
GitHub - ddidacus/mol-moe: Repository for: "Training Preference-Guided Routers for Molecule Generation"
Repository for: "Training Preference-Guided Routers for Molecule Generation" - ddidacus/mol-moe
Special thanks to Biogen and CIFAR for the support, and
@proceduralia.bsky.social + @pierrelucbacon.bsky.social
for their valuable supervision, and to the entire Mila community for their feedback, discussions, and support. Code, paper, and models are public: github.com/ddidacus/mol...
20.02.2025 19:43 —
👍 3
🔁 1
💬 0
📌 0
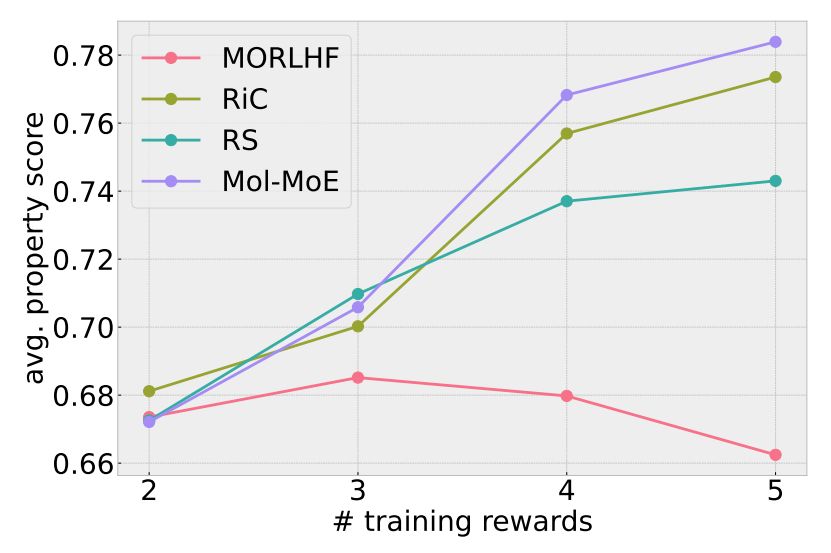
Mol-MoE improves with more property experts with a larger gain than classic merging and overall, it achieves the highest scores. Simple reward scalarization here does not work. We aim at further calibrating Mol-MoE and testing the performance on larger sets of objectives.
20.02.2025 19:43 —
👍 1
🔁 0
💬 1
📌 0

The model we obtain does achieve a smaller mean absolute error in generating compounds according to the provided properties, surpassing the alternative methods. Arguably, the learned routing functions can tackle task interference.
20.02.2025 19:43 —
👍 1
🔁 0
💬 1
📌 0
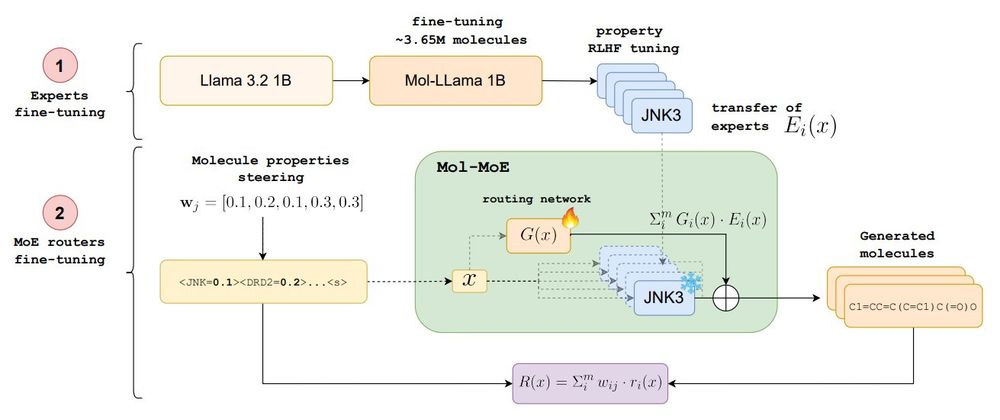
But the relationship between interpolation coefficients and properties isn’t strictly linear, needing a calibration function. Mol-MoE addresses this by training only the routers to predict optimal merging weights from prompts, enabling more precise control and less interference.
20.02.2025 19:43 —
👍 1
🔁 0
💬 1
📌 0
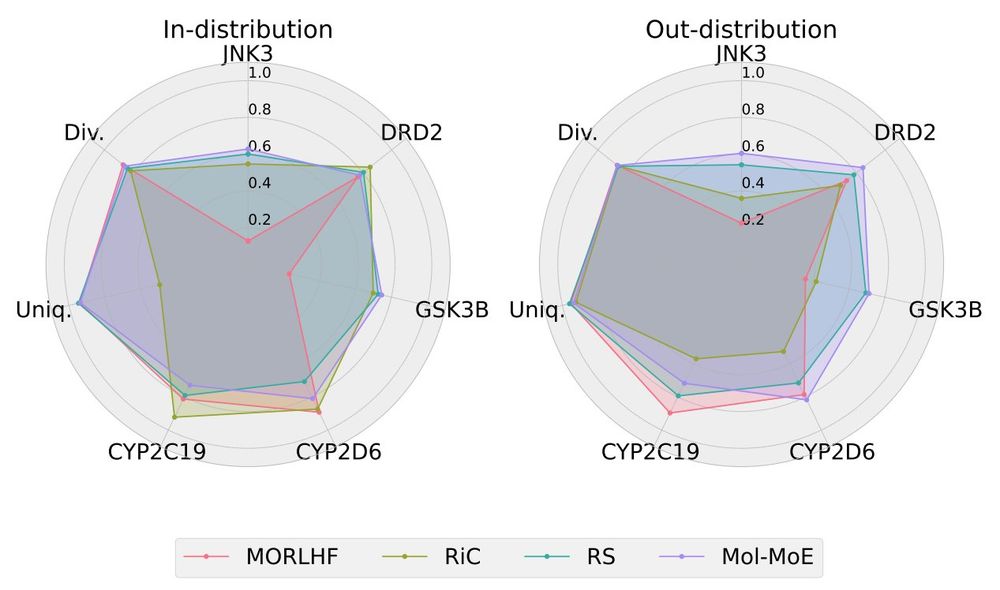
Think, think, think... what if we trained experts on single properties separately and leveraged model merging techniques to obtain a multi-property model? We re-implement rewarded soups and obtain a robust baseline capable of generating high-quality, out-of-distribution samples.
20.02.2025 19:43 —
👍 1
🔁 0
💬 1
📌 0
In our ablation studies, instruction-tuned models struggle with higher property values due to lack of explicit optimization. Even RL fine-tuning on multiple objectives can hit performance plateaus or declines, and balancing objectives requires re-training, limiting steerability.
20.02.2025 19:43 —
👍 1
🔁 0
💬 1
📌 0
Drug discovery inherently involves multi-objective optimization, requiring candidate molecules to not only bind effectively to target proteins, triggering a specific function, but also to meet safety and compatibility criteria to become drugs. Is supervised learning sufficient?
20.02.2025 19:43 —
👍 1
🔁 0
💬 1
📌 0
Molecule sequence models learn vast molecular spaces, but how to navigate them efficiently? We explored multi-objective RL, SFT, merging, but these fall short in balancing control and diversity. We introduce **Mol-MoE**: a mixture of experts for controllable molecule generation🧵
20.02.2025 19:43 —
👍 2
🔁 1
💬 1
📌 0
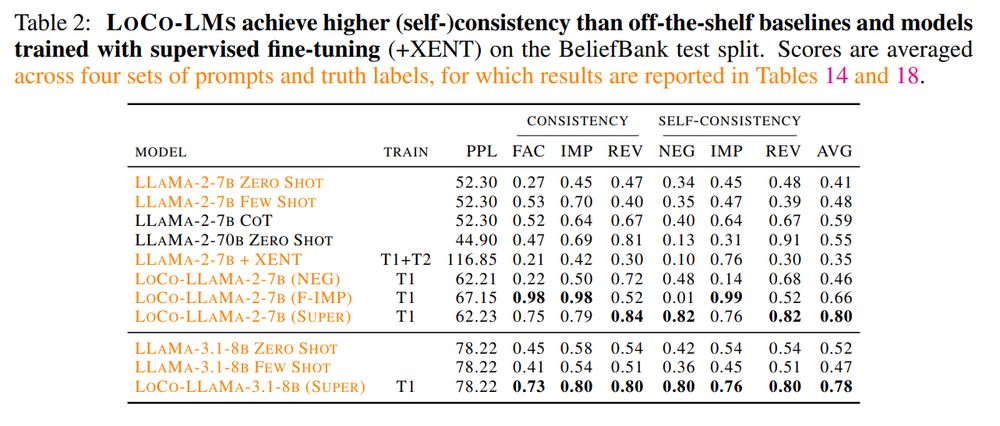
Our method makes LLaMa's knowledge more consistent to any given knowledge graph, by seeing only a portion of it! It can transfer logical rules to similar or derived concepts. As proposed by @ekinakyurek.bsky.social et al., you can use a LLM-generated KB to reason over its knowledge.
29.01.2025 23:41 —
👍 7
🔁 1
💬 2
📌 0

Yes! We propose to leverage the Semantic Loss as a regularizer: it maximizes the likelihood of world (model) assignments satisfying any given logical rule. We thus include efficient solvers in the training pipeline to efficiently perform model counting on the LLM's own beliefs.
29.01.2025 23:41 —
👍 3
🔁 0
💬 1
📌 0
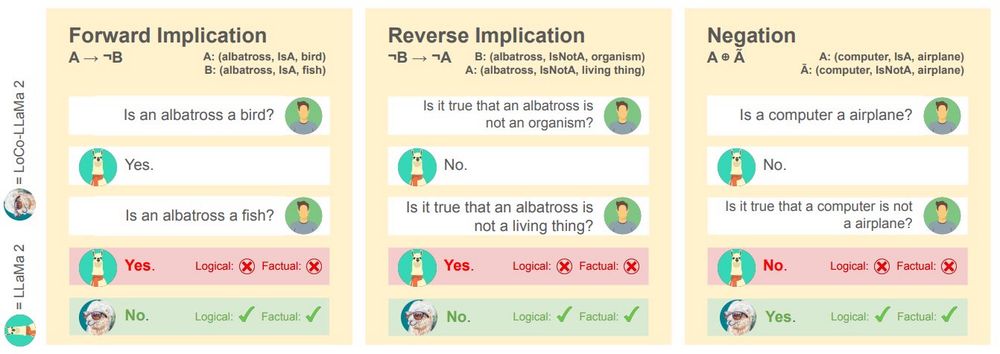
Various background works focus on instilling single consistency rules, e.g. A and not A can't be both true (negation, Burns et al.), A true and A implies B, thus B true (modus ponens). Can we derive a general objective function that combines logical rules dynamically?
29.01.2025 23:41 —
👍 2
🔁 0
💬 1
📌 0
🥳 "Logically Consistent Language Models via Neuro-Symbolic Integration" just accepted at #ICLR2025!
We focus on instilling logical rules in LLMs with an efficient loss, leading to higher factuality & (self) consistency. How? 🧵
29.01.2025 23:41 —
👍 13
🔁 2
💬 1
📌 0
RNA FISH -> a fish
03.12.2024 13:13 —
👍 56
🔁 3
💬 2
📌 0
used Cursor (based on claude sonnet 3.5) over VS Code for a week now. Early feedback:
✔️ great to parallelize training and inference
✔️ multi-file context, can easily setup hyperparam sweeps
✔️ great to visualize results with high level guidance. Welcome spider plots!
29.11.2024 17:34 —
👍 1
🔁 0
💬 0
📌 0
Announcing the NeurIPS 2024 Test of Time Paper Awards – NeurIPS Blog
Test of Time Paper Awards are out! 2014 was a wonderful year with lots of amazing papers. That's why, we decided to highlight two papers: GANs (@ian-goodfellow.bsky.social et al.) and Seq2Seq (Sutskever et al.). Both papers will be presented in person 😍
Link: blog.neurips.cc/2024/11/27/a...
27.11.2024 15:48 —
👍 110
🔁 14
💬 1
📌 2
I guess it also depends on the field/subfield?
23.11.2024 20:50 —
👍 0
🔁 0
💬 0
📌 0
researchers on cancer, message me: I’d like to know about your work, your research questions!
23.11.2024 20:49 —
👍 3
🔁 1
💬 0
📌 0
YouTube video by EEML Community
[EEML'24] Sander Dieleman - Generative modelling through iterative refinement
While we're starting up over here, I suppose it's okay to reshare some old content, right?
Here's my lecture from the EEML 2024 summer school in Novi Sad🇷🇸, where I tried to give an intuitive introduction to diffusion models: youtu.be/9BHQvQlsVdE
Check out other lectures on their channel as well!
19.11.2024 09:57 —
👍 115
🔁 12
💬 3
📌 0
I've created an initial Grumpy Machine Learners starter park. If you think you're grumpy and you "do machine learning", nominate yourself. If you're on the list, but don't think you are grumpy, then take a look in the mirror.
go.bsky.app/6ddpivr
18.11.2024 14:40 —
👍 414
🔁 55
💬 124
📌 15


![[EEML'24] Sander Dieleman - Generative modelling through iterative refinement](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:tl4gcezwgrweh4ft7eng7omj/bafkreie63ykfpesuxfzkobn6t7buaj4ulfgbyarzypyp2tagfjfcvuygdu@jpeg)