Thanks!
15.07.2025 14:18 — 👍 1 🔁 0 💬 0 📌 0
Also, it is worth while to think about the total resource cost of running algorithms especially for platforms with non-local connectivity. Trade-offs between Clifford and T on such platforms could be different from platforms with planar connectivity since the former can host transversal Cliffords.
12.04.2025 05:45 — 👍 0 🔁 0 💬 0 📌 0
Our MSC protocol uses non-local connectivity available in neutral atom array and ion trap platforms. There is a lot of freedom to do MSC and our protocol still has room for improvements. Moreover, it is important to estimate the resource cost for preparing T states with even lower error rate.
12.04.2025 05:45 — 👍 0 🔁 0 💬 1 📌 0
Our growing step is easy to decode and is more efficient than ‘grafting’. We ascribe our efficiency improvement to this.
Well, the above is pretty much the whole story. One then simply needs to get the details right. (See our paper for them.)
12.04.2025 05:45 — 👍 0 🔁 0 💬 1 📌 0
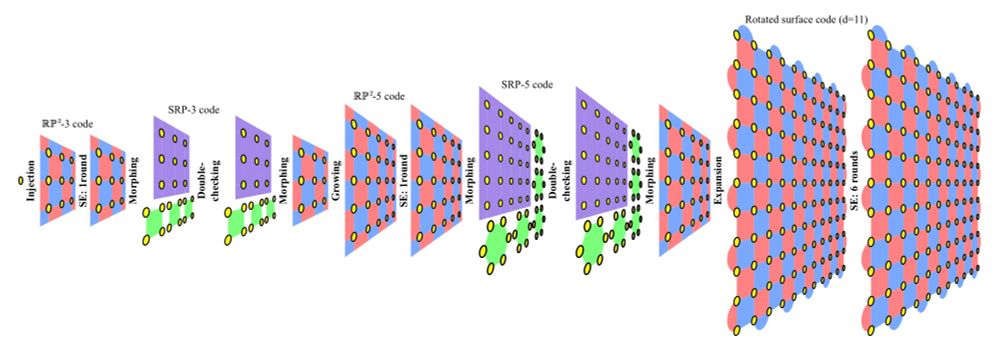
So basically, our protocols work in the following way:
We use the small RP^2 code to hold information and transform it to SRP code (a self-dual code) to double-check the logical state and then back. After preparing a high fidelity T state on the RP^2 code, we grow it to a large rotated surface code.
12.04.2025 05:45 — 👍 1 🔁 0 💬 1 📌 0
For 1. we construct the RP^2 code (a variant of the planar surface code) with fold-duality. We can use this symmetry to easily transform it to a self-dual code (for 2.) and back. (similar to how a color code can be obtained by folding a surface code)
12.04.2025 05:45 — 👍 0 🔁 0 💬 1 📌 0
3. Finding a code that simultaneously satisfy 1. and 2. is difficult. So we chose to find two different codes that satisfy 1. and 2. respectively and also a nice way to morph between the two codes.
12.04.2025 05:45 — 👍 1 🔁 0 💬 1 📌 0
2. To efficiently prepare a high fidelity T state on the small code, we want to use a self-dual CSS code with one logical qubit. Such code also has a transversal H_XY operator so that the correctness of the logical T state can be double-checked efficiently similar to the original MSC protocol.
12.04.2025 05:45 — 👍 0 🔁 0 💬 1 📌 0
Motivation behind our protocol:
1. To easily grow to a large regular surface code, the small code should be structurally similar to the surface code.
12.04.2025 05:45 — 👍 0 🔁 0 💬 1 📌 0
* Similar to the original MSC work, we sample on a Clifford variant of our protocol as circuits with many Ts are difficult to simulate.
12.04.2025 05:45 — 👍 0 🔁 0 💬 1 📌 0
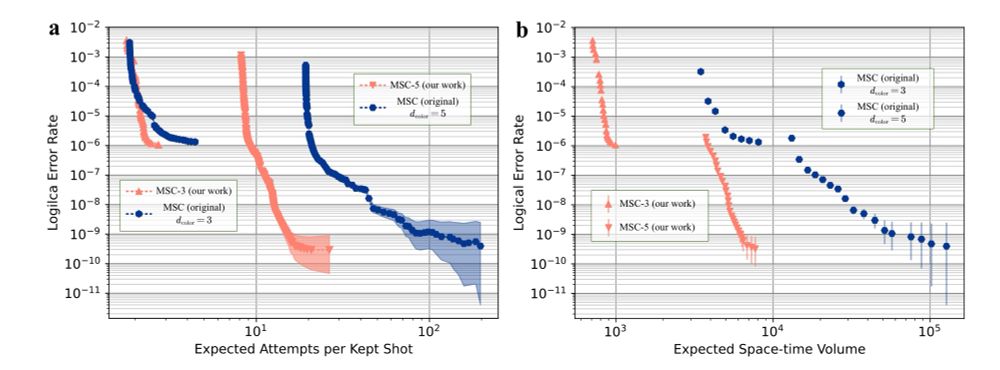
Back to describe our work:
Inspired by the original MSC protocol, we propose a new MSC protocol that produces T states on the regular surface code. Our protocol requires nearly an order of magnitude smaller spacetime cost to prepare a T state with logical error rate 1e-9 compared to the original MSC
12.04.2025 05:45 — 👍 1 🔁 0 💬 1 📌 0
* And the efficiency of the original MSC protocol (with grafting replaced by simply growing the small color code to a large color code) would be improved given a better color code decoder.
12.04.2025 05:45 — 👍 0 🔁 0 💬 1 📌 0
Secondly, ‘grafting’ incurs extra post-selection and hopefully can be improved or replaced. * We would like to note that ‘grafting’ was used due to the lack of fast and accurate color code decoders.
12.04.2025 05:45 — 👍 0 🔁 0 💬 1 📌 0
First, the original MSC would produce T states on a slightly deformed surface code via ‘grafting’ (used to grow a small color code to a large matchable code). We would want to produce them on the regular surface code instead so that they can be easily teleported via transversal CNOTs.
12.04.2025 05:45 — 👍 0 🔁 0 💬 1 📌 0
For platforms with long-range connectivity, transversal logical Clifford gates are a more efficient alternative to surgery. Thus we would like to make T states/gates even cheaper. We see the following aspects of the MSC protocol can be improved.
12.04.2025 05:45 — 👍 0 🔁 0 💬 1 📌 0
MSC essentially has two steps:
1. Preparing a high fidelity T state on a small (color) code. Crucially, the transversal logical H_XY operator of the color code is double-checked to verify the correctness of the logical state.
2. Growing the small code to a large code to protect the logical state.
12.04.2025 05:45 — 👍 0 🔁 0 💬 1 📌 0
Background:
Magic state cultivation (MSC), proposed by Gidney et al., can, very surprisingly, produce T states (with logical error rate down to 1e-9) as efficiently as lattice surgery CNOT.
12.04.2025 05:45 — 👍 1 🔁 0 💬 1 📌 0
Finally got around to write about our recent work, in which we propose a new magic state cultivation protocol with enhanced efficiency using non-local connectivity. arxiv.org/abs/2503.18657
12.04.2025 05:45 — 👍 11 🔁 0 💬 2 📌 1
(Have to say that this is not what I came up with in the first place. One day I came across the relaxing hardware requirements paper. And it naturally dawned on me that we can do S gate at half cycle)
10.12.2024 01:44 — 👍 0 🔁 0 💬 0 📌 0
Haha! When I was working on this, the most thing I worry about is that you have already known this and decided not to put it in a paper because it’s too simple.
10.12.2024 01:44 — 👍 0 🔁 0 💬 1 📌 0
Oh, I see. I wasn’t being clear. The decoding issue still persists in our case (growing more significant at larger distances) even when we put our S gate two SE rounds away from X data qubits init. (here we check the distance is d using stim’s search)
05.12.2024 13:54 — 👍 0 🔁 0 💬 0 📌 0
(and we think it is important to address error correlation in decoding similar to the correlated decoder used in your work
05.12.2024 07:13 — 👍 0 🔁 0 💬 0 📌 0
Yeah, we share the same feeling. There are no z detectors at time boundaries and being near boundary makes the decoder try to connect syndromes directly to the boundary. Both are bad for our purpose.
05.12.2024 07:13 — 👍 0 🔁 0 💬 2 📌 0
We also specifically considered how to efficiently implement our protocol on neutral atom array platforms. Hopefully the morphing effect of SE circuits can be used on other codes for more efficient logical gate implementations.
05.12.2024 05:56 — 👍 0 🔁 0 💬 0 📌 0

Overall, our S gate protocol is simple but it works. Now all Clifford gates can be done transversally on rotated surface codes (with long range connectivity).
05.12.2024 05:56 — 👍 2 🔁 0 💬 1 📌 0
our decoding strategy becomes less effective. (Such situation arises if one wants to do fast Y basis init/meas) To deal with this issue, we deploy two refinements on our decoding strategy. Please see our paper for more details on this. The codes and stim circuits are uploaded to github.
05.12.2024 05:56 — 👍 0 🔁 0 💬 1 📌 0
This is somewhat surprising, as we did in-patch operation on both data qubits and ancilla qubits during SE. So some errors seem dangerous and can propagte along with SE. Another wierd thing is that when we put our S gate protocol near time boundaries (such as X-basis initialization and measurement),
05.12.2024 05:56 — 👍 0 🔁 0 💬 2 📌 0
The above procedure is contained in a single SE round and performs a logical S gate on the rotated SC. Decoding such protocol can be done based on the same principles as the recents works on decoding CNOTs. And we observe the performace of our protocol is on par with the quantum memory.
05.12.2024 05:56 — 👍 0 🔁 0 💬 1 📌 0
We start with a rotated SC at the beginning of an SE round, and do the first two layers of CNOT gates then insert a fold-transversal operation on the unrotated SC state at half-cycle. We continue to do the remaining two layers of CNOT gates and at the end of the SE round, we return to a rotated SC.
05.12.2024 05:56 — 👍 1 🔁 0 💬 1 📌 0
Researcher at Quantinuum. Particularly interested in the interface of device characterization, QEC, and foundations.
Quantum computing researcher at U Cologne | random quantum circuits | benchmarking and learning | Clifford group nerd
We’re advancing quantum computing to solve the world’s most pressing challenges.
Junior Research Group Leader at Universität Jena
I like exploring the unknown 🔭🔬🤖✨
AI for Science, Quantum Optics (Theory & Experiment)
Master student in Quantum science and engineering at EPFL. Interested in classical and quantum theoretical computer science. Looking for a PhD. he/him
My typed notes: https://github.com/JoachimFavre/UniversityNotes
Twitter: https://x.com/JoachimFavre
PhD in Quantum Information. Trying to make quantum computers less noisy.
I am a reseacher at Tecnun. Former visitor at the Cavendish Laboratory (Cambridge).
Rugby player. Rock&Roll.
Opinions are my own.
Quantum error correction and places with high bog factor
phd student @ caltech | interested in quantum info, math education, watercolors, marine bio
https://reionize.github.io
Unitary Foundation is a 501(c)(3) non-profit helping create a quantum technology ecosystem that benefits the most people.
QEC @ IBM quantum
Parent, quantum physicist, gardener
Building cool quantum, photonic, and nanomechanical stuff as Prof at Stanford.
https://quantum-noise.ghost.io
Condensed Matter Physics. Quantum Algorithms. PhD student at UC Santa Barbara.
Quantum physicist / quantum sensing with superconducting circuits @CEA Saclay / Scientific advisor @Alice&Bob .
Ph.D. candidate in Quantum Error Correction @ Duke University. Built github.com/planqtn for quantum LEGO. Xoogler at Google Quantum AI. Previously software engineer/craftsman for 15 years.
PhD student in Quantum Engineering @ University of Bristol & Quantum Scientist @ Riverlane
PhD student in quantum error correction @ Inria Paris
https://samo-novak.github.io/





















