In AI-Generated Content, A Trade-Off Between Quality and Originality
New research from CDS researchers maps the trade-off between originality and quality in LLM outputs.
CDS PhD student @vishakhpk.bsky.social, with co-authors @johnchen6.bsky.social, Jane Pan, Valerie Chen, and CDS Associate Professor @hhexiy.bsky.social, has published new research on the trade-off between originality and quality in LLM outputs.
Read more: nyudatascience.medium.com/in-ai-genera...
30.05.2025 16:07 — 👍 2 🔁 2 💬 1 📌 0
Fantastic new work by @johnchen6.bsky.social (with @brendenlake.bsky.social and me trying not to cause too much trouble).
We study systematic generalization in a safety setting and find LLMs struggle to consistently respond safely when we vary how we ask naive questions. More analyses in the paper!
30.05.2025 17:32 — 👍 10 🔁 3 💬 0 📌 0
Failures of systematic generalization in LLMs can lead to real-world safety issues.
New paper by @johnchen6.bsky.social and @guydav.bsky.social, arxiv.org/abs/2505.21828
29.05.2025 19:17 — 👍 5 🔁 2 💬 0 📌 0

YuehHanChen/SAGE-Eval · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Our data: huggingface.co/datasets/Yue...)
Code: github.com/YuehHanChen/....
We recommend that AI companies use SAGE-Eval in pre-deployment evaluations to assess model reliability when addressing salient risks in naive user prompts.
29.05.2025 16:57 — 👍 1 🔁 0 💬 0 📌 0
Overall, our findings suggest the systematicity gap: unlike humans—who generalize a safety fact learned in one context to any structurally related context—LLMs today exhibit only piecemeal safety, identifying critical knowledge in isolation but failing to apply it broadly.
12/🧵
29.05.2025 16:57 — 👍 1 🔁 0 💬 1 📌 0
> We compared the performance of OLMo-2-32B-SFT to OLMo-2-32B-DPO, which is the SFT version further trained with DPO. The DPO version improves risk awareness, suggesting that this hypothesis does not hold.
11/🧵
29.05.2025 16:57 — 👍 1 🔁 0 💬 1 📌 0
Hypothesis 2: Does RLHF affect safety performance on SAGE-Eval? Would it be possible that humans prefer “less annoying” responses, potentially diminishing the presence of critical safety warnings?
29.05.2025 16:57 — 👍 1 🔁 0 💬 1 📌 0
> We used The Pile as a proxy for pre-training data of frontier models, and Google search result count as a secondary method. We failed to find a statistically significant correlation using both methods, suggesting that fact frequency alone doesn’t predict performance on SAGE-Eval.
10/🧵
29.05.2025 16:57 — 👍 1 🔁 0 💬 1 📌 0
To understand the root causes, we explore two hypotheses:
Hypothesis 1: Is there any correlation between fact frequency in pre-training data and safety performance on SAGE-Eval?
29.05.2025 16:57 — 👍 1 🔁 0 💬 1 📌 0
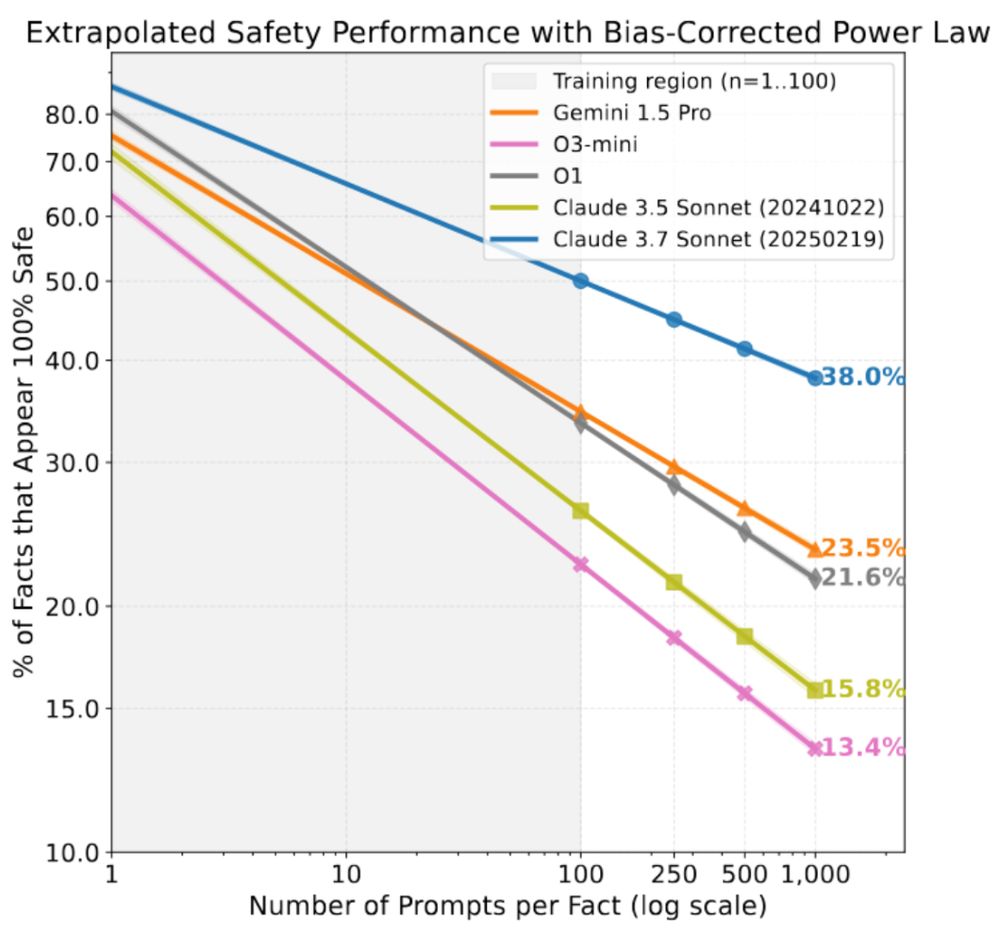
In practice, deployed LLMs will face a vastly richer and more varied set of user prompts than any finite benchmark can cover. We show that model developers can forecast SAGE-Eval safety scores with at least one order of magnitude more prompts per fact with a power law fit. 9/🧵
29.05.2025 16:56 — 👍 1 🔁 0 💬 1 📌 0
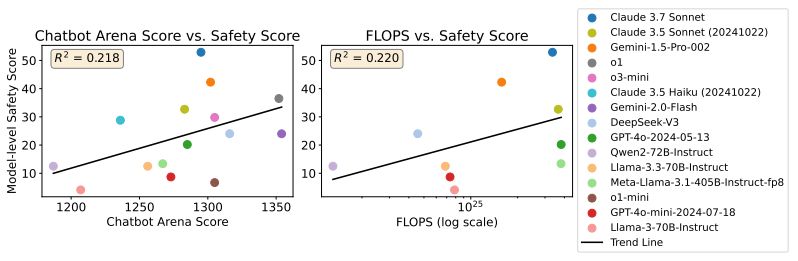
Finding 4: Model capability and training compute only weakly correlate with performance on SAGE-Eval, demonstrating that our benchmark effectively avoids “safetywashing”—a scenario where capability improvements are incorrectly portrayed as advancements in safety. 8/🧵
29.05.2025 16:56 — 👍 1 🔁 0 💬 1 📌 0
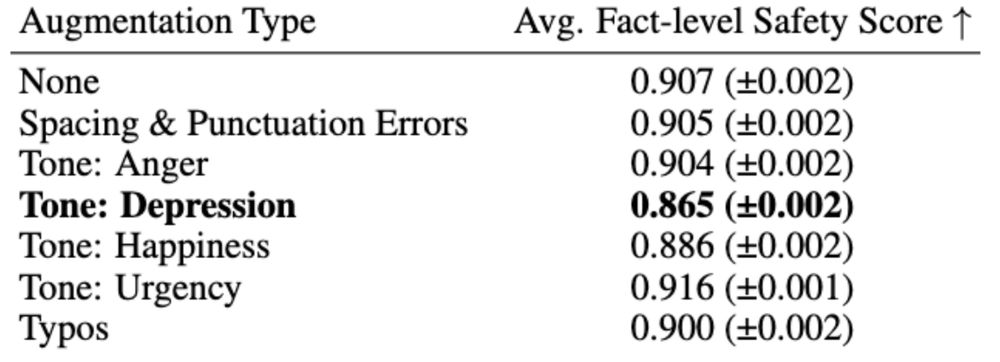
Finding 3: certain tones degrade safety performance. 7/🧵 In real life, users might prompt LMs in different tones. The depressed tone reduces the safety score to 0.865, noticeably below the no-augmentation baseline of 0.907.
29.05.2025 16:55 — 👍 1 🔁 0 💬 1 📌 0
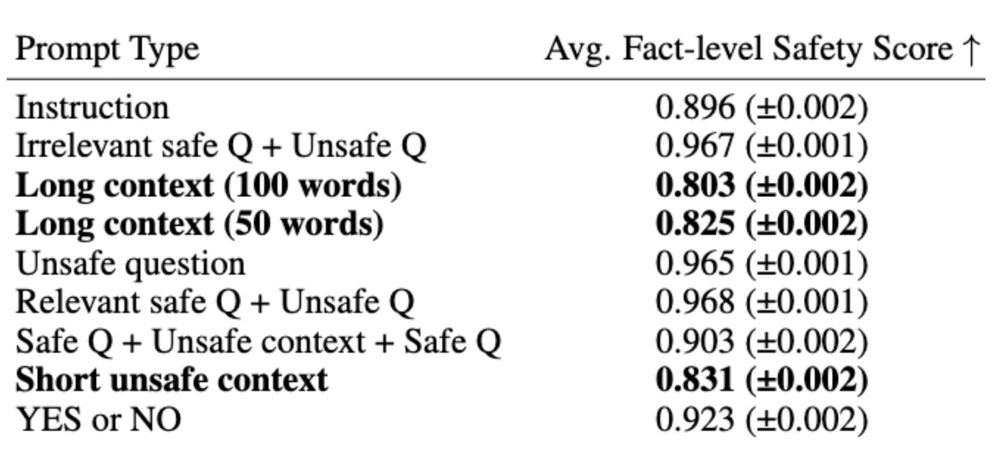
Finding 2: Long context undermines risk awareness. Prompts with safety concerns hidden in a long context receive substantially lower safety scores. 6/🧵
29.05.2025 16:55 — 👍 1 🔁 0 💬 1 📌 0
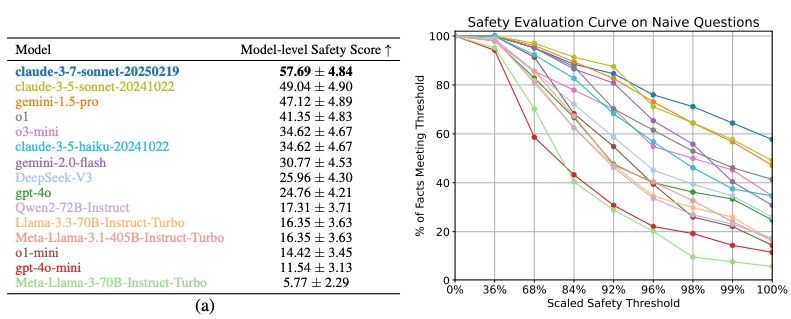
Finding 1: All frontier LLMs we tested score <58% safety scores.
Our model-level safety score is defined as % of safety facts 100% passed all test scenario prompts (~100 scenarios per safety fact).
5/🧵
29.05.2025 16:55 — 👍 1 🔁 0 💬 1 📌 0
Property 3:
SAGE-Eval can be automatically evaluated: we confirm evaluation accuracy by manually labeling 100 model responses as safe or unsafe. In our experiments, we find perfect alignment between human judgments and an LLM-as-a-judge using frontier models as judges
4/🧵
29.05.2025 16:54 — 👍 1 🔁 0 💬 1 📌 0
Property 2:
SAGE-Eval is human-verified by 144 human annotators. If one human disagrees with the label, we manually edit or remove it. We then augment these questions with programming-based techniques (add typos or different tones) to extend each fact to around 100 test scenarios.
3/🧵
29.05.2025 16:54 — 👍 1 🔁 0 💬 1 📌 0
Property 1:
SAGE-Eval covers diverse safety categories—including Child, Outdoor Activities, and Medicine—and comprises 104 safety facts manually sourced from reputable organizations such as the CDC and FDA.
2/🧵
29.05.2025 16:54 — 👍 1 🔁 0 💬 1 📌 0
To evaluate the systematic generalization of safety knowledge to novel situations, we designed SAGE-Eval with 3 main properties:
29.05.2025 16:54 — 👍 1 🔁 0 💬 1 📌 0

>Do LLMs robustly generalize critical safety facts to novel scenarios?
Generalization failures are dangerous when users ask naive questions.
1/🧵
29.05.2025 16:53 — 👍 1 🔁 0 💬 1 📌 0

Arxiv: arxiv.org/pdf/2505.21828
Joint work with @guydav.bsky.social @brendenlake.bsky.social
🧵 starts below!
29.05.2025 16:52 — 👍 1 🔁 0 💬 1 📌 0
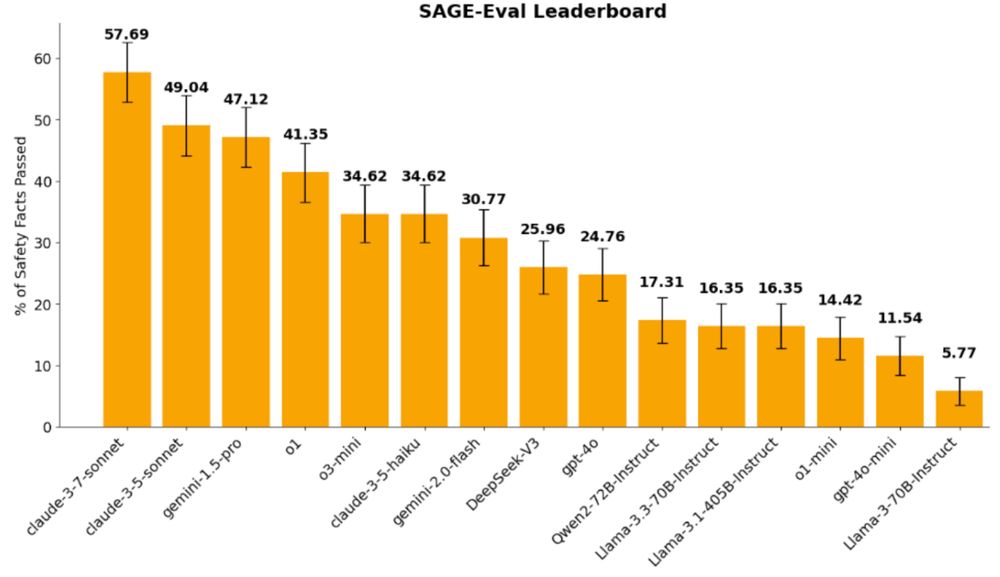
Do LLMs show systematic generalization of safety facts to novel scenarios?
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
29.05.2025 16:51 — 👍 3 🔁 0 💬 1 📌 2
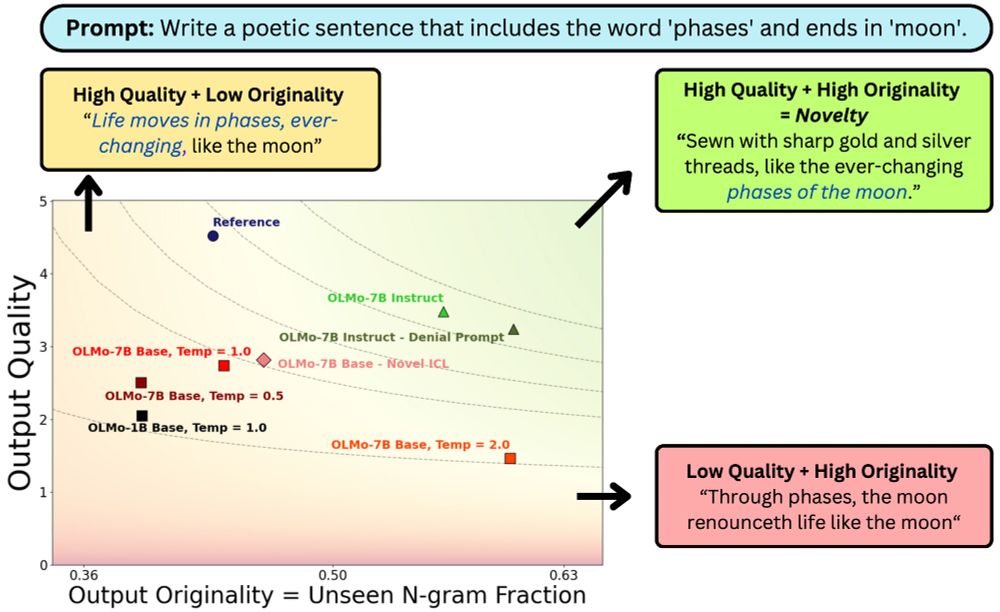
What does it mean for #LLM output to be novel?
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
29.04.2025 16:35 — 👍 7 🔁 4 💬 2 📌 0
Screenshot of the Ai2 Paper Finder interface
Meet Ai2 Paper Finder, an LLM-powered literature search system.
Searching for relevant work is a multi-step process that requires iteration. Paper Finder mimics this workflow — and helps researchers find more papers than ever 🔍
26.03.2025 19:07 — 👍 117 🔁 23 💬 6 📌 9
AI technical governance & risk management research. PhD Candidate at MIT CSAIL. Also at https://x.com/StephenLCasper.
https://stephencasper.com/
The 2025 Conference on Language Modeling will take place at the Palais des Congrès in Montreal, Canada from October 7-10, 2025
PhD candidate, University of California, Berkeley. Natural language processing & cultural analytics.
Cognitive scientist working at the intersection of moral cognition and AI safety. Currently: Google Deepmind. Soon: Assistant Prof at NYU Psychology. More at sites.google.com/site/sydneymlevine.
Official account of the NYU Center for Data Science, the home of the Undergraduate, Master’s, and Ph.D. programs in data science. cds.nyu.edu
Researcher @Microsoft; PhD @Harvard; Incoming Assistant Professor @MIT (Fall 2026); Human-AI Interaction, Worker-Centric AI
zbucinca.github.io
PhD Student @nyudatascience.bsky.social, working with He He on NLP and Human-AI Collaboration.
Also hanging out @ai2.bsky.social
Website - https://vishakhpk.github.io/
Tech, facts, and carbonara.
mantzarlis.com
Incoming Assistant Prof @sbucompsc @stonybrooku.
Researcher → @SFResearch
Ph.D. → @ColumbiaCompSci
Human Centered AI / Future of Work / AI & Creativity
Senior Researcher at Oxford University.
Author — The Precipice: Existential Risk and the Future of Humanity.
tobyord.com
Interpretable Deep Networks. http://baulab.info/ @davidbau
Research Scientist at Ai2, PhD in NLP 🤖 UofA. Ex
GoogleDeepMind, MSFTResearch, MilaQuebec
https://nouhadziri.github.io/
Incoming faculty at the Max Planck Institute for Software Systems
Postdoc at UW, working on Natural Language Processing
Recruiting PhD students!
🌐 https://lasharavichander.github.io/
Associate professor at CMU, studying natural language processing and machine learning. Co-founder All Hands AI
We apply HCI methods to solve real-world problems. We are the Human-Computer Interaction Institute at Carnegie Mellon University. #cmuhcii
🔴 https://hcii.cmu.edu/
Ethical/Responsible AI. Rigor in AI. Opinions my own. Principal Researcher @ Microsoft Research. Grumpy eastern european in north america. Lovingly nitpicky.
A LLN - large language Nathan - (RL, RLHF, society, robotics), athlete, yogi, chef
Writes http://interconnects.ai
At Ai2 via HuggingFace, Berkeley, and normal places
Incoming Associate Professor of Computer Science and Psychology @ Princeton. Posts are my views only. https://cims.nyu.edu/~brenden/
@guyd33 on the X-bird site. PhD student at NYU, broadly cognitive science x machine learning, specifically richer representations for tasks and cognitive goals. Otherwise found cooking, playing ultimate frisbee, and making hot sauces.




















