Like ~everyone, I'll also be at #NeurIPS this week! Please reach out to chat about past (goal representations, cognitive science, intrep) or current interests (LLM mental state inference, social environments for RL). Also if you have leads on great coffee, craft beer, or tacos.
01.12.2025 20:29 — 👍 11 🔁 0 💬 0 📌 0
Belated update #2: my year at Meta FAIR through the AIM program was so nice that I’m sticking around for the long haul.
I’m excited to stay at FAIR and work with @asli-celikyilmaz.bsky.social and friends on fun LLM questions; I’ll be working from the New York office so we’re sticking around.
19.09.2025 17:27 — 👍 8 🔁 1 💬 0 📌 0
Thank you, Ed!!
17.09.2025 21:06 — 👍 0 🔁 0 💬 0 📌 0
Tune in tomorrow for belated update #2, on post-PhD plans!
17.09.2025 19:45 — 👍 0 🔁 0 💬 0 📌 0

I owe tremendous thanks to many other people, all (or, hopefully, at least most) of whom I mentioned in my acknowledgments. I’m also so grateful my dad could represent my family, and for my wife, Sarah, for, well, everything.
17.09.2025 19:45 — 👍 0 🔁 0 💬 1 📌 0

Much, much larger thanks to my advisors, @brendenlake.bsky.social and @toddgureckis.bsky.social , for your guidance and mentorship over the last several years. I appreciate you so much, and this wouldn’t have looked the same without you!
17.09.2025 19:45 — 👍 2 🔁 0 💬 1 📌 0

Friends and virtual acquaintances! I’m defending my PhD tomorrow morning at 11:30 AM ET. If anyone would like to watch, let me know and I’ll send you the Zoom link (and if you’re in NYC and feel compelled to join in person, that works, too!)
06.08.2025 18:41 — 👍 9 🔁 0 💬 0 📌 0
Wherever good coffee is to be found, the rest of the time. Don't hesitate to reach out!
(also happy to talk about job search in industry and what that looks and feels like these days)
30.07.2025 15:47 — 👍 0 🔁 0 💬 0 📌 0

Goal Inference using Reward-Producing Programs in a Novel Physics Environment
Author(s): Davidson, Guy; Todd, Graham; Colas, CŽdric; Chu, Junyi; Togelius, Julian; Tenenbaum, Joshua B.; Gureckis, Todd M; Lake, Brenden | Abstract: A child invents a game, describes its rules, and ...
Saturday's poster session (P3-D-44) to talk about our goal inference work, in a new, physics-based environment we developed: escholarship.org/uc/item/6tb2...
30.07.2025 15:47 — 👍 0 🔁 0 💬 1 📌 0
Today's Minds in the Making: Design Thinking and Cognitive Science Workshop (Pacific E):
minds-making.github.io
30.07.2025 15:47 — 👍 1 🔁 0 💬 1 📌 0
#CogSci2025 friends! I'm here all week and would love to chat. I'd particularly love to talk to anyone thinking about Theory of Mind and how to evaluate it better (in both minds and machines, in different settings and contexts), and about goals and their representations. Find me at:
30.07.2025 15:47 — 👍 7 🔁 1 💬 1 📌 0
Cool new work on localizing and removing concepts using attention heads from colleagues at NYU and Meta!
08.07.2025 13:54 — 👍 4 🔁 0 💬 0 📌 0
You (yes, you!) should work with Sydney! Either short-term this summer, or longer term at her nascent lab at NYU!
06.06.2025 18:15 — 👍 4 🔁 0 💬 0 📌 0
Fantastic new work by @johnchen6.bsky.social (with @brendenlake.bsky.social and me trying not to cause too much trouble).
We study systematic generalization in a safety setting and find LLMs struggle to consistently respond safely when we vary how we ask naive questions. More analyses in the paper!
30.05.2025 17:32 — 👍 10 🔁 3 💬 0 📌 0

Guy Davidson
Guy Davidson's academic website
Finally, if this work makes you think "I'd like to work with this person," please reach out -- I'm on the job market for industry post-PhD roles (keywords: language models, interpretability, open-endedness, user intent understanding, alignment).
See more: guydavidson.me
23.05.2025 17:38 — 👍 3 🔁 0 💬 0 📌 0
As with pretty much everything else I've worked on in grad school, this work would have looked different (and almost certainly worse) without the guidance of my advisors, @brendenlake.bsky.social and @toddgureckis.bsky.social . I continue to appreciate your thoughtful engagement with my work! 16/N
23.05.2025 17:38 — 👍 0 🔁 0 💬 1 📌 0
This work would also have been impossible without @adinawilliams.bsky.social 's guidance, the freedom she gave me in picking a problem to study, and believing in me that I could tackle it despite it being my first foray into (mechanistic) interpretability work. 15/N
23.05.2025 17:38 — 👍 0 🔁 0 💬 1 📌 0
We owe a great deal of gratitude to @ericwtodd.bsky.social d , not only for open-sourcing their code, but also for answering our numerous questions over the last few months. If you find this interesting, you should also read their paper introducing function vectors. 14/N
23.05.2025 17:38 — 👍 0 🔁 0 💬 1 📌 0
See the paper for a description of the methods, the many different controls we ran, our discussion and limitations, examples of our instructions and baselines, and other odd findings (applying an FV twice can be beneficial! Some attention heads have negative causal effects!) 13/N
23.05.2025 17:38 — 👍 0 🔁 0 💬 1 📌 0

Finding 5 bonus: Which post-training steps facilitate this? Using the OLMo-2 model family, we find that the SFT and DPO stages each bring a jump in performance, but the final RLVR step doesn't make a difference for the ability to extract instruction FVs. 12/N
23.05.2025 17:38 — 👍 0 🔁 0 💬 1 📌 0
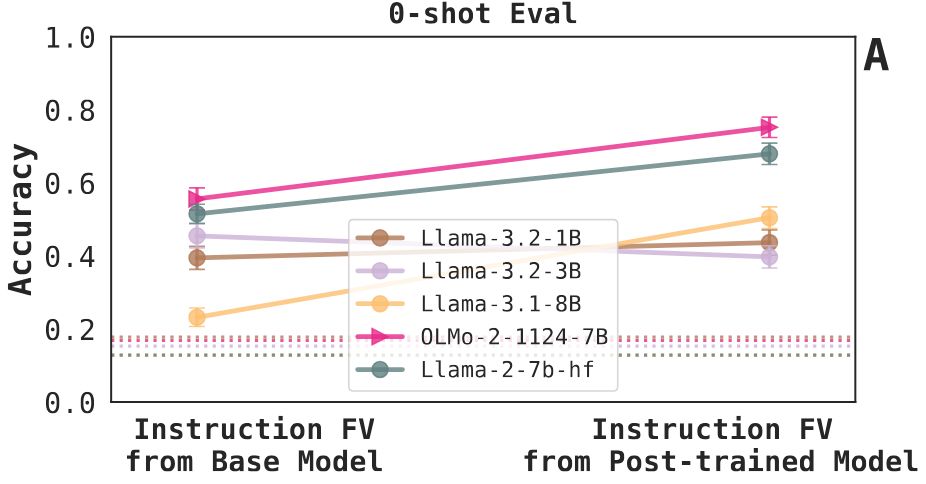
Finding 5: We can steer base models with instruction FVs extracted from their post-trained versions. We didn't expect this to work! It's less effective for the Llama-3.2 models that are distilled and smaller. We're also excited to dig into this and see where we can push it. 11/N
23.05.2025 17:38 — 👍 0 🔁 0 💬 1 📌 0
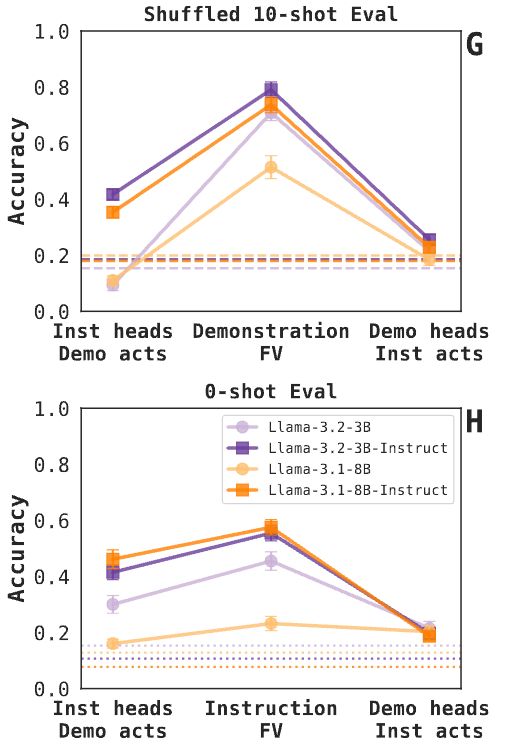
Finding 4: The relationship between demonstrations and instructions is asymmetrical. Especially in post-trained models, the top attention heads for instructions appear peripherally useful for demonstrations, more than the opposite case (see paper for details). 10/N
23.05.2025 17:38 — 👍 0 🔁 0 💬 1 📌 0
We (preliminarily) interpret this as evidence that the effect of post-training is _not_ in adapting the model to represent instructions with the mechanism used for demonstrations, but in developing a mostly complementary mechanism. We're excited to dig into this further. 9/N.
23.05.2025 17:38 — 👍 0 🔁 0 💬 1 📌 0
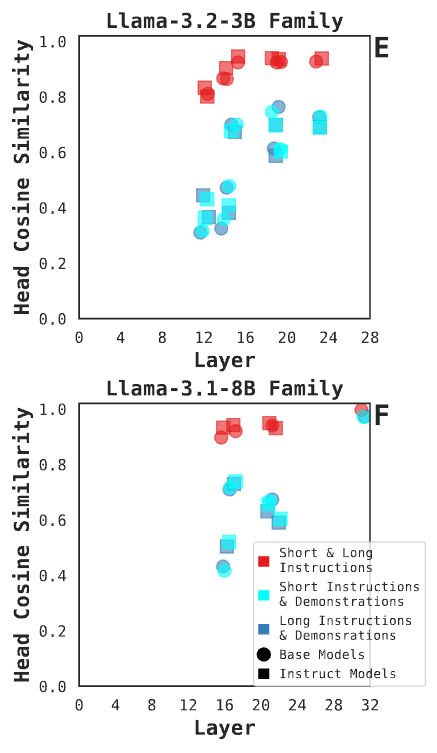
Finding 3 bonus: examining activations in the shared attention heads, we see (a) generally increased similarity with increasing model depth, and (b) no difference in similarity between base and post-trained models (circles and squares). 8/N
23.05.2025 17:38 — 👍 0 🔁 0 💬 1 📌 0
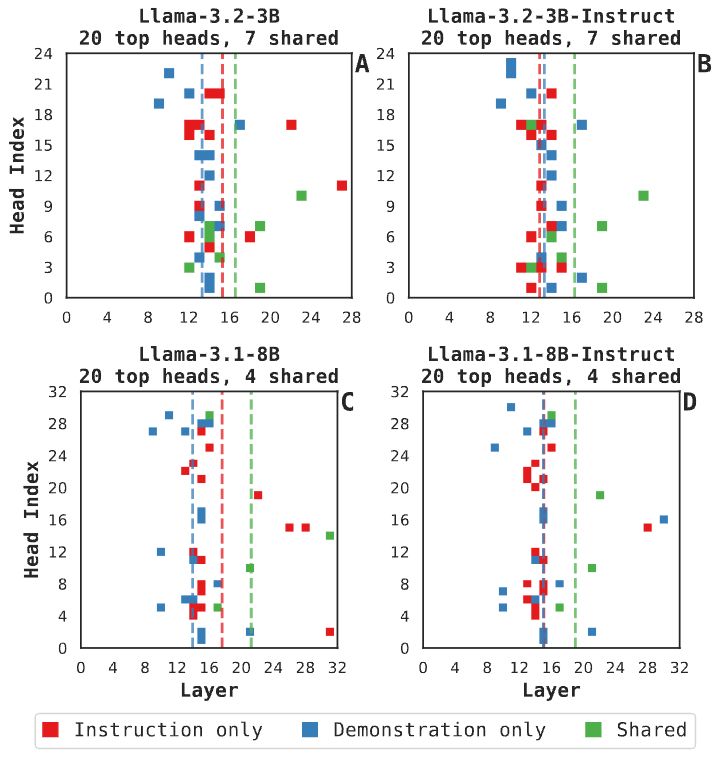
Finding 3: Different attention heads are identified by the FV procedure between demonstrations and instructions => different mechanisms are involved in creating task representations from different prompt forms. We also see consistent base/post-trained model differences. 7/N
23.05.2025 17:38 — 👍 0 🔁 0 💬 1 📌 0
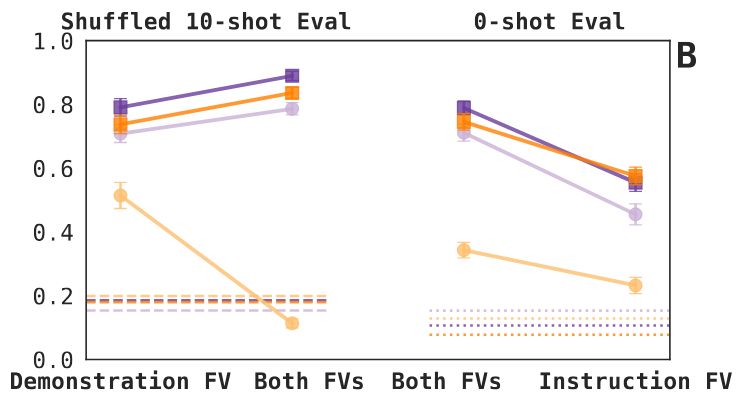
Finding 2: Demonstration and instruction FVs help when applied to a model together (again, with the caveat of the 3.1-8B base model) => they carry (at least some) different information => these different forms elicit non-identical task representations (at least, as FVs). 6/N
23.05.2025 17:38 — 👍 0 🔁 0 💬 1 📌 0
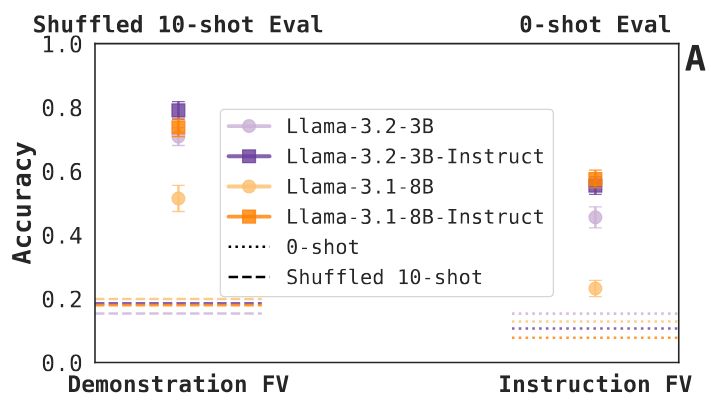
Finding 1: Instruction FVs increase zero-shot task accuracy (even if not as much as demonstration FVs increase accuracy in a shuffled 10-shot evaluation). The 3.1-8B base model trails the rest; we think it has to do with sensitivity to the chosen FV intervention depth. 5/N
23.05.2025 17:38 — 👍 1 🔁 0 💬 1 📌 0

TL;DR: We successfully extend FVs to ICL instruction prompts and extract instruction function vectors that raise zero-shot task accuracy. We offer evidence that they carry different information from demonstration FVs and are represented by mostly different attention heads. 4/N
23.05.2025 17:38 — 👍 1 🔁 0 💬 1 📌 0
Data Science PhD from Drexel CCI
michalmonselise.github.io
Postdoc studying learning and decision-making @ Princeton Neuroscience Institute
https://eleanorholton.github.io/
PhD student @csail.mit.edu 🤖 & 🧠
PhD student @Harvard Psychology: computational cognitive science
Getting my PhD studying, and occasionally engaging in, social interaction!
Postdoc at UC Berkeley, Redwood Center | 🧠🤖 | 🎹 | 🎾 | https://mysterioustune.com/
Cognitive and perceptual psychologist, industrial designer, & electrical engineer. Assistant Professor of Industrial Design at University of Illinois Urbana-Champaign. I make neurally plausible bio-inspired computational process models of visual cognition.
Staff research scientist at Google DeepMind. AI and neuro.
Former physicist, current human.
Find more at www.janexwang.com
PhD candidate - Centre for Cognitive Science at TU Darmstadt,
explanations for AI, sequential decision-making, problem solving
💻 PhD student at UW CS
🤖 Researching human-robot interaction and AI alignment
🌐 https://claireyang.me/
Research scientist at FAIR NY ❤️ LLMs + Information Theory. Previously, PhD at UoAmsterdam, intern at DeepMind + MSRC.
Postdoc at Northeastern and incoming Asst. Prof. at Boston U. Working on NLP, interpretability, causality. Previously: JHU, Meta, AWS
NLP Researcher | CS PhD Candidate @ Technion
A latent space odyssey
gracekind.net
PhD student @ltiatcmu.bsky.social. Working on NLP that centers worker agency. Otherwise: coffee, fly fishing, and keeping peach pits around, for...some reason
https://siree.sh
#NLP Postdoc at Mila - Quebec AI Institute & McGill University
mariusmosbach.com
MIT // researching fairness, equity, & pluralistic alignment in LLMs
previously @ MIT media lab, mila / mcgill
i like language and dogs and plants and ultimate frisbee and baking and sunsets
https://elinorp-d.github.io
ML researcher
https://afedercooper.info
Assistant Professor at Bar-Ilan University
https://yanaiela.github.io/

























