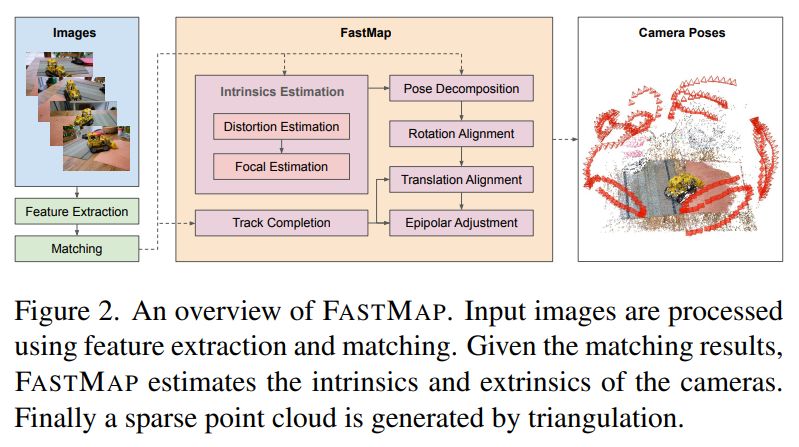
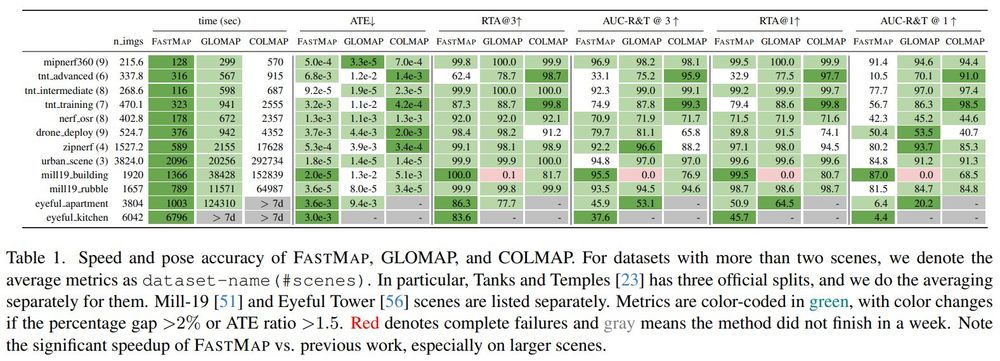
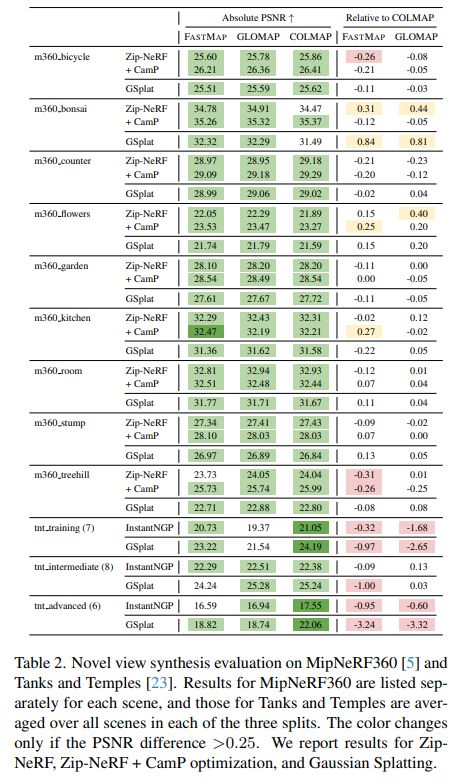
Join us in advancing data science and AI research! The Johns Hopkins Data Science and AI Institute Postdoctoral Fellowship Program is now accepting applications for the 2026–2027 academic year. Apply now! Deadline: Jan 23, 2026. Details and apply: apply.interfolio.com/179059
19.12.2025 13:29 —
👍 11
🔁 9
💬 0
📌 5
10 new CS professors! 🥳
@anandbhattad.bsky.social @uthsav.bsky.social @gligoric.bsky.social @murat-kocaoglu.bsky.social @tiziano.bsky.social
08.10.2025 17:43 —
👍 9
🔁 6
💬 0
📌 0
I decided not to travel to #ICCV2025 because it coincides with Diwali (Oct 20). Diwali often falls near the #CVPR deadline window, but this year overlaps with ICCV. I understand it’s hard to avoid all global holidays, but I hope future conferences can keep this in mind when selecting dates.
06.10.2025 19:00 —
👍 2
🔁 0
💬 0
📌 0
I will be recruiting a few students for Fall 2026. In particular, I will strongly consider a PhD applicant with training in applied/computational mechanics and computer vision/machine learning. If you or someone you know has this background, please contact me.
06.10.2025 18:39 —
👍 4
🔁 1
💬 0
📌 0

So You Want to Be an Academic? What I Wish I Knew Early in Graduate School
Blog for junior PhD students on work, visibility, community, and sanity—long before the faculty job market is on the horizon.
So You Want to Be an Academic?
A couple of years into your PhD, but wondering: "Am I doing this right?"
Most of the advice is aimed at graduating students. But there's far less for junior folks who are still finding their academic path.
My candid takes: anandbhattad.github.io/blogs/jr_gra...
21.09.2025 02:30 —
👍 20
🔁 4
💬 1
📌 0
Thanks Andreas and the Scholar Inbox team! This is by far the best paper recommendation system I’ve come across. No more digging through overwhelming volumes and like the blog says, the right papers just show up in my inbox.
30.06.2025 14:47 —
👍 2
🔁 0
💬 0
📌 0

Scholar Inbox: Daily Research Recommendations just for You
Science is moving fast. How can we keep up? Scholar Inbox helps researchers stay ahead by making the discovery of open access papers more personal.
On our blog: Science is moving fast. How do we keep up? #ScholarInbox, developed by the Autonomous Vision Group led by @andreasgeiger.bsky.social, helps researchers stay ahead - by making the discovery of #openaccess papers smarter and more personal: www.machinelearningforscience.de/en/scholar-i...
30.06.2025 12:40 —
👍 27
🔁 14
💬 1
📌 6
All slides from the #cvpr2025 (@cvprconference.bsky.social ) workshop "How to Stand Out in the Crowd?" are now available on our website:
sites.google.com/view/standou...
30.06.2025 03:19 —
👍 0
🔁 0
💬 0
📌 0
This is probably one of the best talks and slides I have ever seen. I was lucky to see this live! Great talk again :)
23.06.2025 19:24 —
👍 3
🔁 0
💬 1
📌 0

A special shout-out to all the job-market candidates this year: it’s been tough with interviews canceled and hiring freezes🙏
After UIUC's blue and @tticconnect.bsky.social blue, I’m delighted to add another shade of blue to my journey at Hopkins @jhucompsci.bsky.social. Super excited!!
02.06.2025 19:46 —
👍 2
🔁 0
💬 0
📌 0
Anand Bhattad - Research Assistant Professor
We will be recruiting PhD students, postdocs, and interns. Updates soon on my website: anandbhattad.github.io
Also, feel free to chat with me @cvprconference.bsky.social #CVPR2025
I’m immensely grateful to my mentors, friends, colleagues, and family for their unwavering support.🙏
02.06.2025 19:46 —
👍 0
🔁 0
💬 1
📌 0
At JHU, I'll be starting a new lab: 3P Vision Group. The “3Ps” are Pixels, Perception & Physics.
The lab will focus on 3 broad themes:
1) GLOW: Generative Learning Of Worlds
2) LUMA: Learning, Understanding, & Modeling of Appearances
3) PULSE: Physical Understanding and Learning of Scene Events
02.06.2025 19:46 —
👍 0
🔁 0
💬 1
📌 0

I’m thrilled to share that I will be joining Johns Hopkins University’s Department of Computer Science (@jhucompsci.bsky.social, @hopkinsdsai.bsky.social) as an Assistant Professor this fall.
02.06.2025 19:46 —
👍 8
🔁 2
💬 1
📌 2
[2/2] However, if we treat 3D as a real task, such as building a usable environment, then these projective geometry details matter. It also ties nicely to Ross Girshick’s talk at our RetroCV CVPR workshop last year, which you highlighted.
29.04.2025 16:56 —
👍 1
🔁 0
💬 0
📌 0
[1/2] Thanks for the great talk and for sharing it online for those who couldn't attend 3DV. I liked your points on our "Shadows Don't Lie" paper. I agree that if the goal is simply to render 3D pixels, then subtle projective geometry errors that are imperceptible to humans are not a major concern.
29.04.2025 16:56 —
👍 1
🔁 0
💬 1
📌 0
Congratulations and welcome to TTIC! 🥳🎉
15.04.2025 13:03 —
👍 1
🔁 0
💬 0
📌 0
By “remove,” I meant masking the object and using inpainting to hallucinate what could be there instead.
02.04.2025 05:08 —
👍 0
🔁 0
💬 0
📌 0
This is really cool work!
30.03.2025 00:14 —
👍 7
🔁 1
💬 1
📌 0
Thanks Noah! Glad you liked it :)
02.04.2025 04:51 —
👍 0
🔁 0
💬 0
📌 0
[2/2] We also re-run the full pipeline *after each removal*. This matters: new objects can appear, occluded ones can become visible, etc, making the process adaptive and less ambiguous.
Fig above shows a single pass. Once the top bowl is gone, the next "top" bowl gets its own diverse semantics too
02.04.2025 04:49 —
👍 0
🔁 0
💬 0
📌 0

[1/2] Not really... there's quite a bit of variation.
When we remove the top bowl, we get diverse semantics: fruits, plants, and other objects that just happen to fit the shape. As we go down, it becomes less diverse: occasional flowers, new bowls in the middle, & finally just bowls at the bottom.
02.04.2025 04:49 —
👍 1
🔁 0
💬 2
📌 0

Visual Jenga: Discovering Object Dependencies via Counterfactual Inpainting
Visual Jenga is a new scene understanding task where the goal is to remove objects one by one from a single image while keeping the rest of the scene stable. We introduce a simple baseline that uses a...
[10/10] This project began while I was visiting Berkeley last summer. Huge thanks to Alyosha for the mentorship and to my amazing co-author Konpat Preechakul. We hope this inspires you to think differently about what it means to understand a scene.
🔗 visualjenga.github.io
📄 arxiv.org/abs/2503.21770
29.03.2025 19:36 —
👍 1
🔁 0
💬 0
📌 0
[9/10] Visual Jenga is a call to rethink what scene understanding should mean in 2025 and beyond.
We’re just getting started. There’s still a long way to go before models understand scenes like humans do. Our task is a small, playful, and rigorous step in that direction.
29.03.2025 19:36 —
👍 0
🔁 0
💬 1
📌 0
[8/10] This simple idea surprisingly scales to a wide range of scenes: from clean setups like a cat on a table or a stack of bowls... to messy, real-world scenes (yes, even Alyosha’s office).
29.03.2025 19:36 —
👍 1
🔁 0
💬 2
📌 0

[7/10] Why does this work? Because generative models have internalized asymmetries in the visual world.
Search for “cups” → You’ll almost always see a table.
Search for “tables” → You rarely see cups.
So: P(table | cup) ≫ P(cup | table)
We exploit this asymmetry to guide counterfactual inpainting
29.03.2025 19:36 —
👍 2
🔁 0
💬 1
📌 0

[6/10] We measure dependencies by masking each object, then using a large inpainting model to hallucinate what should be there. If the replacements are diverse, the object likely isn't critical. If it consistently reappears, like the table under the cat, it’s probably a support.
29.03.2025 19:36 —
👍 1
🔁 0
💬 1
📌 0
[5/10] To solve Visual Jenga, we start with a surprising baseline without explicit physical reasoning & any 3D, simulation, or dynamics. Instead, we propose a training-free, generative approach that infers object removal order by exploiting statistical co-occurrence learned by generative models.
29.03.2025 19:36 —
👍 0
🔁 0
💬 1
📌 0
[4/10] The goal of Visula Jenga is simple:
1) Remove one object at a time
2) Generate a sequence down to the background
3) Keep every intermediate scene physically & geometrically stable
29.03.2025 19:36 —
👍 0
🔁 0
💬 1
📌 0
[3/10] Probing this understanding motivates our new task: Visual Jenga, a challenge beyond passive observation.
Like in the game of Jenga, success demands understanding structural dependencies. Which objects can you remove without collapsing the scene? That’s where true understanding begins.
29.03.2025 19:36 —
👍 0
🔁 0
💬 1
📌 0