In AI-Generated Content, A Trade-Off Between Quality and Originality
New research from CDS researchers maps the trade-off between originality and quality in LLM outputs.
CDS PhD student @vishakhpk.bsky.social, with co-authors @johnchen6.bsky.social, Jane Pan, Valerie Chen, and CDS Associate Professor @hhexiy.bsky.social, has published new research on the trade-off between originality and quality in LLM outputs.
Read more: nyudatascience.medium.com/in-ai-genera...
30.05.2025 16:07 — 👍 2 🔁 2 💬 1 📌 0

And prompting tricks like asking for novelty and denial prompting trade-off originality and quality without meaningfully shifting the frontier of novelty …. so there’s lot more work to be done 😀
29.04.2025 16:35 — 👍 1 🔁 0 💬 1 📌 0
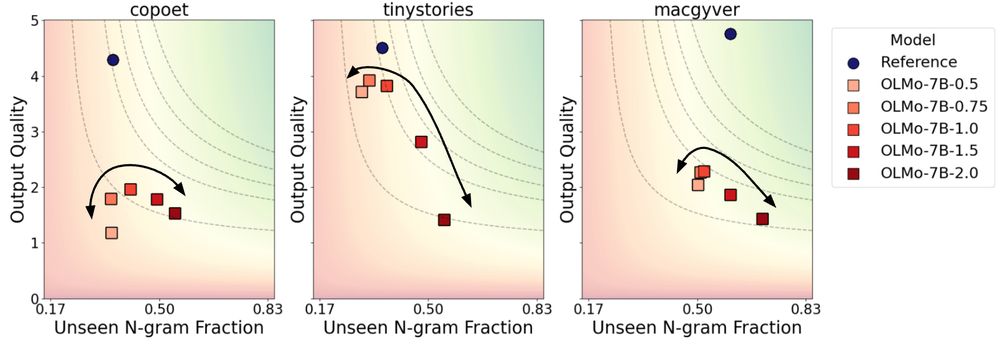
Sure, but can we elicit more novelty at inference time? Turns out it’s tricky. Increasing sampling temperatures (from 0.5 to 2) boosts originality but can hurt quality, creating a U-shaped effect.
29.04.2025 16:35 — 👍 1 🔁 0 💬 1 📌 0
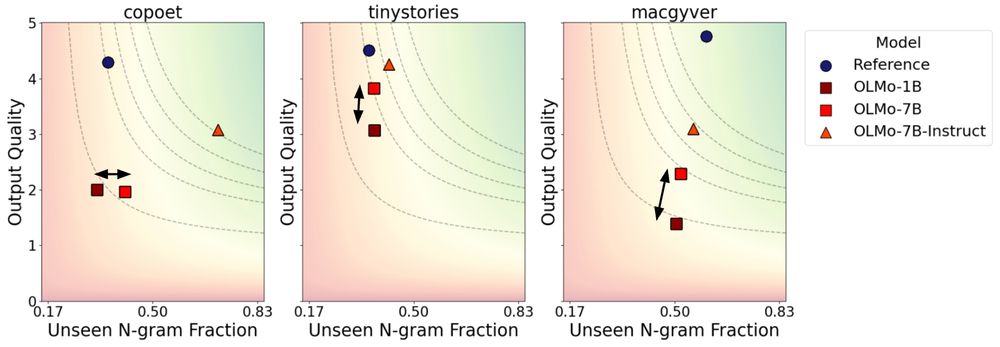

But improving the underlying model can help yield more novel output! This can either be by (a) increasing model scale (1B -> 7B), and (b) instruction tuning (7B -> 7B-Instruct)
29.04.2025 16:35 — 👍 0 🔁 0 💬 1 📌 0
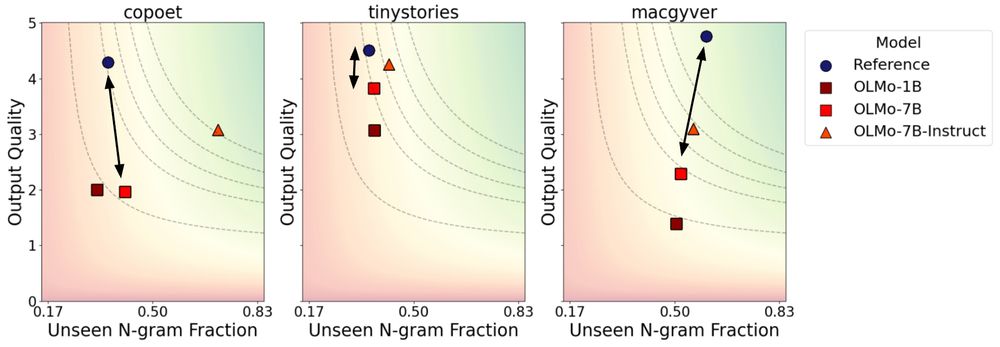
We find that base LLMs often generate less novel output than human-written references from the datasets
29.04.2025 16:35 — 👍 0 🔁 0 💬 1 📌 0
We evaluate the novelty of OLMo and Pythia models on 3 creative tasks:
📝 Story completion (TinyStories)
🎨 Poetry writing (Help Me Write a Poem)
🛠️ Creative tool use (MacGyver)
Novelty = harmonic mean of output quality (LLM-as-judge) and originality (unseen n-gram fraction).
29.04.2025 16:35 — 👍 0 🔁 0 💬 1 📌 0
Considering originality and quality separately is not enough—human prefs on quality can favor outputs reproducing training data (users may not recognize this) while originality alone can reward incoherent generations. These are often at odds & should be evaluated together💡
29.04.2025 16:35 — 👍 1 🔁 0 💬 1 📌 0
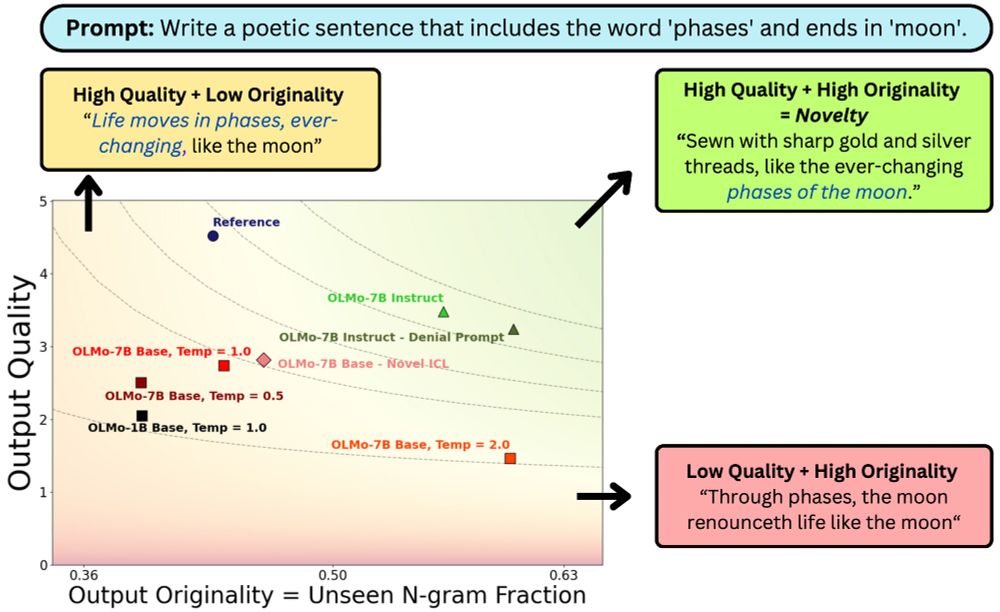
What does it mean for #LLM output to be novel?
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
29.04.2025 16:35 — 👍 7 🔁 4 💬 2 📌 0
When using LLM-as-a-judge, practitioners often use greedy decoding to get the most likely judgment. But we found that deriving a score from the judgment distribution (like taking the mean) works better!
❌LLM-as-a-judge with greedy decoding
😎Using the distribution of the judge’s labels
06.03.2025 22:04 — 👍 28 🔁 4 💬 1 📌 0

LLM judges have become ubiquitous, but valuable signal is often ignored at inference.
We analyze design decisions for leveraging judgment distributions from LLM-as-a-judge: 🧵
(w/ Michael J.Q. Zhang, @eunsol.bsky.social)
06.03.2025 14:32 — 👍 17 🔁 4 💬 7 📌 1

Distributional Scaling Laws for Emergent Capabilities
Rosie Zhao, Tian Qin, David Alvarez-Melis, Sham Kakade, Naomi Saphra
In this paper, we explore the nature of sudden breakthroughs in language model performance at scale, which stands in contrast to smooth improvements governed by scaling laws. While advocates of "emergence" view abrupt performance gains as capabilities unlocking at specific scales, others have suggested that they are produced by thresholding effects and alleviated by continuous metrics. We propose that breakthroughs are instead driven by continuous changes in the probability distribution of training outcomes, particularly when performance is bimodally distributed across random seeds. In synthetic length generalization tasks, we show that different random seeds can produce either highly linear or emergent scaling trends. We reveal that sharp breakthroughs in metrics are produced by underlying continuous changes in their distribution across seeds. Furthermore, we provide a case study of inverse scaling and show that even as the probability of a successful run declines, the average performance of a successful run continues to increase monotonically. We validate our distributional scaling framework on realistic settings by measuring MMLU performance in LLM populations. These insights emphasize the role of random variation in the effect of scale on LLM capabilities.
Ever looked at LLM skill emergence and thought 70B parameters was a magic number? Our new paper shows sudden breakthroughs are samples from bimodal performance distributions across seeds. Observed accuracy jumps abruptly while the underlying accuracy DISTRIBUTION changes slowly!
25.02.2025 22:33 — 👍 66 🔁 15 💬 3 📌 2

🚨New Paper! So o3-mini and R1 seem to excel on math & coding. But how good are they on other domains where verifiable rewards are not easily available, such as theory of mind (ToM)? Do they show similar behavioral patterns? 🤔 What if I told you it's...interesting, like the below?🧵
20.02.2025 17:34 — 👍 22 🔁 5 💬 3 📌 1

🤔 Ever wondered how prevalent some type of web content is during LM pre-training?
In our new paper, we propose WebOrganizer which *constructs domains* based on the topic and format of CommonCrawl web pages 🌐
Key takeaway: domains help us curate better pre-training data! 🧵/N
18.02.2025 12:31 — 👍 26 🔁 8 💬 1 📌 3

(1/9) Excited to share my recent work on "Alignment reduces LM's conceptual diversity" with @tomerullman.bsky.social and @jennhu.bsky.social, to appear at #NAACL2025! 🐟
We want models that match our values...but could this hurt their diversity of thought?
Preprint: arxiv.org/abs/2411.04427
10.02.2025 17:20 — 👍 63 🔁 10 💬 2 📌 4

« appending "Wait" multiple times to the model's generation » is our current most likely path to AGI :)
See the fresh arxiv.org/abs/2501.19393 by Niklas Muennighoff et al.
03.02.2025 14:31 — 👍 62 🔁 12 💬 0 📌 2

Even Simple Search Tasks Reveal Fundamental Limits in AI Language Models
Research by CDS’ He He, Vishakh Padmakumar, and others shows that LLMs’ reasoning relies on heuristics, not systematic exploration.
CDS' He He, @vishakhpk.bsky.social, & former CDS postdoc Abulhair Saparov, et al, find major AI limits in “Transformers Struggle to Learn to Search.”
AI models excel at single-step reasoning but fail in systematic exploration as tasks grow in complexity.
nyudatascience.medium.com/even-simple-...
31.01.2025 17:30 — 👍 3 🔁 1 💬 0 📌 0
Thank you @bwaber.bsky.social! Made my day 😁💯
31.01.2025 14:00 — 👍 1 🔁 0 💬 1 📌 0

People often claim they know when ChatGPT wrote something, but are they as accurate as they think?
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
28.01.2025 14:55 — 👍 187 🔁 66 💬 10 📌 19

A plot showing LLM performance on various algorithmic tasks. For all LLMs evaluated, including o1-preview, performance is highly influenced by the probability of the output to be produced, with lower performance on cases with low-probability outputs. The tasks being evaluated on are shift ciphers, Pig Latin, article swapping, and reversal.
🔥While LLM reasoning is on people's minds...
Here's a shameless plug for our work comparing o1 to previous LLMs (extending "Embers of Autoregression"): arxiv.org/abs/2410.01792
- o1 shows big improvements over GPT-4
- But qualitatively it is still sensitive to probability
1/4
20.01.2025 19:28 — 👍 28 🔁 5 💬 1 📌 0
assistant professor in computer science / data science at NYU. studying natural language processing and machine learning.
a mediocre combination of a mediocre AI scientist, a mediocre physicist, a mediocre chemist, a mediocre manager and a mediocre professor.
see more at https://kyunghyuncho.me/
cs phd student and kempner institute graduate fellow at harvard.
interested in language, cognition, and ai
soniamurthy.com
PhD student @ UW, research @ Ai2
MIT Researcher, he/him, Senior Visiting Researcher @ Ritsumeikan, Co-Founder of Humanyze, former Senior Researcher @ HBS, author of People Analytics. AI, management, law, corporate governance, psychology, anthropology, ethics, and similar topics
Associate Professor, School of Information, UC Berkeley. NLP, computational social science, digital humanities.
John C Malone Professor at Johns Hopkins Computer Science, Center for Language and Speech Processing, Malone Center for Engineering in Healthcare.
Parttime: Bloomberg LP #nlproc
Perspectives my own, not those of my employer https://arjunsubramonian.github.io/
AI + Neurosciences Researcher @ MIT Media Lab
ninonlizemasclef.com
brain decoding • multimodal • media arts • audio
Official account of the NYU Center for Data Science, the home of the Undergraduate, Master’s, and Ph.D. programs in data science. cds.nyu.edu
Cognitive scientist, philosopher, and psychologist at Berkeley, author of The Scientist in the Crib, The Philosophical Baby and The Gardener and the Carpenter and grandmother of six.
I (try to) do NLP research. Antipodean abroad.
currently doing PhD @uwcse,
prev @usyd @ai2
🇦🇺🇨🇦🇬🇧
ivison.id.au
Doctor of NLP/Vision+Language from UCSB
Evals, metrics, multilinguality, multiculturality, multimodality, and (dabbling in) reasoning
https://saxon.me/
NLP PhD @ USC
Previously at AI2, Harvard
mattf1n.github.io
Associate professor in NLP, engaged citizen. Tweeting about work, life and stuffs that I care about. All my tweets can be used freely. @zehavoc@mastodon.social @zehavoc (@twitter)
NLP PhD student at Imperial College London and Apple AI/ML Scholar.
☀️ Assistant Professor of Computer Science at CU Boulder 👩💻 NLP, cultural analytics, narratives, online communities 🌐 https://maria-antoniak.github.io 💬 books, bikes, games, art
Climate & AI Lead @HuggingFace, TED speaker, WiML board member, TIME AI 100 (She/her/Dr/🦋)
Book: https://thecon.ai
Web: https://faculty.washington.edu/ebender






















