
paper: aclanthology.org/2025.acl-dem...
demo: youtu.be/fQFwOxzR4MI

@rapha.dev.bsky.social
PhD @ UniMelb NLP, with a healthy dose of MT Based in 🇮🇩, worked in 🇹🇱 🇵🇬 , from 🇫🇷
paper: aclanthology.org/2025.acl-dem...
demo: youtu.be/fQFwOxzR4MI
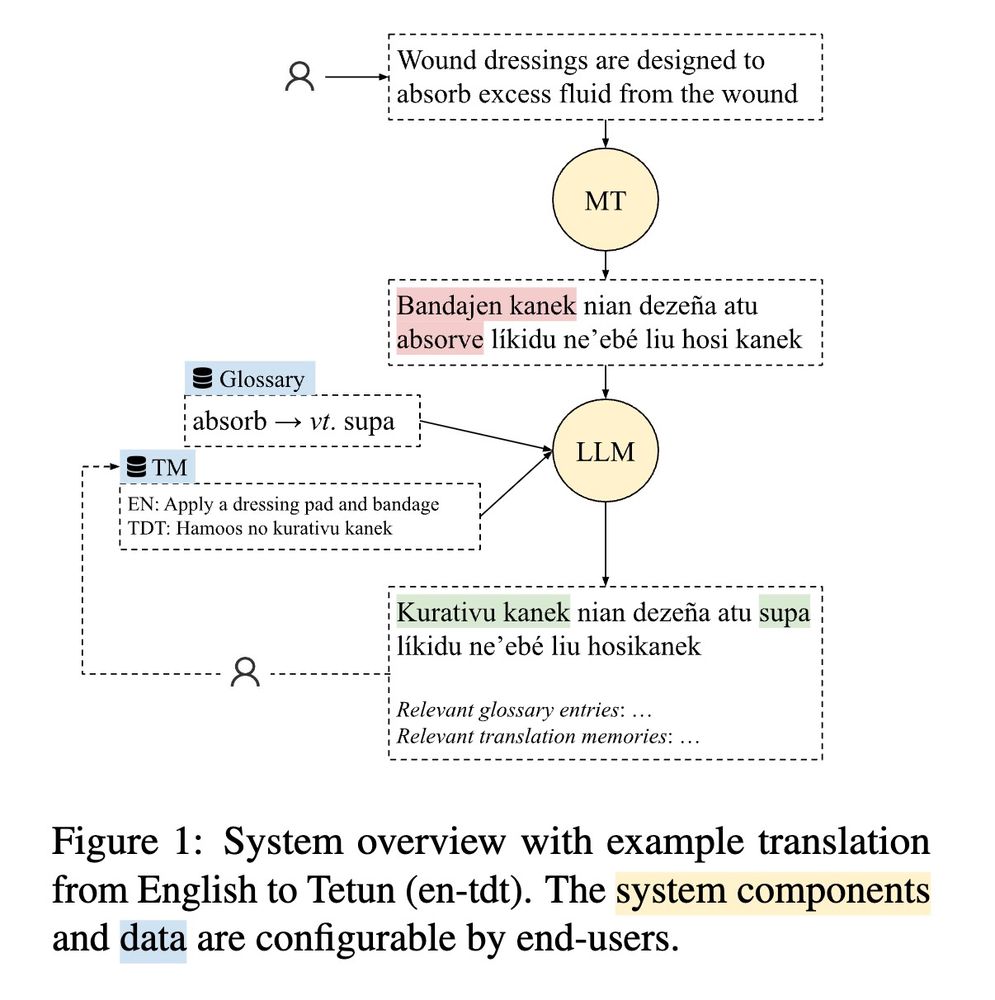

in Vienna for ACL, presenting Tulun, a system for low-resource in-domain translation, using LLMs
Tuesday @ 4pm
Working w 2 real use cases: medical translation into Tetun 🇹🇱 & disaster relief speech translation in Bislama 🇻🇺
Cool paper, at the intersection of grammar and LLM interpretability.
I like that they use linguistic datasets for their experiments, then get results that can contribute to linguistics as a field too! (on structural priming vs L1/L2)
Thanks a lot! I didn't make it to Albuquerque unfortunately, but I hope to be in Vienna for ACL. Might see you there?
26.05.2025 02:25 — 👍 0 🔁 0 💬 1 📌 0
Many thanks to Adérito Correia (Timor-Leste INL), and my supervisors Hanna Suominen Katerina Vylomova!
Paper at aclanthology.org/2025.loresmt... , video presentation at youtu.be/8zenieJWRyg
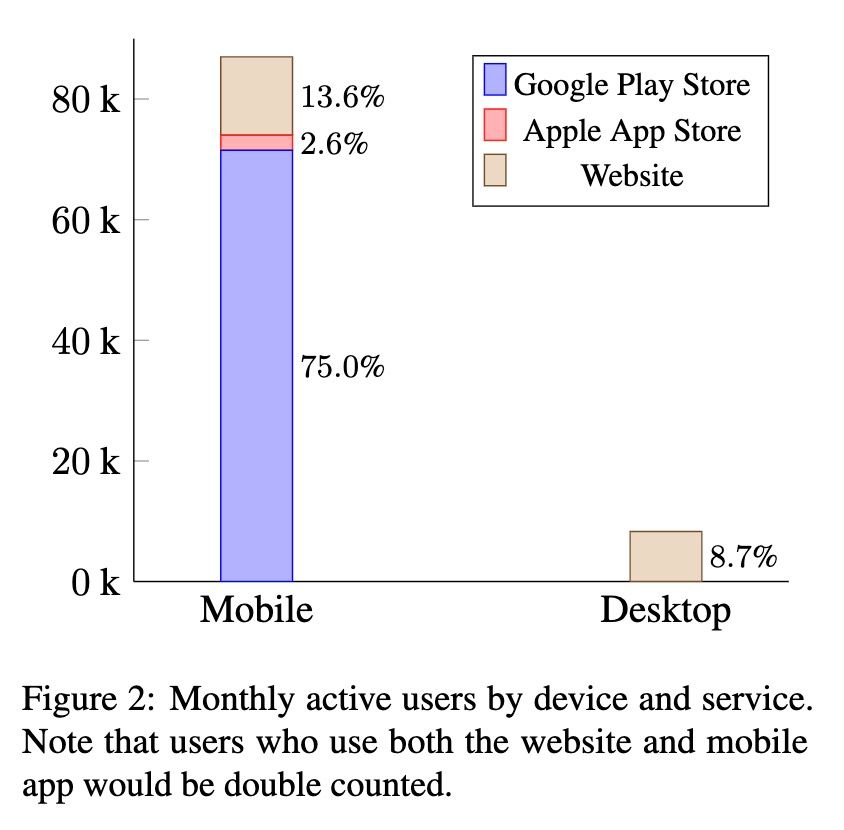
(3) The vast majority of usage is on mobile (over 90% of users / over 80k devices)
Takeaway: publishing MT model in mobile apps is probably more impactful than setting up a website / HuggingFace space.
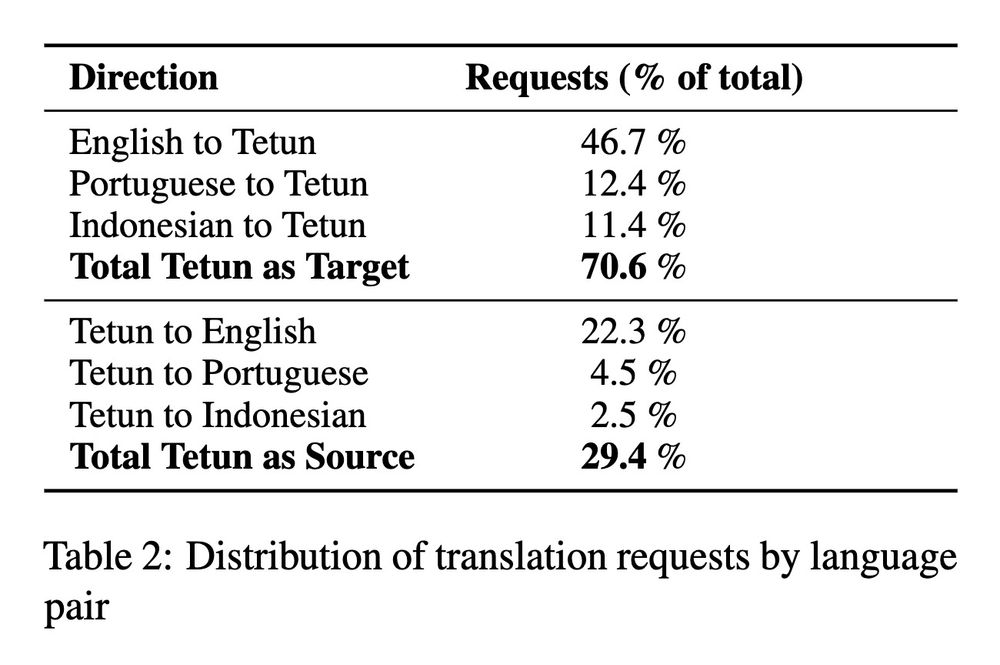
(2) Translation into Tetun is in higher demand (by >2x) than translation from Tetun
Takeaway for us MT folks: focus on translation into low-res langs, harder but more impactful
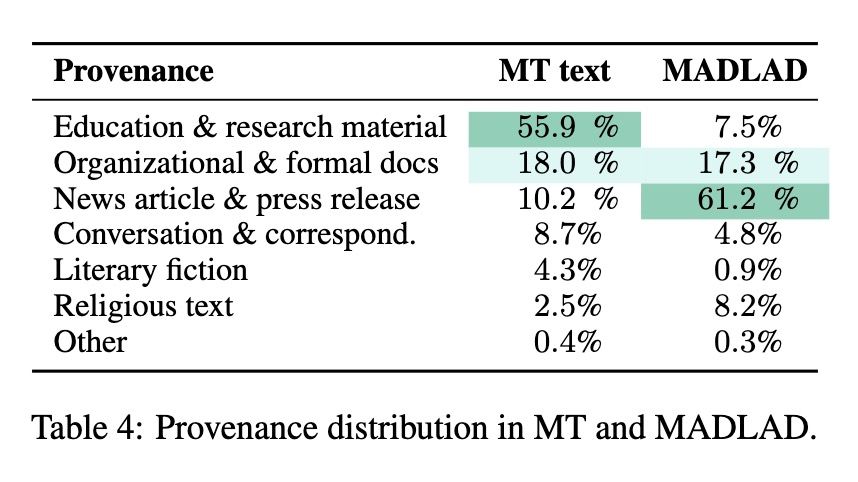
We find that
(1) a LOT of usage is for educational purposes (>50% of translated text)
--> contrasts sharply with Tetun corpora (e.g. MADLAD), dominated by news & religion.
Takeaway: don't evaluate MT on overrepresented domains (e.g. religion)! You risk misrepresenting end-user exp.
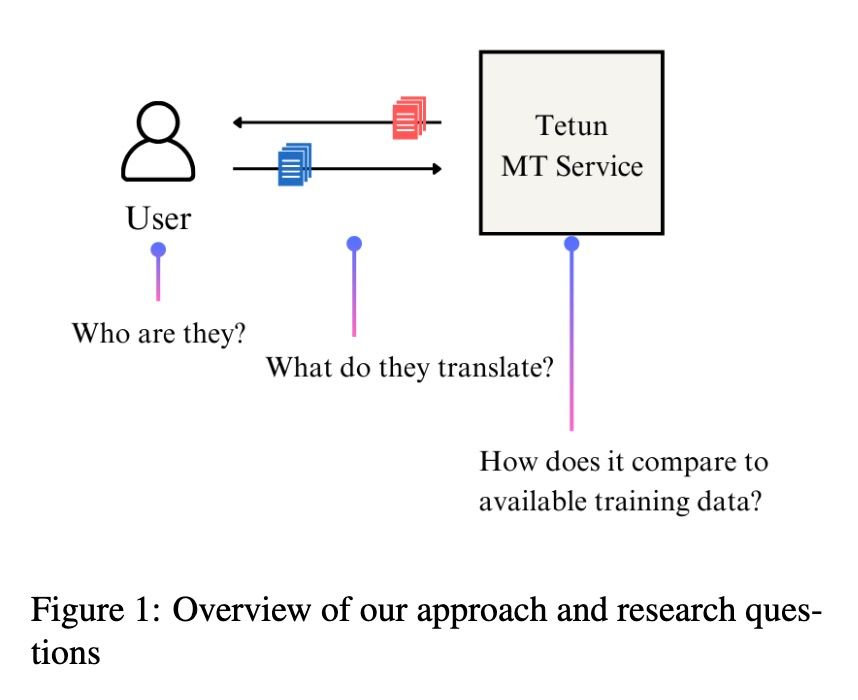
Our paper on who uses tetun.org, and what for, got published at the LoResMT 2025 workshop! An emotional paper for me, going back to the project that got me into a machine learning PhD in the first place.
25.05.2025 01:11 — 👍 3 🔁 0 💬 2 📌 0Very interesting findings, particularly the benefit (or lack thereof) of test-time scaling across domains
13.05.2025 00:40 — 👍 0 🔁 0 💬 0 📌 0My favourite ICLR paper so far. Methodology, findings and their implications are all very cool.
In particular Fig. 2 + this discussion point:
Incredible paper, finding that large companies can game the LMArena through statistical noise (via many model submissions), over-sampling of their models, and overfitting to Arena-style prompts (without real gains on model reasoning)
The experiments they run to show this are pretty cool too!
Cool summary of issues with multilingual LLM eval, and potential solutions!
If you're doubtful of all these non-reproducible evals on translated multiple choice questions, this paper is for you
GlotEval - a unified framework for multilingual eval of LLMs, on 7 different tasks, by @tiedeman.bsky.social @helsinki-nlp.bsky.social
Just wish it supported eval of closed models (e.g. through LiteLLM?)
github.com/MaLA-LM/Glot...

PyConAU We are on BlueSky! Follow us and stay tuned! @pyconau.bsky.social
👋 Hey Bluesky!
We’ve just touched down and we’re excited to be here 🌤️🐍
This is the official PyCon AU account, your go-to space for updates, announcements, and all things Python in Australia✨
Hit that follow button and stay tuned because we’ve got some awesome things coming your way!
#PyConAU
AI dev tools. In particular agents: are they hype or useful or both?
31.03.2025 03:20 — 👍 0 🔁 0 💬 0 📌 0Perceptricon
26.03.2025 08:29 — 👍 1 🔁 0 💬 0 📌 0The right thing to do, thanks for this *SEM
17.03.2025 08:19 — 👍 2 🔁 0 💬 0 📌 0Super impactful, thank you for this! A natural sequel of Gatitos.
I'm esp. fond of your "researcher in the loop" method to ensure wide vocab coverage.

😼SMOL DATA ALERT! 😼Anouncing SMOL, a professionally-translated dataset for 115 very low-resource languages! Paper: arxiv.org/pdf/2502.12301
Huggingface: huggingface.co/datasets/goo...
Been hearing a lot about recency bias lately. Must be pretty important
15.01.2025 03:10 — 👍 121 🔁 27 💬 0 📌 0Such a well put together video! Gherkins in the background got a supporting role
17.02.2025 01:35 — 👍 1 🔁 0 💬 1 📌 0Congrats! I'm just getting started but really liked your papers. Cool, impactful and well-written
24.01.2025 08:57 — 👍 1 🔁 0 💬 0 📌 0
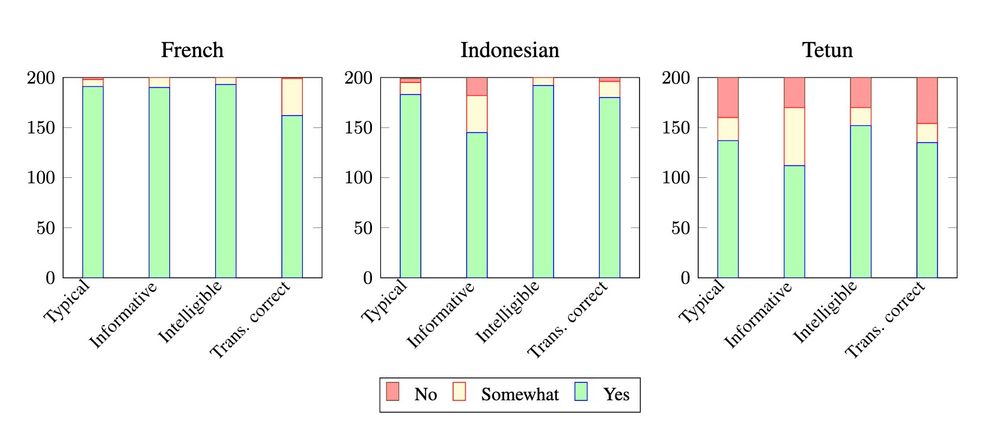
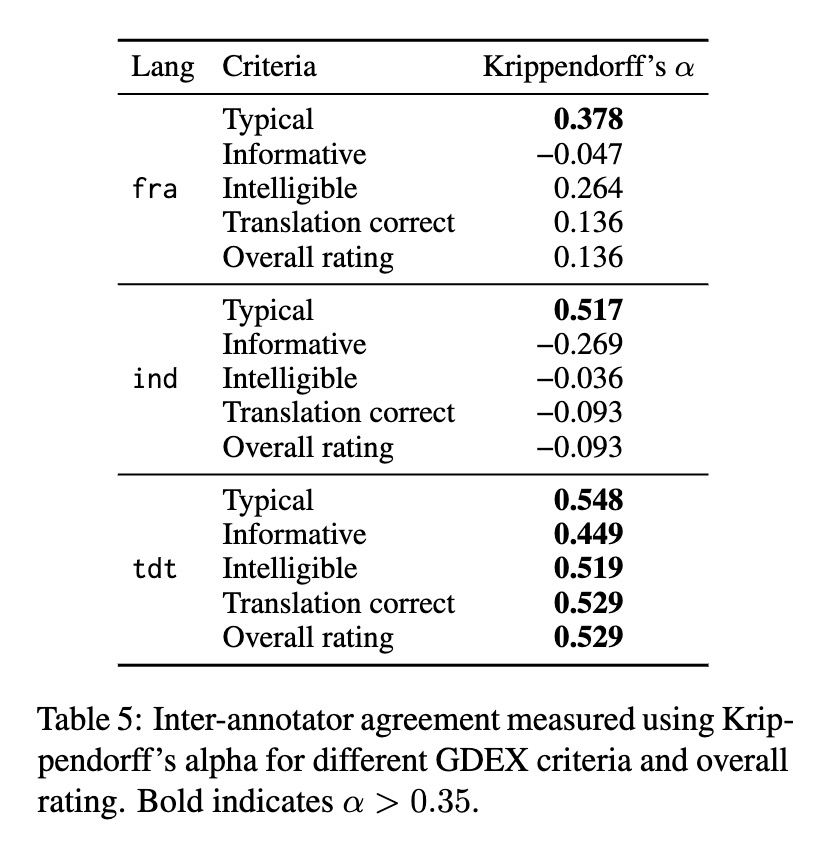
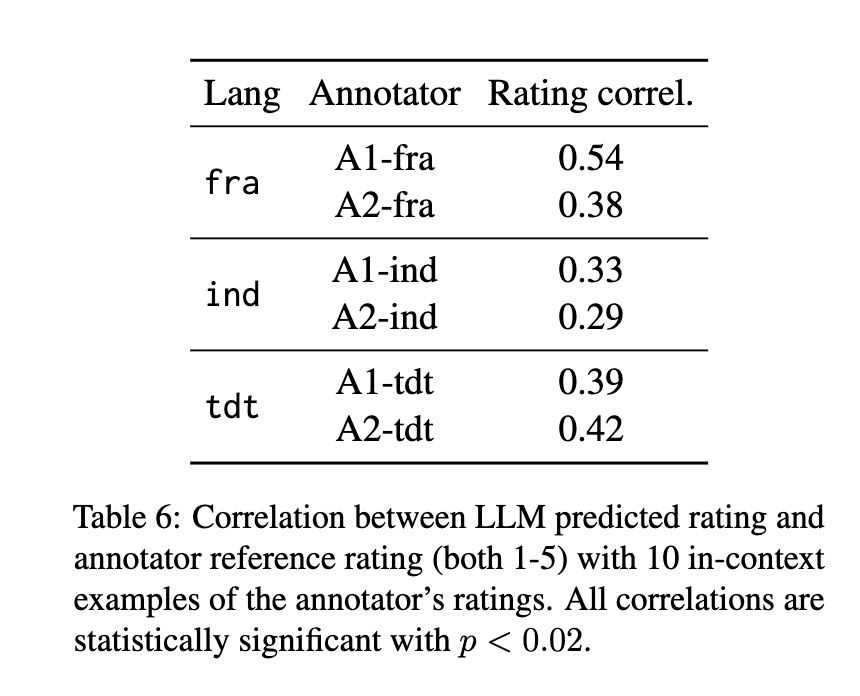
Our paper on generating bilingual example sentences with LLMs got best paper award @ ALTA in Canberra!
arxiv.org/abs/2410.03182
We work with French / Indonesian / Tetun, find that annotators don't agree about what's a "good example", but that LLMs can align with a specific annotator.

Another example of why we need evals that take clinical risk into account when training NLP models for health
slator.com/openais-whis...
Yes pls!
21.11.2024 01:32 — 👍 1 🔁 0 💬 0 📌 0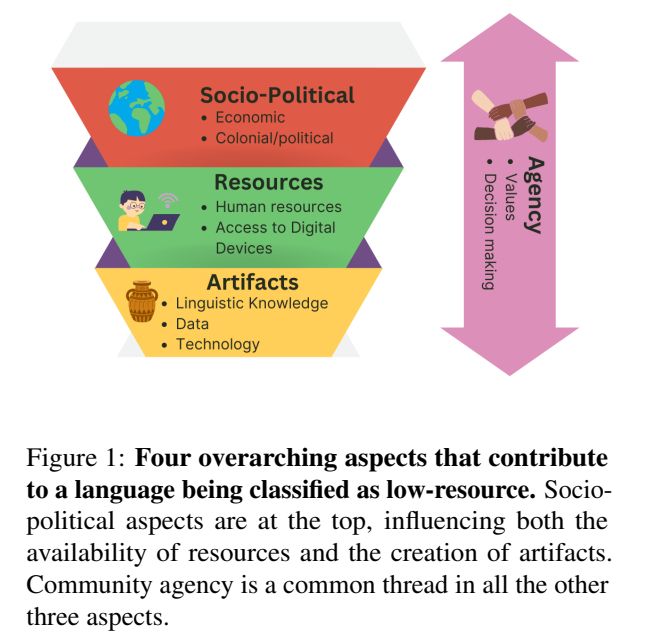
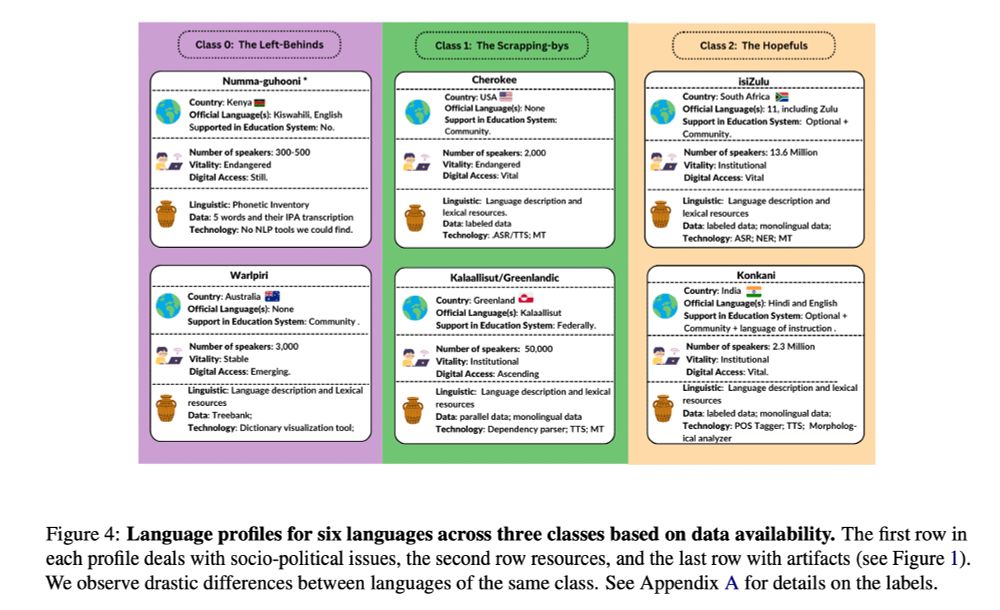
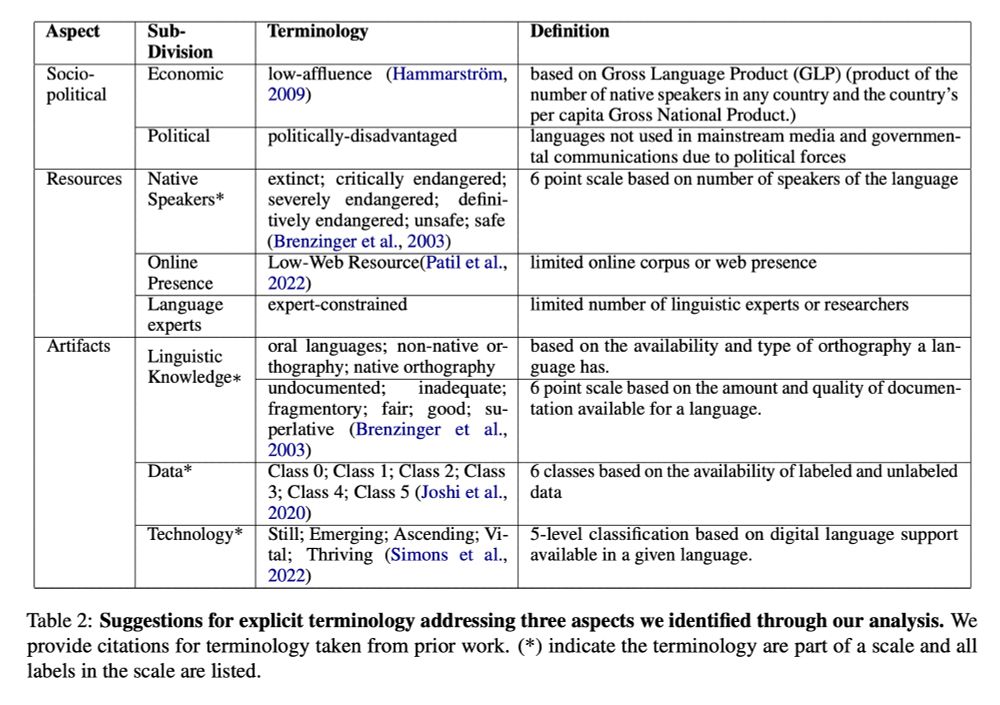
What do it mean to be a “low resourced” language? I’ve seen definitions for less training data to low number of speakers. Great to see this important clarifying work at #EMNLP2024 from @hellinanigatu.bsky.social et al
aclanthology.org/2024.emnlp-m...
this guy lives rent free in my hippocampus
20.11.2024 07:01 — 👍 0 🔁 0 💬 0 📌 0
Is productionisation (and move to gimmicks like CoT in o1-preview) at OpenAI and Anthropic a sign that scaling laws are slowing? And if so, where are we headed in LLMs?
Slightly pretentious but enjoyable read: www.generalist.com/briefing/the...




















