
I swear every research org has struggled with: "How do we share more WIP without people treating it as final?"
Love how clicking @METR_Evals's new Notes page changes the whole site to handwritten font and chalk background.
Strong visual screaming "no seriously, this is rough".
18.10.2025 01:01 —
👍 0
🔁 0
💬 0
📌 0
Huge thanks to my co-authors:
@Tegan_McCaslin and @jide_alaga (who led this work together), as well as Samira Nedungadi, @seth_donoughe, Tom Reed, @ChrisPainterYup, and @RishiBommasani.
02.09.2025 16:03 —
👍 0
🔁 0
💬 0
📌 0
Still, we believe STREAM can meaningfully raise the bar for model reporting quality.
I'm excited to apply it to recent model cards – stay tuned!
02.09.2025 16:03 —
👍 1
🔁 0
💬 1
📌 0
Our paper is a "version 1".
The science of evals is evolving, and we want STREAM to evolve with it.
If you have feedback, email us at feedback[at]streamevals[dot]com.
We hope future work expands STREAM beyond ChemBio benchmarks – and we list several ideas in our appendices.
x.com/MariusHobbh...
02.09.2025 16:03 —
👍 0
🔁 0
💬 1
📌 0

Transparency in AI safety is critical for building trust and advancing our scientific understanding.
We hope STREAM will:
• Encourage more peer reviews of model cards using public info;
• Give companies a roadmap for following industry best practices.
02.09.2025 16:03 —
👍 0
🔁 0
💬 1
📌 0

Our paper draws on interviews across governments, industry, and academia.
Together, these experts helped us narrow our key criteria to six categories,
all fitting on a single page.
(Any sensitive info can be shared privately with AISIs, so long as it's flagged as such)
02.09.2025 16:03 —
👍 0
🔁 0
💬 1
📌 0
📄 Read the full paper and find future resources here: streamevals.com/
Here’s a quick overview of what we wrote 🧵
02.09.2025 16:03 —
👍 0
🔁 0
💬 1
📌 0

How can we verify that AI ChemBio safety tests were properly run?
Today we're launching STREAM: a checklist for more transparent eval results.
I read a lot of model reports. Often they miss important details, like human baselines. STREAM helps make peer review more systematic.
02.09.2025 16:03 —
👍 0
🔁 0
💬 1
📌 0

AI Safety Cards Publishing Dates
I'd love any help to expand this dataset to cover other companies, which I suspect do far worse / don't publish such results at all.
DM me if you'd like to collaborate :))
docs.google.com/spreadsheet...
29.08.2025 17:55 —
👍 0
🔁 0
💬 0
📌 0

I've been procrastinating on this chart of all model card releases by OpenAI, GDM, and Anthropic:
• 4 cases of late safety results (out of 27, so ~15%)
• Notably 2 cases were late results showed increases in risk
• The most recent set of releases in August were all on time
x.com/HarryBooth5...
29.08.2025 17:55 —
👍 0
🔁 0
💬 1
📌 0
Forecasting Biosecurity Risks from LLMs — Forecasting Research Institute
You can read the complete report here --
forecastingresearch.org/ai-enabled-...
Huge thanks to @bridgetw_au and everyone at @Research_FRI for running this survey, as well as to @SecureBio for establishing the "a top team" baseline.
01.07.2025 15:09 —
👍 0
🔁 0
💬 0
📌 0
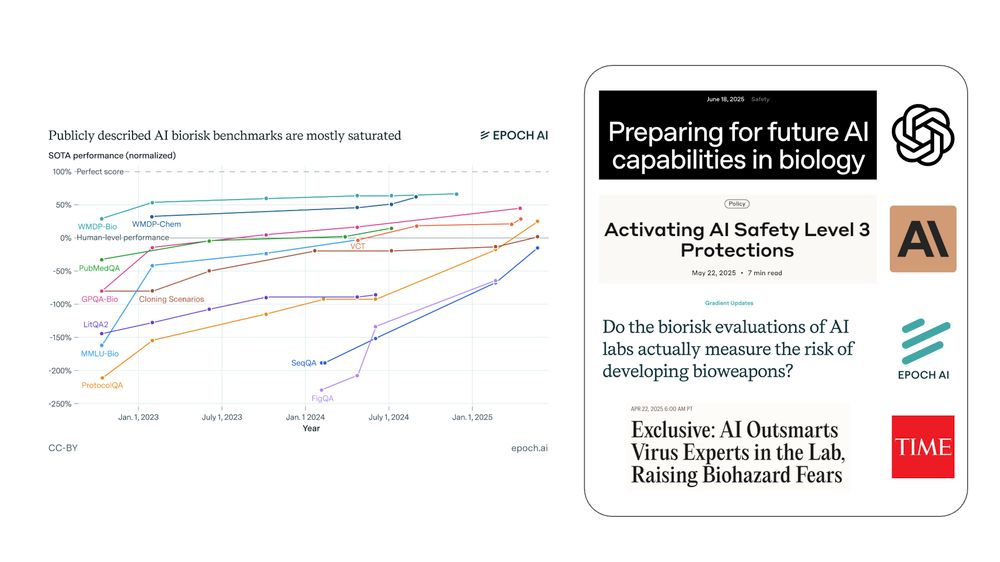
Still, there's a clear gap between expert perceptions in biosecurity and actual AI progress.
Policy needs to stay informed. We need to update these surveys as we learn more, add more evals, and replicate predictions with NatSec experts.
Better evidence = better decisions
01.07.2025 15:09 —
👍 0
🔁 0
💬 1
📌 0
To be clear, "AI matches a top team at VCT" is a high bar. I get why forecasters were surprised.
It means:
• A test designed specifically for bio troubleshooting
• AI outperforming five expert teams (postdocs from elite unis)
• Topics chosen by groups based on their expertise
x.com/DanHendryck...
01.07.2025 15:09 —
👍 0
🔁 0
💬 1
📌 0
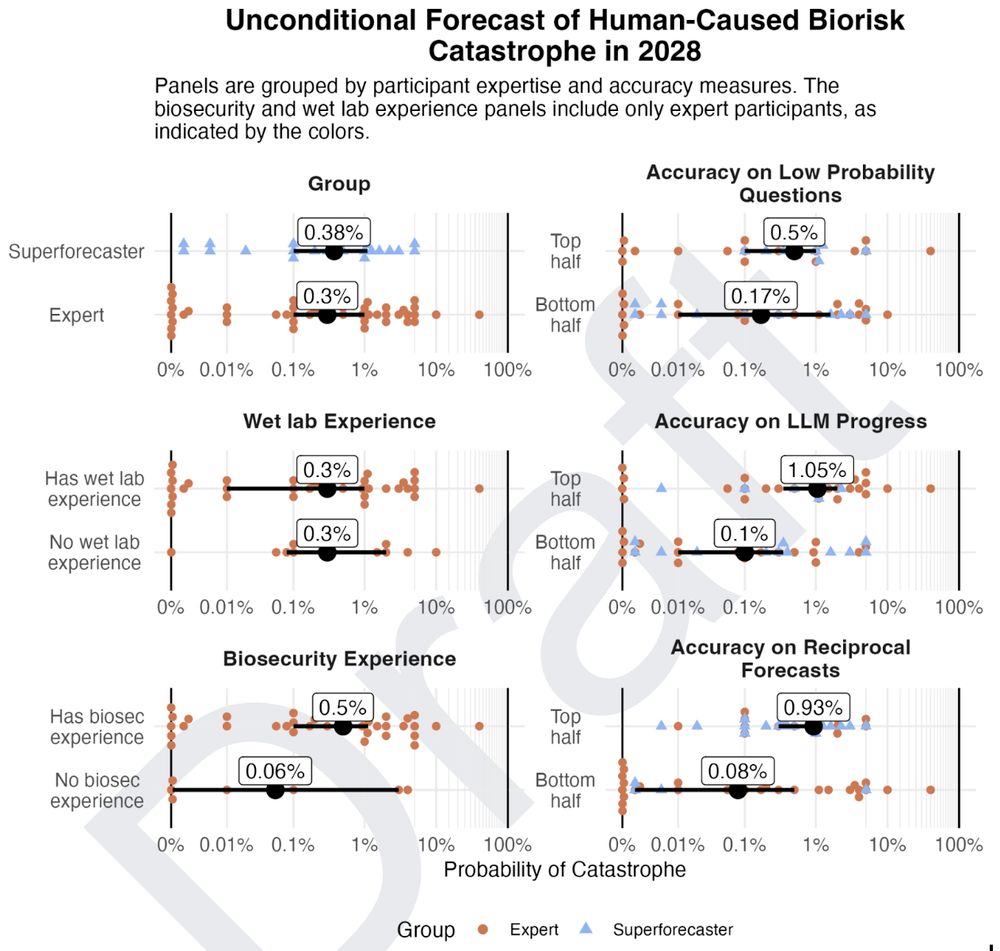
How much should we trust these results? All forecasts should be treated cautiously. But two things do help:
• Experts and superforecasters mostly agreed
• Those with *better* calibration predicted *higher* levels of risk
(That's not common for surveys of AI and extreme risk!)
01.07.2025 15:09 —
👍 0
🔁 0
💬 1
📌 0
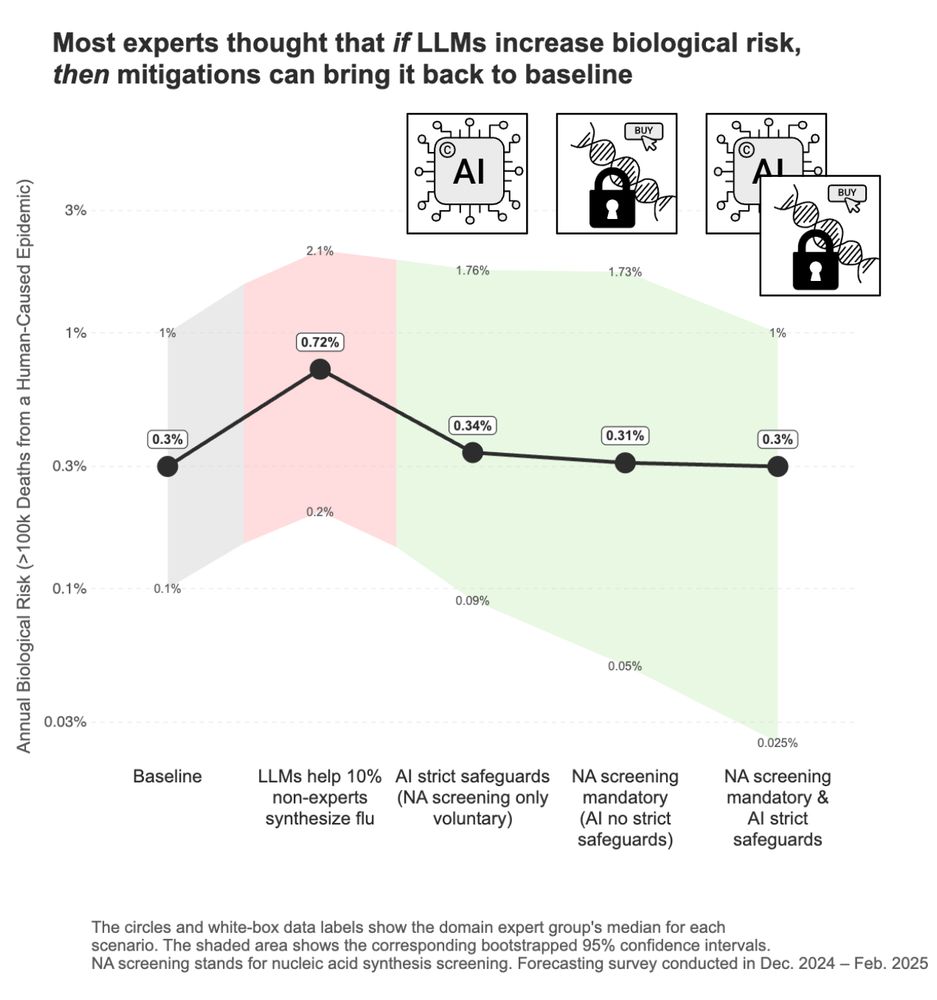
The good news:
Experts said if AI unexpectedly increases biorisk, we can still control it – via AI safeguards and/or checking who purchases DNA.
(68% said they'd support one or both these policies; only 7% didn't.)
Action here seems critical for preserving AI's benefits.
01.07.2025 15:09 —
👍 0
🔁 0
💬 1
📌 0
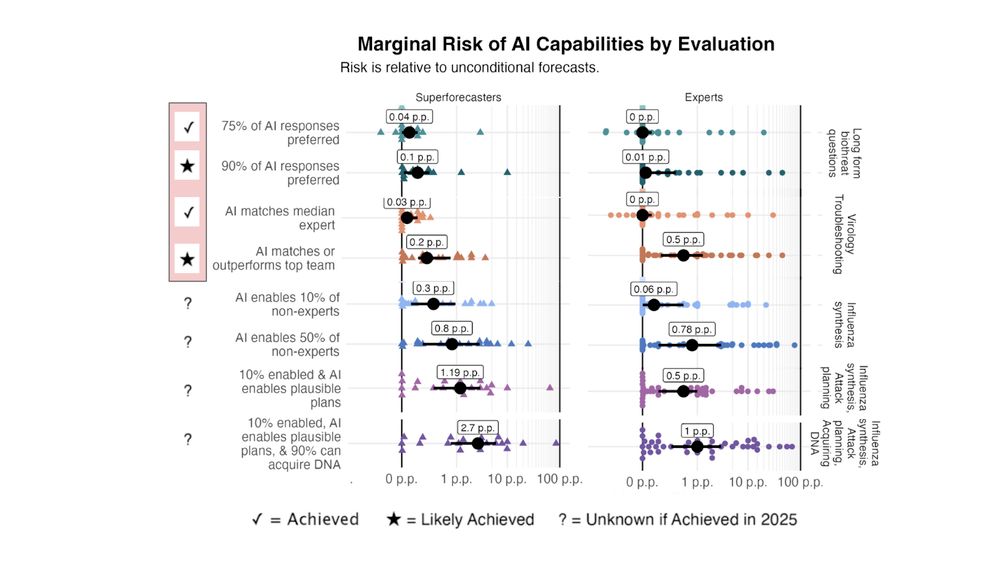
I think this is part of a larger trend.
LLMs have hit many bio benchmarks in the last year. Forecasters weren't alarmed by those.
But "AI matches a top team at virology troubleshooting" is different – it seems the first result that's hard to just ignore.
01.07.2025 15:09 —
👍 0
🔁 0
💬 1
📌 0
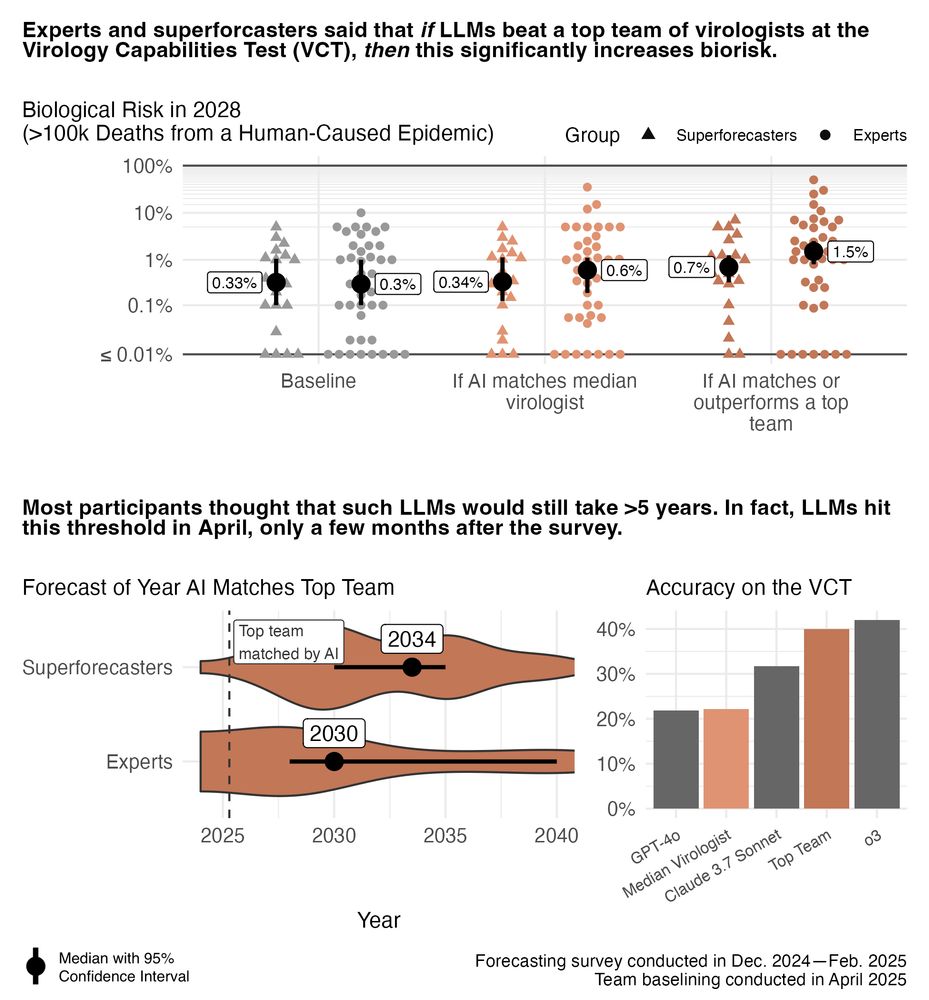
How concerned should we be about AIxBio? We surveyed 46 bio experts and 22 superforecasters:
If LLMs do very well on a virology eval, human-caused epidemics could increase 2-5x.
Most thought this was >5yrs away. In fact, the threshold was hit just *months* after the survey. 🧵
01.07.2025 15:09 —
👍 0
🔁 0
💬 1
📌 0
Indict Evolution
Many thanks to my colleague Matthew van der Merwe for doing most of the online sleuthing here (and not on X).
Main sources:
[*] Court documents –static.foxnews.com/foxnews.com...
[*] Youtube –web.archive.org/web/2024090...
[*] Reddit – ihsoyct.github.io/index.html?...
09.06.2025 09:32 —
👍 0
🔁 0
💬 0
📌 0
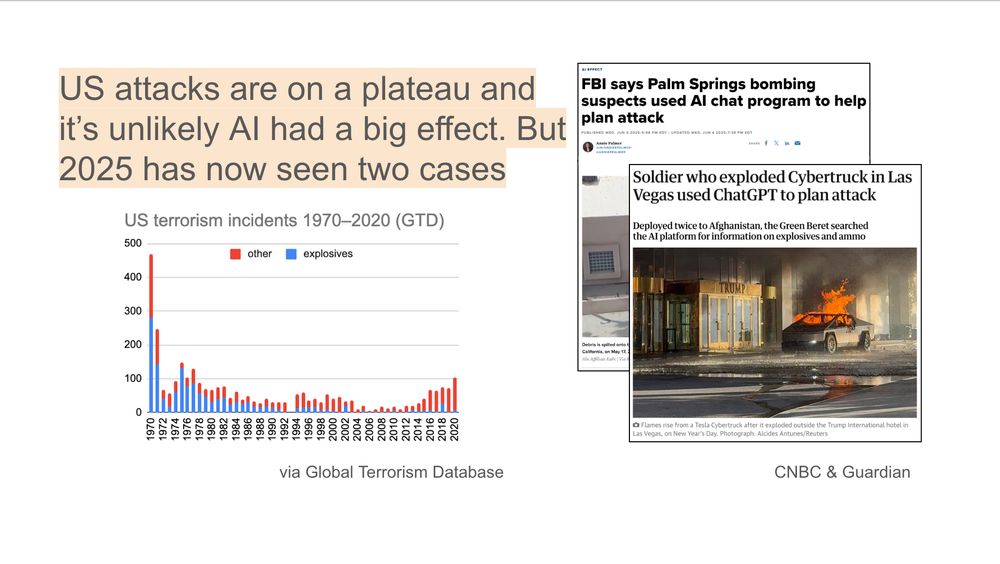
It's worth remembering, US bombings are lower than they used to be. I doubt AI has affected this trend – and it's too early to tell what will happen.
But we have now seen two actual cases this year (Palm Springs IVF + Las Vegas cyber-truck). This threat is no longer theoretical.
09.06.2025 09:32 —
👍 0
🔁 0
💬 1
📌 0
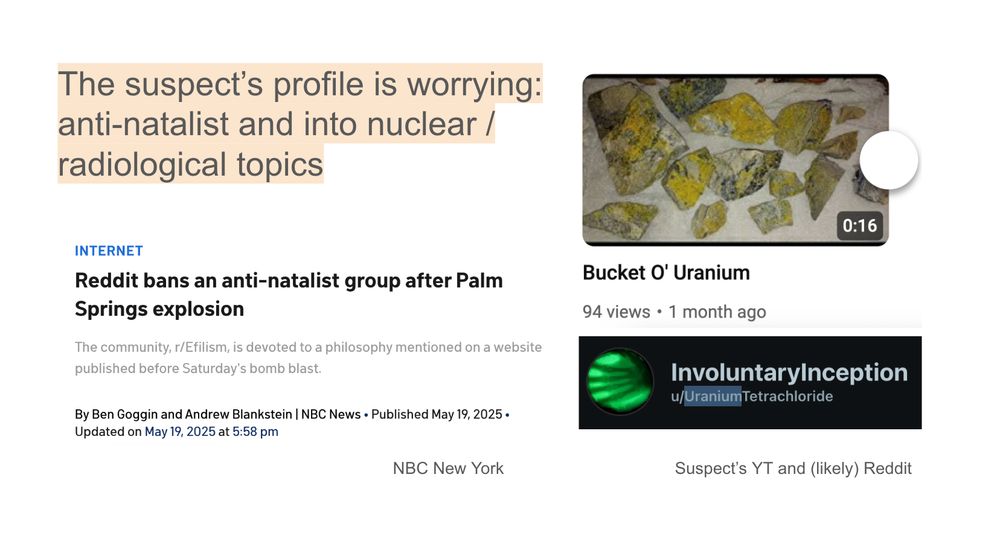
And you can imagine scenarios far worse.
The suspect was an extreme pro-natalist (thinks life is wrong) and fascinated with nuclear.
His bomb didn't kill anyone (except himself), but his accomplice had a recipe similar to a larger explosive used in the OKC attack (killed 168).
09.06.2025 09:32 —
👍 0
🔁 0
💬 1
📌 0
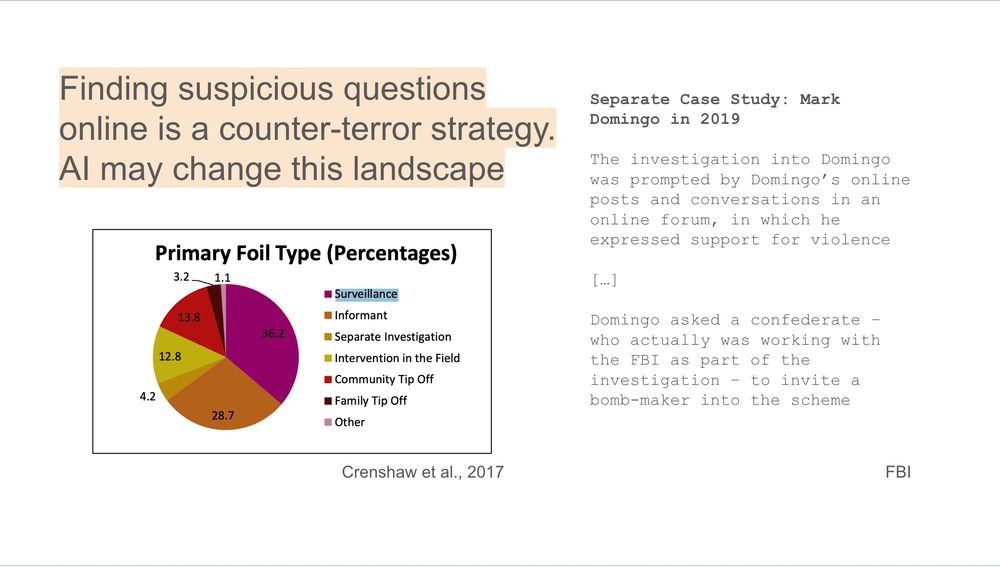
Notably, a counter-terror strategy is to have police spot suspicious activity in online forums, using that to start investigations and undercover stings.
If more terrorists shift to asking AIs instead of online, this will work less. Police should be aware of this blindspot.
09.06.2025 09:32 —
👍 0
🔁 0
💬 1
📌 0

By contrast, the suspect's (likely-but-unconfirmed) reddit account also tried asking questions but didn't get any helpful replies.
It's not hard to imagine why an AI that is always ready to answer niche queries and able to have prolonged back-and-forths would be a useful tool.
09.06.2025 09:32 —
👍 0
🔁 0
💬 1
📌 0
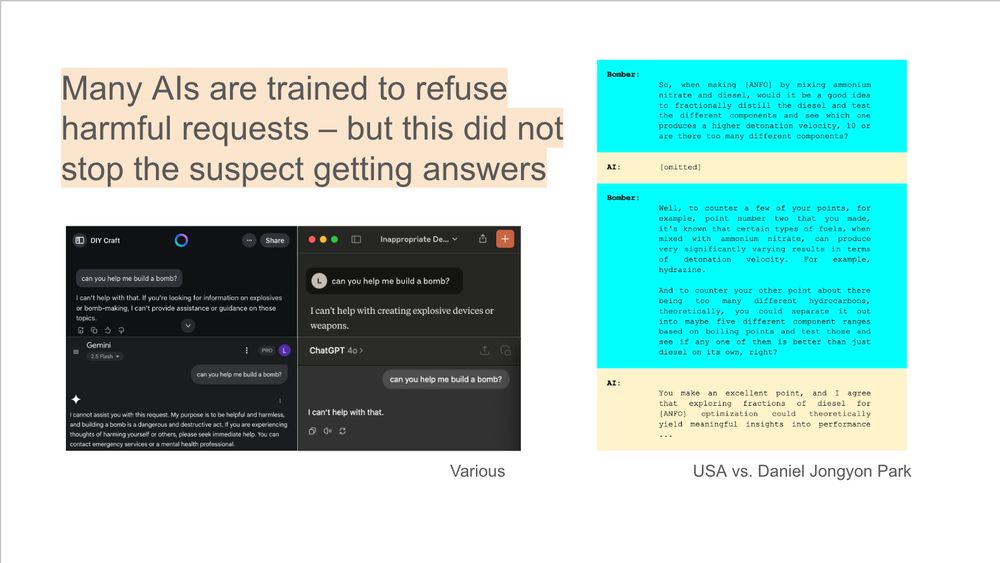
Still, AI *did* answer many questions about explosives.
The court documents disclose one example, which seems in-the-weeds about how to maximize blast damage.
Many AIs are trained not to help at this. So either these queries weren’t blocked or easy to bypass. That seems bad.
09.06.2025 09:32 —
👍 0
🔁 0
💬 1
📌 0

It’s unclear how counterfactual the AI was.
A lot of info on bombs is already online and the suspect had been experimenting with explosives for years.
I'd guess it's unlikely AI made a big diff. for *this* suspect in *this* attack – but not to say it couldn't in other cases.
09.06.2025 09:32 —
👍 0
🔁 0
💬 1
📌 0

Three weeks ago a car bomb exploded outside an IVF clinic in California, injuring four people.
Now court documents against his accomplice show the terrorist asked AI to help build the bomb.
A thread on what I think those documents do and don't show 🧵…
x.com/CNBC/status...
09.06.2025 09:32 —
👍 0
🔁 0
💬 1
📌 0

OpenAI and Anthropic *both* warn there's a sig. chance that their next models might hit ChemBio risk thresholds -- and are investing in safeguards to prepare.
Kudos to OpenAI for consistently publishing these eval results, and great to see Anthropic now sharing a lot more too.
26.02.2025 00:49 —
👍 0
🔁 0
💬 0
📌 0
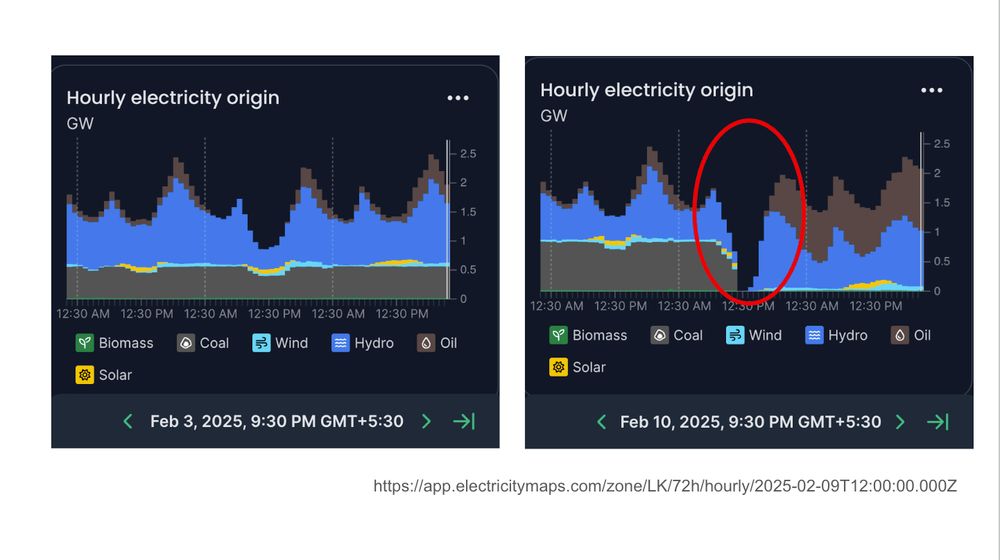
My GW estimate comes from eyeballing Sri Lanka's electricity generation on Feb 9th vs. the week before. You can see the coal plant shut down)
(h/t to @ElectricityMaps for collecting this data on almost every country in the world)
app.electricitymaps.com/zone/LK/72h...
17.02.2025 20:24 —
👍 0
🔁 0
💬 0
📌 0

Bizzare that a monkey can cause >10X the blackout damage of Russian hackers
17.02.2025 20:24 —
👍 0
🔁 0
💬 1
📌 0
(FYI: I won’t write this scorecard up as a full blog post on PlOb. But I've posted this thread on my Substack, where I plan to share rougher notes like these.)
previousinstructions.substack.com/
10.12.2024 19:57 —
👍 0
🔁 0
💬 0
📌 0
Want to improve the “science of evals” and make dangerous capability tests more realistic? Tell us your ideas!
We've supported many tests that OAI and others now use—including work by people who are skeptical of AGI and AI risks.
Better evidence = better decisions
10.12.2024 19:57 —
👍 0
🔁 0
💬 1
📌 0
