Discontinuation of the MS Word Template
ARR abandons the MS Word Template for conference submissions. The submissions based on the Word template will be desk-rejected starting from March 2026.
📝 Discontinuation of the MS Word Template
ARR will now fully adopt the LaTeX template to streamline formatting and reduce review workload.
Starting March 2026, submissions using the MS Word template will be desk-rejected.
Check details here: aclrollingreview.org/discontinuat...
#ARR #NLProc
30.10.2025 21:40 — 👍 9 🔁 5 💬 0 📌 0

The MTEB team has just released MTEB v2, an upgrade to their evaluation suite for embedding models!
Their blogpost covers all changes, including easier evaluation, multimodal support, rerankers, new interfaces, documentation, dataset statistics, a migration guide, etc.
🧵
20.10.2025 14:36 — 👍 7 🔁 2 💬 1 📌 0

AI bots wrote and reviewed all papers at this conference
Event will assess how reviews by models compare with those written by humans.
🧪 A new computer science conference, Agents4Science, will feature papers written and peer-reviewed entirely by AI agents. The event serves as a sandbox to evaluate the quality of machine-generated research and its review process.
#MLSky
15.10.2025 15:33 — 👍 4 🔁 2 💬 0 📌 0

ACL 2026 Visa Invitation Letter Request
Please use this form to request a visa invitation letter. The letter will be sent to the email address provided below.
✈️ Visa Letter Requests for ACL 2026
If you intend to commit your paper to ACL 2026 and require an invitation letter for visa purposes, please fill out the visa request form as soon as possible.
(docs.google.com/forms/d/e/1F...)
#ARR #ACL #NLProc
14.10.2025 15:27 — 👍 8 🔁 5 💬 0 📌 0

Illustration of a woman wearing a graduation cap and a lab coat, holding a magnifying glass and examining a document. A mechanical parrot with gears and circuits is perched on her shoulder.
🚀 𝗟𝗮𝘁𝗲𝘀𝘁 𝗣𝗲𝗲𝗿 𝗥𝗲𝘃𝗶𝗲𝘄 𝗗𝗮𝘁𝗮𝘀𝗲𝘁 𝗥𝗲𝗹𝗲𝗮𝘀𝗲 𝗳𝗿𝗼𝗺 𝗔𝗥𝗥 𝟮𝟬𝟮𝟱!
tudatalib.ulb.tu-darmstadt.de/handle/tudat...
📊 𝗡𝗲𝘄𝗹𝘆 𝗮𝗱𝗱𝗲𝗱 𝗔𝗖𝗟 𝟮𝟬𝟮𝟱 𝗱𝗮𝘁𝗮:
✅ 𝟮𝗸 papers
✅ 𝟮𝗸 reviews
✅ 𝟴𝟰𝟵 meta-reviews
✅ 𝟭.𝟱𝗸 papers with rebuttals
(1/🧵)
08.10.2025 06:57 — 👍 3 🔁 2 💬 1 📌 0

Google just released a 270M parameter Gemma model. As a tiny model lover I'm excited. Models in this size class are usually barely coherent, I'll give it a try today to see how this does. developers.googleblog.com/en/introduci...
14.08.2025 16:38 — 👍 48 🔁 2 💬 2 📌 1
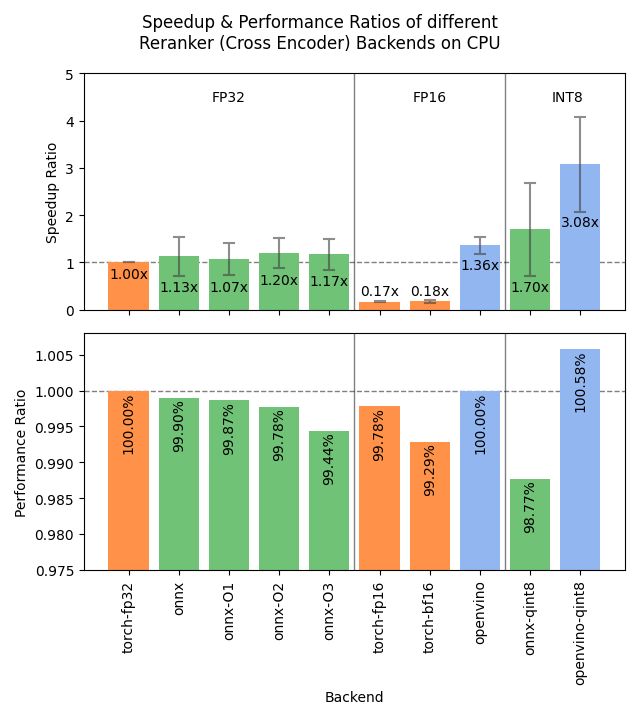
I just released Sentence Transformers v4.1; featuring ONNX and OpenVINO backends for rerankers offering 2-3x speedups and improved hard negatives mining which helps prepare stronger training datasets.
Details in 🧵
15.04.2025 13:54 — 👍 11 🔁 4 💬 1 📌 0

a cat holding a sign that says help
ALT: a cat holding a sign that says help
🗣️Call for emergency reviewers
I am serving as an AC for #ICML2025, seeking emergency reviewers for two submissions
Are you an expert of Knowledge Distillation or AI4Science?
If so, send me DM with your Google Scholar profile and OpenReview profile
Thank you!
20.03.2025 05:25 — 👍 2 🔁 1 💬 0 📌 1
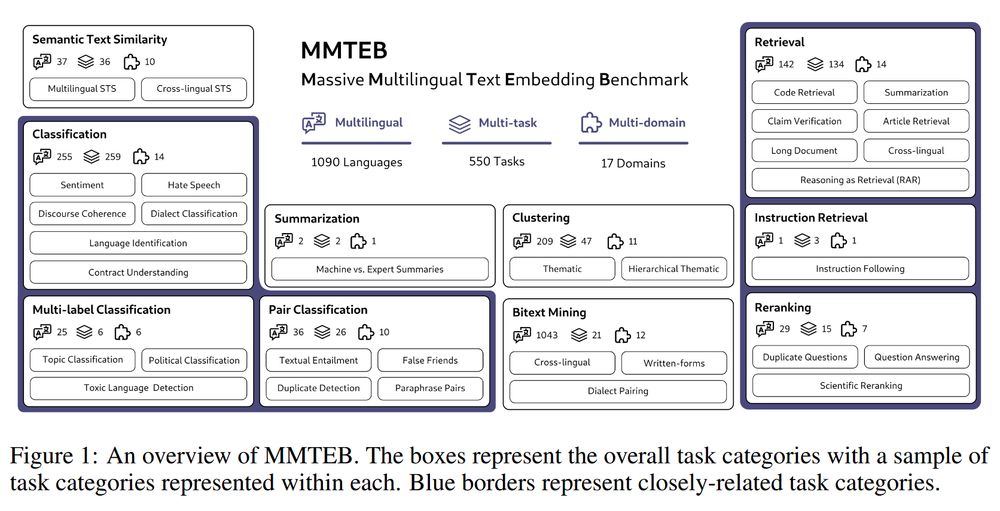
We've just released MMTEB, our multilingual upgrade to the MTEB Embedding Benchmark!
It's a huge collaboration between 56 universities, labs, and organizations, resulting in a massive benchmark of 1000+ languages, 500+ tasks, and a dozen+ domains.
Details in 🧵
21.02.2025 15:06 — 👍 23 🔁 4 💬 2 📌 0
Same issue for me
30.01.2025 19:53 — 👍 0 🔁 0 💬 0 📌 0

Distiling DeepSeek reasoning to ModernBERT classifiers
How can we use the reasoning ability of DeepSeek to generate synthetic labels for fine tuning a ModernBERT model?
Why choose between strong #LLM reasoning and efficient models?
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...
29.01.2025 10:07 — 👍 58 🔁 11 💬 2 📌 4

People often claim they know when ChatGPT wrote something, but are they as accurate as they think?
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
28.01.2025 14:55 — 👍 188 🔁 66 💬 10 📌 19

A Test So Hard No AI System Can Pass It — Yet (Gift Article)
The creators of a new test called “Humanity’s Last Exam” argue we may soon lose the ability to create tests hard enough for A.I. models.
I wrote about a new AI evaluation called "Humanity's Last Exam," a collection of 3,000 questions submitted by leading academics to try to stump leading AI models, which mostly find today's college-level tests too easy.
www.nytimes.com/2025/01/23/t...
23.01.2025 16:41 — 👍 208 🔁 46 💬 17 📌 15
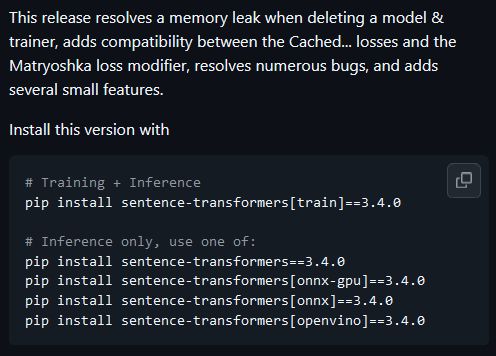
I just released Sentence Transformers v3.4.0, featuring a memory leak fix (memory not being cleared upon model & trainer deletion), compatibility between the powerful Cached... losses and the Matryoshka loss modifier, and a bunch of fixes & small features.
Details in 🧵
23.01.2025 16:44 — 👍 12 🔁 4 💬 2 📌 0

LLMs are Also Effective Embedding Models: An In-depth Overview
Large language models (LLMs) have revolutionized natural language processing by achieving state-of-the-art performance across various tasks. Recently, their effectiveness as embedding models has gaine...
LLMs are Also Effective Embedding Models: An In-depth Overview
Provides a comprehensive analysis on adopting LLMs as embedding models, examining both zero-shot prompting and tuning strategies to derive competitive text embeddings vs traditional models.
📝 arxiv.org/abs/2412.12591
18.12.2024 06:40 — 👍 1 🔁 1 💬 0 📌 0
You and users of the "but humans"-argument assume different goals for AI.
The argument assumes that the goal is to develop human-level AI. (Or it's used to counter statements claiming AI systems are less intelligent than humans.) It's not a direct argument for their usefulness.
01.01.2025 10:23 — 👍 2 🔁 0 💬 0 📌 0
Not sure about this idea (and also the objective of maximizing impact), but I really like the "plain language summary" I've seen in some medical papers.
25.12.2024 10:05 — 👍 1 🔁 0 💬 0 📌 0


Announcement #1: our call for papers is up! 🎉
colmweb.org/cfp.html
And excited to announce the COLM 2025 program chairs @yoavartzi.com @eunsol.bsky.social @ranjaykrishna.bsky.social and @adtraghunathan.bsky.social
17.12.2024 15:48 — 👍 66 🔁 24 💬 0 📌 1
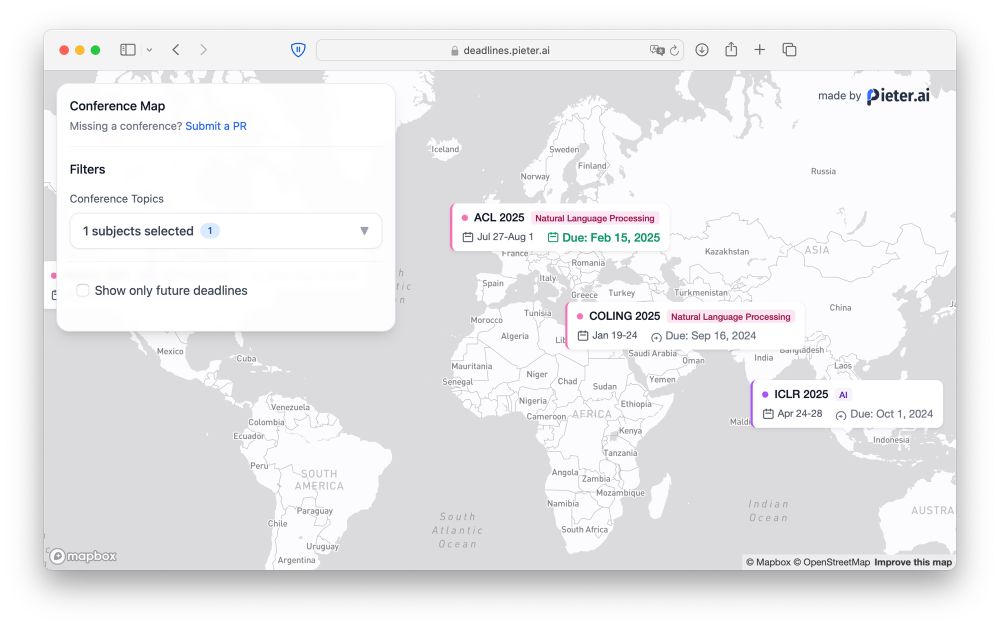
Computer Science Conference Deadlines Map
Interactive world map of Computer Science, AI, and ML conference deadlines
Unsure where to submit your next research paper to now that aideadlin.es is not updated anymore? And let’s be honest, is the location not as important as the conference itself?
🗺️ Check out my latest side-project: deadlines.pieter.ai
23.12.2024 14:39 — 👍 13 🔁 4 💬 0 📌 0
🧪 New pre-print explores generative AI’s in medicine, highlighting applications for clinicians, patients, researchers, and educators. It also addresses challenges like privacy, transparency, and equity.
Additional details from the author linked below.
🩺🖥️
Direct link: arxiv.org/abs/2412.10337
22.12.2024 15:03 — 👍 20 🔁 4 💬 1 📌 0

Instead of listing my publications, as the year draws to an end, I want to shine the spotlight on the commonplace assumption that productivity must always increase. Good research is disruptive and thinking time is central to high quality scholarship and necessary for disruptive research.
20.12.2024 11:18 — 👍 1154 🔁 375 💬 21 📌 57
IMO, there's a great discussion over there (in my timeline, not the for yoy tab) with interesting insights from the OpenAI team.
Bluesky isn't there (yet).
22.12.2024 13:24 — 👍 4 🔁 0 💬 0 📌 0
Re your question at the end:
22.12.2024 13:18 — 👍 1 🔁 0 💬 1 📌 0
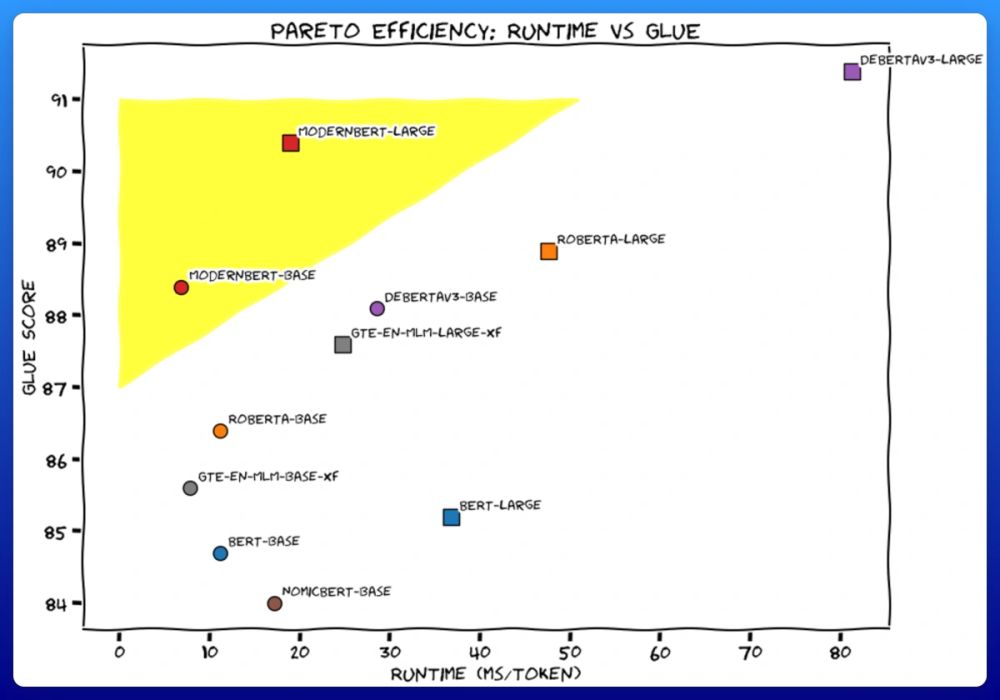
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
19.12.2024 16:45 — 👍 620 🔁 147 💬 19 📌 34
ACL Rolling Review (https://aclrollingreview.org)
Tweets by the ARR Communications / Support Team
Organized and sponsored by SIGLEX, the Special Interest Group of the ACL, *SEM brings together researchers interested in the semantics of natural languages and its computational modeling.
*SEM 2025: https://starsem2025.github.io
I know you seen it prompting itself
EurIPS is a community-organized, NeurIPS-endorsed conference in Copenhagen where you can present papers accepted at @neuripsconf.bsky.social
eurips.cc
Open discussion on arXiv papers
PhD student of NLP at TU Munich 🥨🇩🇪
Working on scientific fact verification, LLM factuality, biomedical NLP. 🌐🧑🏻🎓🇭🇷
Stanford Professor of Linguistics and, by courtesy, of Computer Science, and member of @stanfordnlp.bsky.social and The Stanford AI Lab. He/Him/His. https://web.stanford.edu/~cgpotts/
Professor of philosophy UTAustin. Philosophical logic, formal epistemology, philosophy of language, Wang Yangming.
www.harveylederman.com
Professor of Biostatistics • BMJ Deputy Chief Stats Editor • Books: "Prognosis Research in Healthcare: concepts, methods & impact" & "IPD Meta-Analysis: A Handbook for Healthcare Research.." • Websites: www.ipdma.co.uk & www.prognosisresearch.com • Whovian
Co-founder @forecastingco. Previously PhD UC Berkeley @berkeley_ai, @ENS_ParisSaclay (MVA) and @polytechnique 🇫🇷 🇺🇸 | 👊🥋
The App for Connecting Open Social Web
Mastodon, Bluesky, Nostr, Threads in ONE app, in ONE feed ✨
https://openvibe.social
Author of The Predator Effect; scholarly communications professional; love Lancashire CCC, Man Utd and strong espresso
We're an AI-focused technology company providing innovative solutions to complex challenges faced by researchers, universities, funders, industry & publishers. When we solve problems together, we drive progress for all.
🔗 www.digital-science.com
The Association of Learned and Professional Society Publishers - an International trade body which supports and represents not-for-profit organizations and institutions that publish scholarly and professional content.
Host of Lex Fridman Podcast.
Interested in robots and humans.
Discover and use the latest LLMs. 300+ models, explorable data, private chat, & a unified API. https://openrouter.ai
Experimental & Behavioural economist INRAE Grenoble • President of the French Association of Experimental Economists • Scientific publishing measurement & reform • Experiments on food labeling - risk - choices • Rstats • Italian Food Police honorary member
Chair, Department of Computational Biomedicine at Cedars-Sinai Medical Center in Los Angeles. Director, Center for Artificial Intelligence Research & Education. Atari enthusiast. Retrocomputing. Maker.
Señor swesearcher @ Google DeepMind, adjunct prof at Université de Montréal and Mila. Musician. From 🇪🇨 living in 🇨🇦.
https://psc-g.github.io/
Built to make you extraordinarily productive, Cursor is the best way to code with AI.
[bridged from https://cursor.com/ on the web: https://fed.brid.gy/web/cursor.com ]