeniser systematically affects model behaviour? We call this tokenisation bias.
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
05.06.2025 10:43 —
👍 63
🔁 8
💬 1
📌 2
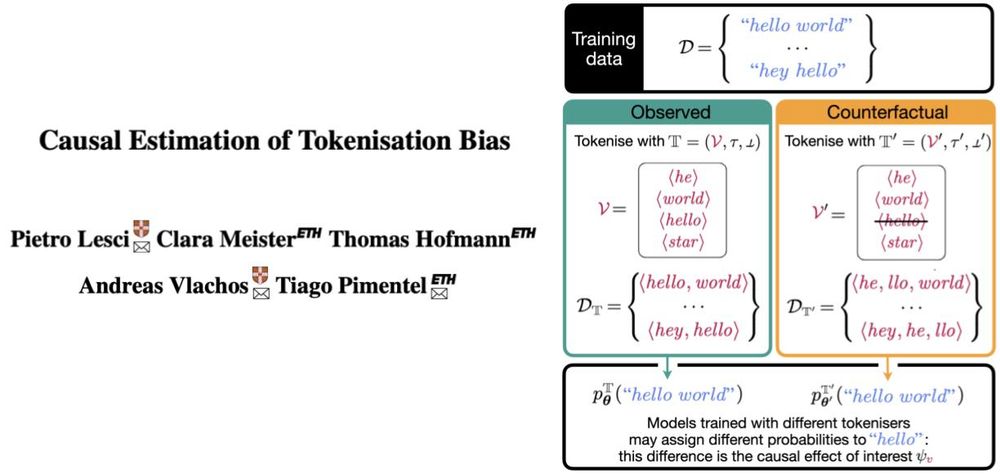
Title of paper "Causal Estimation of Tokenisation Bias" and schematic of how we define tokenisation bias, which is the causal effect we are interested in.
A string may get 17 times less probability if tokenised as two symbols (e.g., ⟨he, llo⟩) than as one (e.g., ⟨hello⟩)—by an LM trained from scratch in each situation! Our new ACL paper proposes an observational method to estimate this causal effect! Longer thread soon!
04.06.2025 10:51 —
👍 53
🔁 9
💬 1
📌 3

Inline citations with only first author name, or first two co-first author names.
If you're finishing your camera-ready for ACL or ICML and want to cite co-first authors more fairly, I just made a simple fix to do this! Just add $^*$ to the authors' names in your bibtex, and the citations should change :)
github.com/tpimentelms/...
29.05.2025 08:53 —
👍 85
🔁 23
💬 4
📌 0

ACL 2025 Workshop L2M2 ARR Commitment
Welcome to the OpenReview homepage for ACL 2025 Workshop L2M2 ARR Commitment
📢 @aclmeeting.bsky.social notifications have been sent out, making this the perfect time to finalize your commitment. Don't miss the opportunity to be part of the L2M2 workshop!
🔗 Commit here: openreview.net/group?id=acl...
🗓️ Deadline: May 20, 2025 (AoE)
#ACL2025 #NLProc
16.05.2025 14:57 —
👍 1
🔁 1
💬 0
📌 0
I'm truly honoured that our paper "Causal Estimation of Memorisation Profiles" has been selected as the Paper of the Year by @cst.cam.ac.uk 🎉
I thank my amazing co-authors Clara Meister, Thomas Hofmann, @tpimentel.bsky.social, and my great advisor and co-author @andreasvlachos.bsky.social!
30.04.2025 04:10 —
👍 8
🔁 2
💬 1
📌 0
Big thanks to my co-authors: @ovdw.bsky.social, Max Müller-Eberstein, @nsaphra.bsky.social, @hails.computer, Willem Zuidema, and @stellaathena.bsky.social
22.04.2025 11:02 —
👍 2
🔁 0
💬 0
📌 0
Come find us at the poster session:
🗓️ Fri 25 Apr, 3:00–5:30 p.m. (+08)
📌 Hall 3 + Hall 2B, Poster n. 259
22.04.2025 11:02 —
👍 1
🔁 0
💬 1
📌 0
We find that:
📈 Language modelling is stable: consistent scaling laws for performance and info content.
📚 Steps 1k–10k form core of linguistic structure; 10k–100k bring the biggest jumps in performance.
🗺️ Training maps capture these phases and reveal outlier seeds early
22.04.2025 11:02 —
👍 1
🔁 0
💬 1
📌 0
We introduce PolyPythias: 50 training runs across 5 sizes (14M–410M) and 10 seeds to explore:
1️⃣ How stable is downstream performance?
2️⃣ How similar are the learned linguistic representations?
3️⃣ Do training dynamics reveal distinct phases, and can we spot issues early?
22.04.2025 11:02 —
👍 1
🔁 0
💬 1
📌 0
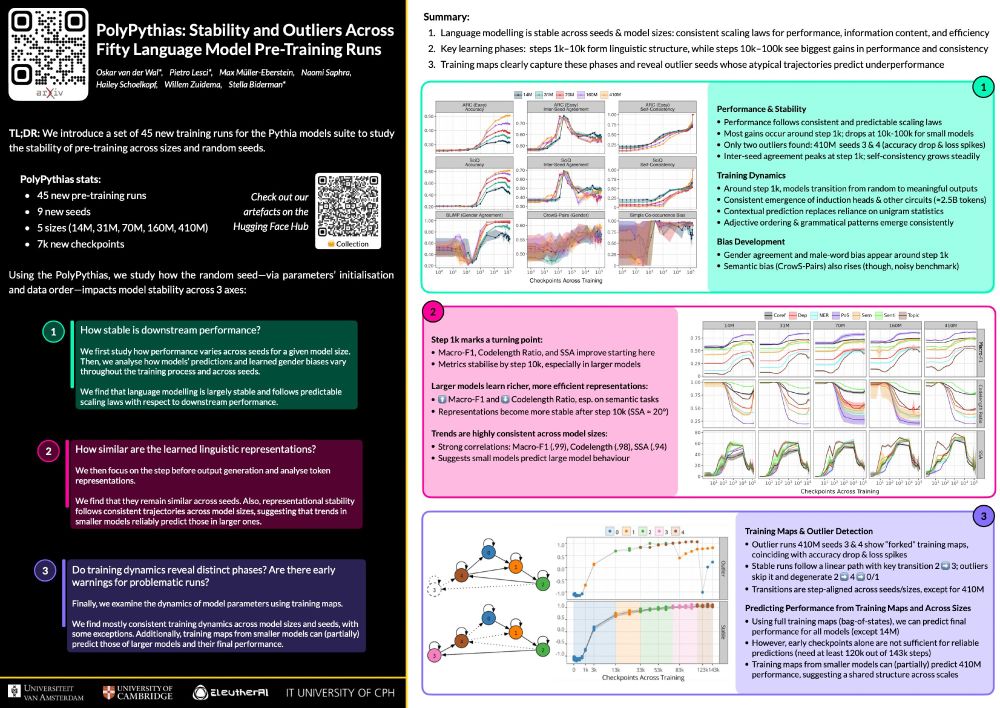
✈️ Headed to @iclr-conf.bsky.social — whether you’ll be there in person or tuning in remotely, I’d love to connect!
We’ll be presenting our paper on pre-training stability in language models and the PolyPythias 🧵
🔗 ArXiv: arxiv.org/abs/2503.09543
🤗 PolyPythias: huggingface.co/collections/...
22.04.2025 11:02 —
👍 6
🔁 3
💬 1
📌 0
The First Workshop on Large Language Model Memorization will be co-located at @aclmeeting.bsky.social in Vienna. Help us spread the word!
27.01.2025 21:53 —
👍 7
🔁 2
💬 0
📌 0
This year, when students of my optimization class were asking for references related to forward-backward mode autodiff, I didn't suggest books or articles: #JAX documentation was actually the best thing I've found! What's your go-to reference for this?
26.11.2024 03:15 —
👍 21
🔁 1
💬 2
📌 0

Paper screenshot and Figure 1 (c) with cumulative ablations for components of RealMLP-TD.
Can deep learning finally compete with boosted trees on tabular data? 🌲
In our NeurIPS 2024 paper, we introduce RealMLP, a NN with improvements in all areas and meta-learned default parameters.
Some insights about RealMLP and other models on large benchmarks (>200 datasets): 🧵
18.11.2024 14:15 —
👍 61
🔁 9
💬 1
📌 7
Anne Gagneux, Ségolène Martin, @quentinbertrand.bsky.social Remi Emonet and I wrote a tutorial blog post on flow matching: dl.heeere.com/conditional-... with lots of illustrations and intuition!
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
27.11.2024 09:00 —
👍 355
🔁 102
💬 12
📌 11
Amazing resource by @brandfonbrener.bsky.social and co-authors. They train and release (the last checkpoint of) >500 models with sizes 20M to 3.3B params and FLOPs 2e17 to 1e21 across 6 different pre-training datasets.
Bonus: They have evaluations on downstream benchmarks!
Great work! 🚀
27.11.2024 18:15 —
👍 1
🔁 0
💬 1
📌 0
Our lab is on Bluesky now: bsky.app/profile/camb... 🎉
25.11.2024 11:25 —
👍 7
🔁 1
💬 0
📌 0


