🤗 This project wouldn't have been possible without my incredible co-author team, @ccolas.bsky.social & @pyoudeyer.bsky.social
#LLM #AI #ProgramSynthesis #ICML2025
10.07.2025 16:04 — 👍 1 🔁 0 💬 0 📌 0
I’ll be at ICML next week—let’s chat if you’re interested in self-improving LLMs, program synthesis, ARC, or other related subjects.
10.07.2025 16:04 — 👍 0 🔁 0 💬 1 📌 0
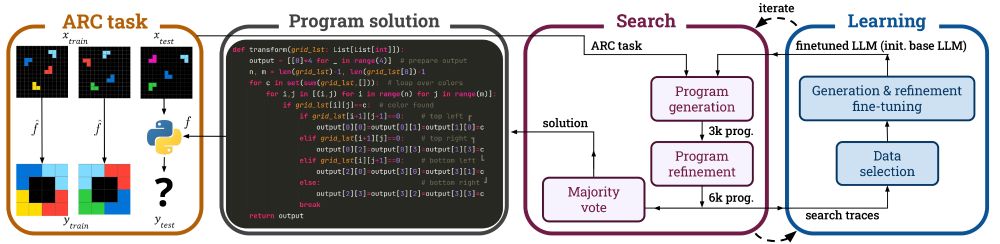
Self-Improving Language Models for Evolutionary Program Synthesis: A Case Study on ARC-AGI
Article about SOAR paper
Want to learn more? We've made everything public:
📗 Blog Post: julienp.netlify.app/posts/soar/
🤗 Models (7/14/32/72/123b) & Data: huggingface.co/collections/...
💻 Code: github.com/flowersteam/...
📄 Paper: icml.cc/virtual/2025...
10.07.2025 16:04 — 👍 0 🔁 0 💬 1 📌 0
🚀 **Broader Impact**: This isn't just about ARC puzzles. SOAR's framework could enhance program synthesis tasks where search-based LLM methods are limited by static model capabilities (FunSearch, AlphaEvolve, … )
10.07.2025 16:04 — 👍 0 🔁 0 💬 1 📌 0
🌟 **Test-Time Learning**: Even on new problems, SOAR continues improving by focusing on solutions that work well on the given examples. This enables real-time adaptation to novel challenges.
10.07.2025 16:04 — 👍 0 🔁 0 💬 1 📌 0
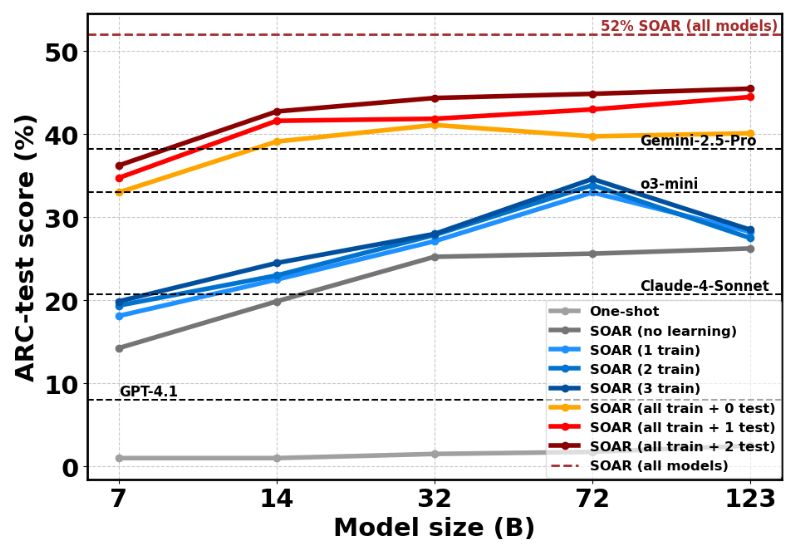
📈 **Results**:
- Qwen-7B model: 6% → 36% accuracy
- Qwen-32B model: 13% → 45% accuracy
- Mistral-Large-2: 20% -> 46% accuracy
- Combined ensemble: 52% on ARC-AGI test set
- Outperforms much larger models like o3-mini and Claude-4-Sonnet
10.07.2025 16:04 — 👍 1 🔁 0 💬 1 📌 0
🎯 Key Insight: Failed programs aren't useless! Through "hindsight relabeling," SOAR treats each failed program as the *correct* solution to a different (synthetic) problem. This massively expands the training data diversity.
10.07.2025 16:04 — 👍 0 🔁 0 💬 1 📌 0
🧠 **The Learning Process**: The system learns TWO skills simultaneously:
- **Sampling**: Generate better initial solutions
- **Refinement**: Enhance initial solutions
We also find that learning both together works better than specializing!
10.07.2025 16:04 — 👍 1 🔁 0 💬 1 📌 0
🔄 SOAR doesn't just search harder — it gets SMARTER. It alternates between:
- Evolutionary search: LLM samples and refines candidate programs.
- Hindsight learning: The model learns from all its search attempts, successes and failures, to fine-tune its skills for the next round.
10.07.2025 16:04 — 👍 0 🔁 0 💬 1 📌 0
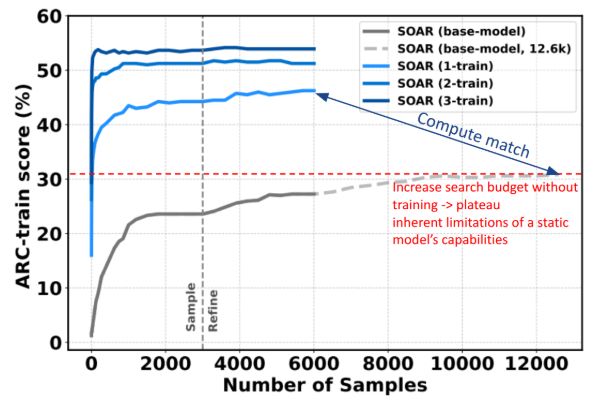
🔬 Why This Matters? Most coding tasks are too hard for even the best language models to solve in one shot. Traditional search methods help, but they hit a wall because the model’s abilities are fixed. SOAR breaks through this barrier by letting the model improve itself over time
10.07.2025 16:04 — 👍 0 🔁 0 💬 1 📌 0
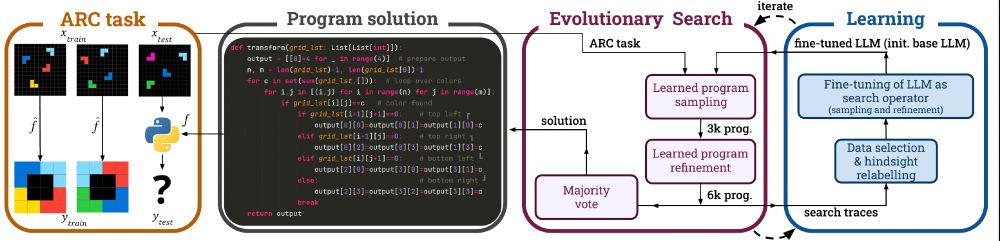
Introducing SOAR 🚀, a self-improving framework for prog synth that alternates between search and learning (accepted to #ICML!)
It brings LLMs from just a few percent on ARC-AGI-1 up to 52%
We’re releasing the finetuned LLMs, a dataset of 5M generated programs and the code.
🧵
10.07.2025 16:04 — 👍 1 🔁 0 💬 2 📌 1
A LLN - large language Nathan - (RL, RLHF, society, robotics), athlete, yogi, chef
Writes http://interconnects.ai
At Ai2 via HuggingFace, Berkeley, and normal places
Research Scientist at Google DeepMind, interested in multiagent reinforcement learning, game theory, games, and search/planning.
Lover of Linux 🐧, coffee ☕, and retro gaming. Big fan of open-source. #gohabsgo 🇨🇦
For more info: https://linktr.ee/sharky6000
Principal Researcher @ Microsoft Research.
Cognitive computational neuroscience & AI.
Writer. Nature wanderer.
www.momen-nejad.org
Interested in cognition and artificial intelligence. Research Scientist at Google DeepMind. Previously cognitive science at Stanford. Posts are mine.
lampinen.github.io
AI, RL, NLP, Games Asst Prof at UCSD
Research Scientist at Nvidia
Lab: http://pearls.ucsd.edu
Personal: prithvirajva.com
professor at university of washington and founder at csm.ai. computational cognitive scientist. working on social and artificial intelligence and alignment.
http://faculty.washington.edu/maxkw/
Asst. prof. at NUS. Scaling cooperative intelligence & infrastructure for an automated future. PhD @ MIT ProbComp / CoCoSci. Pronouns: 祂/伊
Researcher in robotics and machine learning (Reinforcement Learning). Maintainer of Stable-Baselines (SB3).
https://araffin.github.io/
assistant prof at USC Data Sciences and Operations; phd Cornell ORIE. data-driven decision-making, operations research/management, causal inference, algorithmic fairness/equity
angelamzhou.github.io
Host TalkRL Podcast, Aspiring RL researcher
AgFunder VC Head of Eng, Ex-MSFT, Waterloo computer engineering
Sunshine Coast BC Canada
Assistant Professor leading the AI, Law, & Society Lab @ Princeton
📚JD/PhD @ Stanford
Postdoc at @kthuniversity.bsky.social.
Past: @gaipslab.bsky.social; Sony AI.
Interested in all things RL and Multimodal.
miguelvasco.com
Professor at INF - @ufrgs.br | Ph.D. in Computer Science. I am interested in multi-policy reinforcement learning (RL) algorithms.
Personal page: https://lucasalegre.github.io
Research Scientist @ Google Deepmind. Opinions are my own.
minsukchang.com
Abolish the value function!
Assistant Prof of AI & Decision-Making @MIT EECS
I run the Algorithmic Alignment Group (https://algorithmicalignment.csail.mit.edu/) in CSAIL.
I work on value (mis)alignment in AI systems.
https://people.csail.mit.edu/dhm/
👩🏻🔬 Looking for positions in Europe! 💫 Postdoc @WashU, Neuroscience PhD @Princeton, researching cognitive control & decision making, #neurodivergent in computational psychiatry, she/her. Views my own. Stand Up for inclusive, accessible Science for everyone!
See(k)ing the surreal
Reinforcement learning + Robot learning (🤖 = 42) @ University of Freiburg 🇩🇪
Applying to PhDs 2025
#reinforcementlearning #robotics #causality #meditation #vegan
PhD. Student @ELLIS.eu @UniFreiburg with Thomas Brox and Cordelia Schmid
Understanding intelligence and cultivating its societal benefits
https://kifarid.github.io
Senior Research Scientist @MBZUAI. Focused on decision making under uncertainty, guided by practical problems in healthcare, reasoning, and biology.




















