
Where do some of Reinforcement Learning's great thinkers stand today?
Find out! Keynotes of the RL Conference are online:
www.youtube.com/playlist?lis...
Wanting vs liking, Agent factories, Theoretical limit of LLMs, Pluralist value, RL teachers, Knowledge flywheels
(guess who talked about which!)
27.08.2025 12:46 — 👍 76 🔁 23 💬 1 📌 1
On my way to #ICML2025 to present our algorithm that strongly scales with inference compute, in both performance and sample diversity! 🚀
Reach out if you’d like to chat more!
13.07.2025 12:26 — 👍 8 🔁 2 💬 0 📌 0
New side project!
assayer: A simple Python-RQ based tool to automatically monitor and evaluate ML model checkpoints offline during training.
15.06.2025 22:27 — 👍 4 🔁 1 💬 1 📌 0
Research Engineer, Reinforcement Learning
London, UK
Ever thought of joining DeepMind's RL team? We're recruiting for a research engineering role in London:
job-boards.greenhouse.io/deepmind/job...
Please spread the word!
22.05.2025 15:11 — 👍 28 🔁 8 💬 1 📌 1
Accepted to #ICML2025
See you in Vancouver!
02.05.2025 10:35 — 👍 0 🔁 0 💬 0 📌 0
When faced with a challenge (like debugging) it helps to think back to examples of how you've overcome challenges in the past. Same for LLMs!
The method we introduce in this paper is efficient because examples are chosen for their complementarity, leading to much steeper inference-time scaling! 🧪
20.03.2025 10:23 — 👍 19 🔁 5 💬 0 📌 0
This was a really fun collaboration with my brilliant collaborators Hassan Mansoor, Zita Marinho, Masha Samsikova, and @schaul.bsky.social!
17.03.2025 11:16 — 👍 1 🔁 0 💬 0 📌 0
In addition to this, AuPair has been shown to work better across CodeForces difficulty levels and preserve coverage of problem categories from the training data distribution (see paper for more details).
17.03.2025 11:16 — 👍 1 🔁 0 💬 1 📌 0
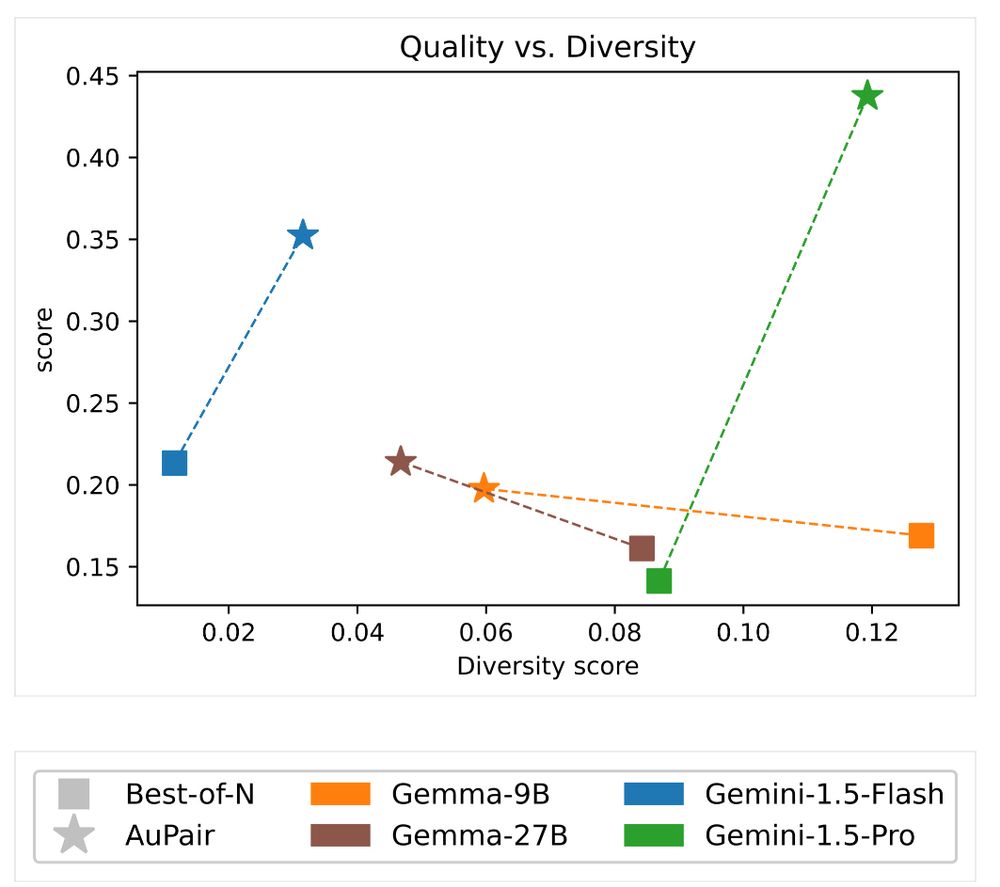
4) the responses produced by the model have high diversity for the more performant models.
17.03.2025 11:16 — 👍 1 🔁 0 💬 1 📌 0
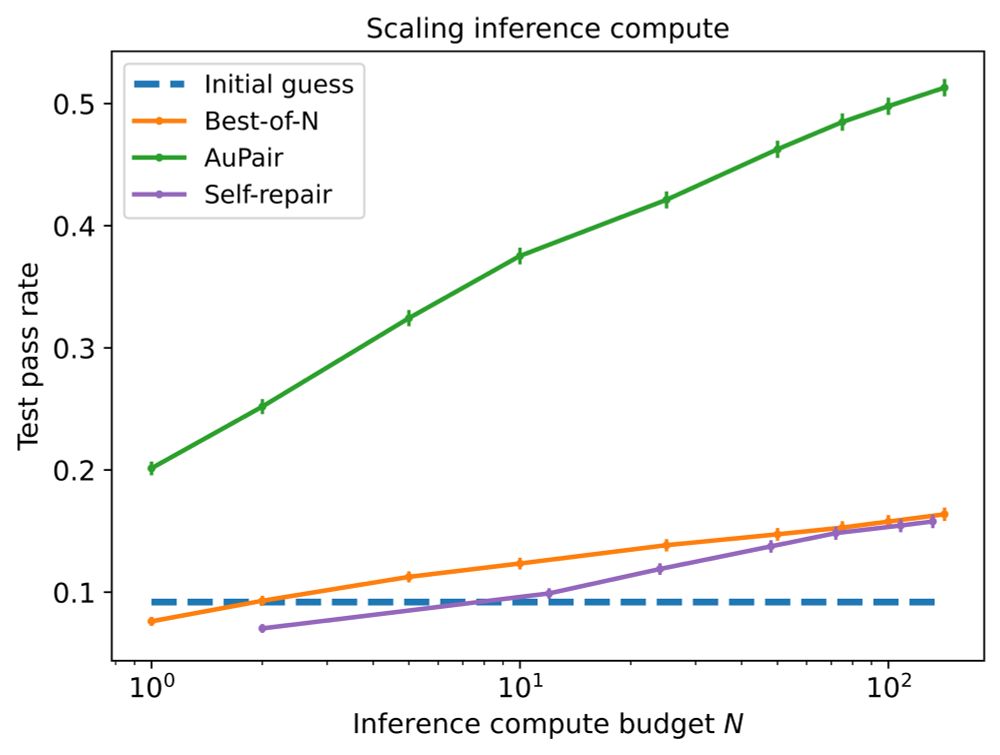
3) our approach exhibits strong scaling with inference-time compute, and even after 100+ LLM calls, we do not see plateauing in the scaling curve;
17.03.2025 11:16 — 👍 1 🔁 0 💬 1 📌 0
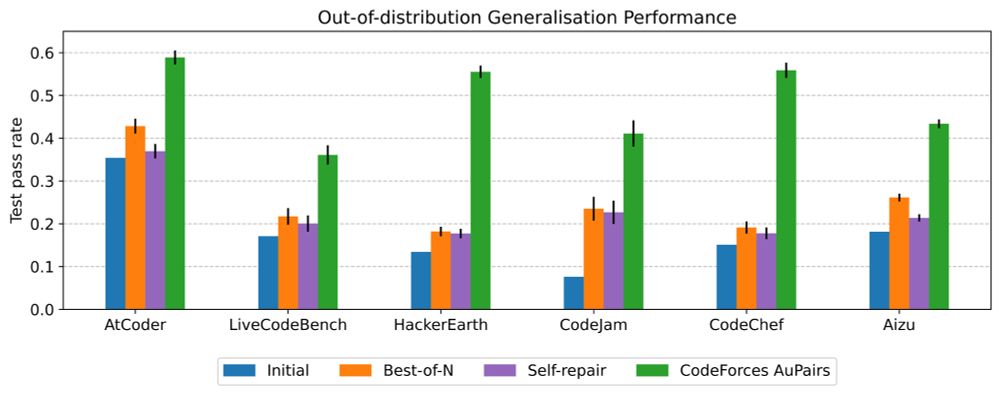
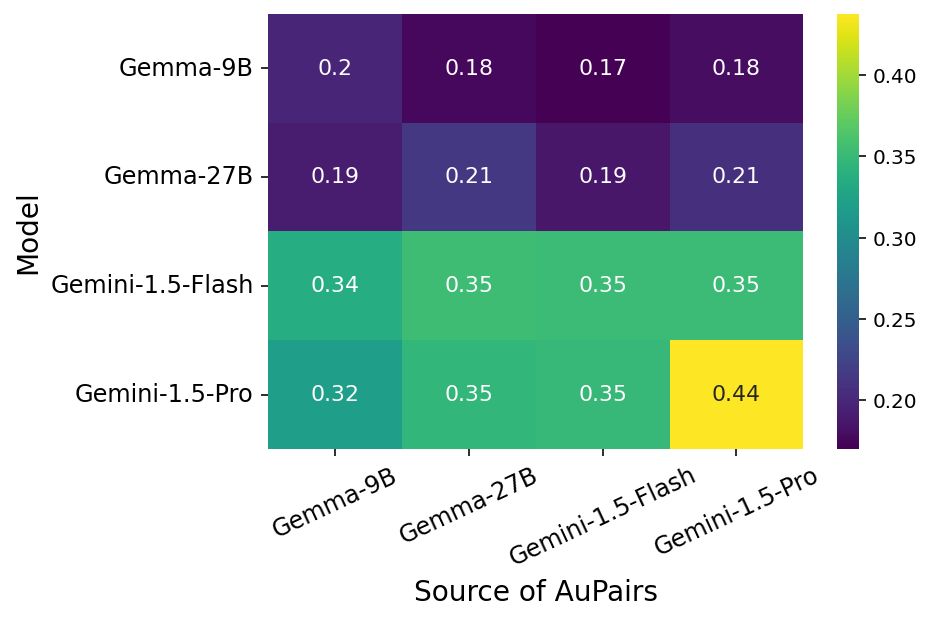
2) we observe strong generalisation across datasets and models, implying that the process of curating these examples can be performed once and the benefits in performance can be reaped multiple times;
17.03.2025 11:16 — 👍 1 🔁 0 💬 1 📌 0
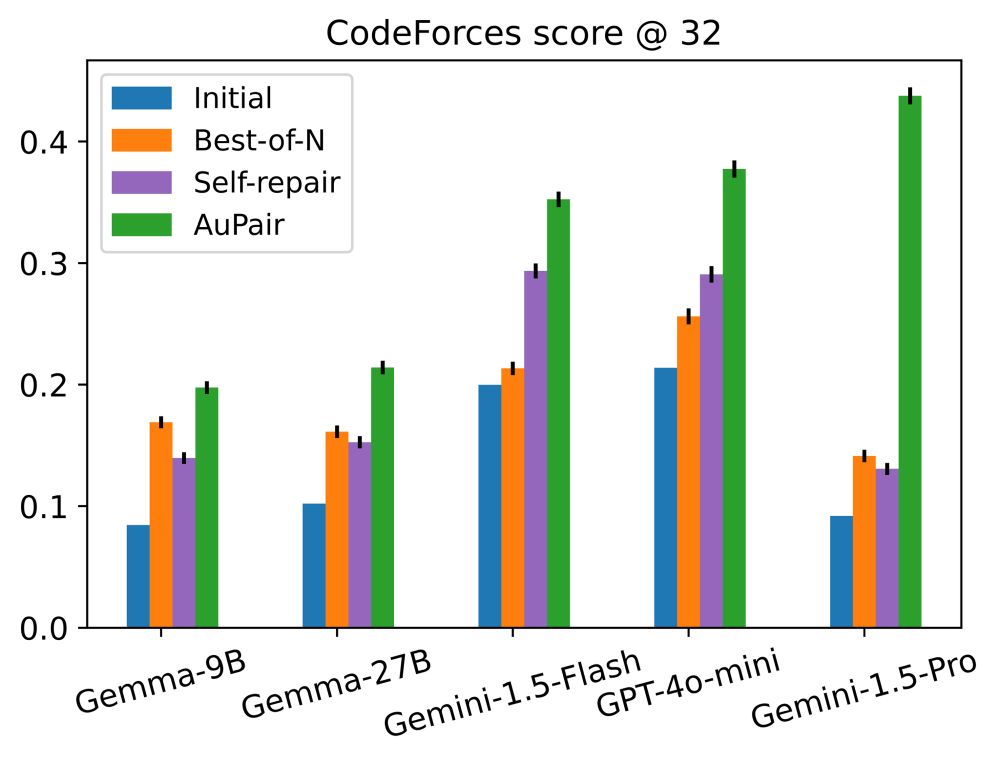
Injecting different examples into the prompt has several benefits: 1) we see significant gains in performance compared to best-of-N and self-repair baselines on multiple model families: Gemini, Gemma, and GPT;
17.03.2025 11:16 — 👍 1 🔁 0 💬 1 📌 0
Fun fact: the title “AuPair” has multiple interpretations: at a higher level, it guides LLMs to better behaviour with a predefined set of examples; it is also a conjunction of Au, the chemical symbol for gold, and pair, i.e. golden pairs!
17.03.2025 11:16 — 👍 1 🔁 0 💬 1 📌 0
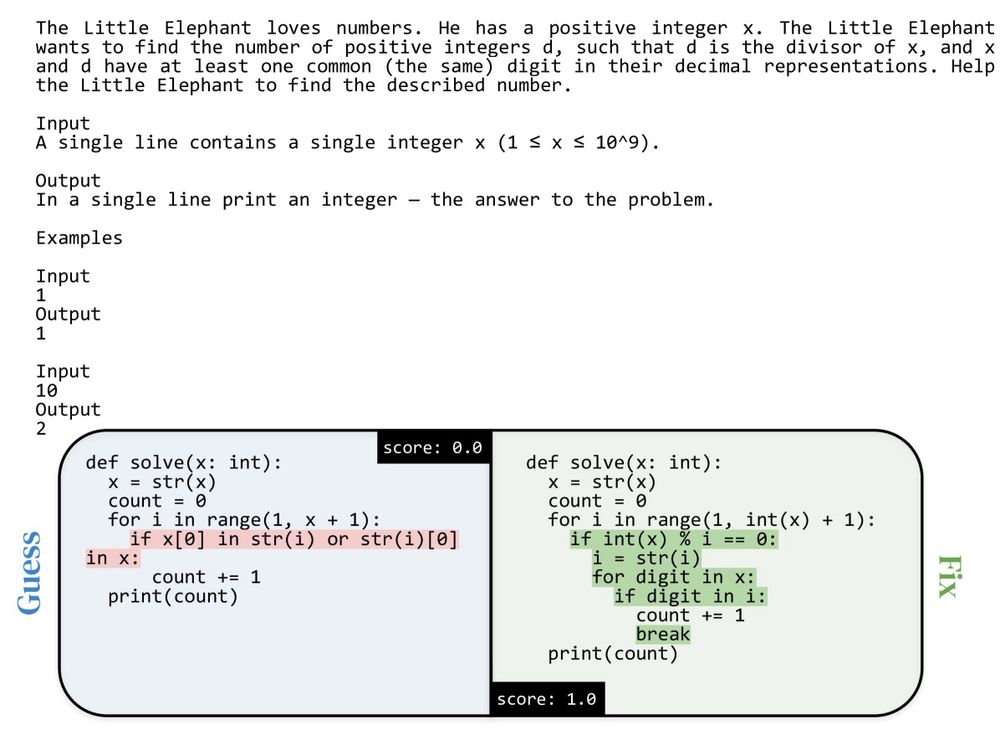
For the coding domain, a golden example pair, or AuPair, contains the problem description, an incorrect guess, and a fix that improves the solution.
17.03.2025 11:16 — 👍 1 🔁 0 💬 1 📌 0
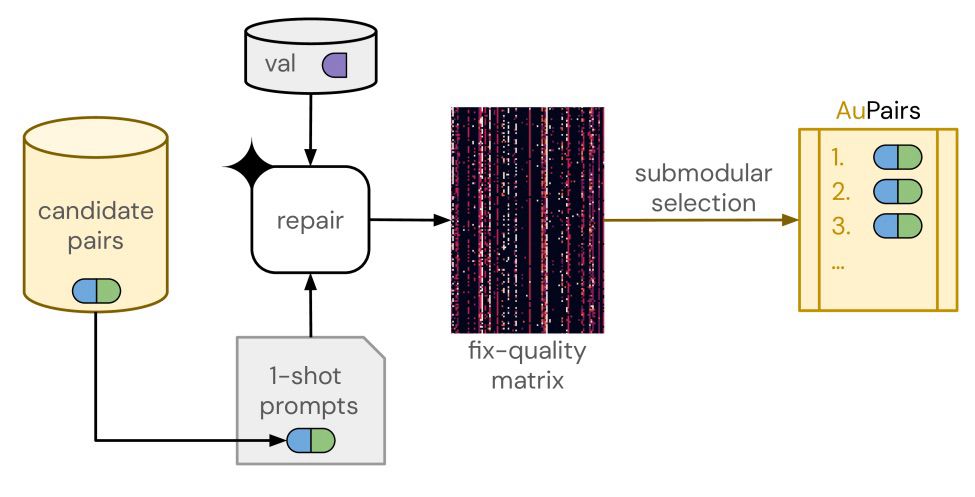
Our submodular approach yields a fixed ordered set of complementary and useful AuPairs. For a budget of N LLM calls, the model is given N different prompts to answer the same question, where each prompt contains a different golden example.
17.03.2025 11:16 — 👍 1 🔁 0 💬 1 📌 0
The key idea underlying our approach is simple: our approach curates a fixed set of golden examples (AuPairs) that are provided as 1-shot in-context examples during inference. We show that using AuPairs significantly improves code repair performance and scales well with inference compute!
17.03.2025 11:16 — 👍 1 🔁 0 💬 1 📌 0
😃😃😃
23.11.2024 12:05 — 👍 1 🔁 0 💬 0 📌 0
#OpenEndedness. Staff Research Engineer at GoogleDeepMind, Visiting Fellow at LSE, Advisor at Cooperative AI Foundation, Choral Director at Godwine Choir. www.edwardhughes.io
AI researcher at Google DeepMind -- views on here are my own.
Interested in cognition & AI, consciousness, ethics, figuring out the future.
ML & NLP at Google DeepMind
Chief Models Officer @ Stealth Startup; Inria & MVA - Ex: Llama @AIatMeta & Gemini and BYOL @GoogleDeepMind
Professor at UT Nuremberg, Germany
I’m 🇫🇷 and I work on RL and lifelong learning. Mostly posting on ML related topics.
Robotics Researcher at Google DeepMind
Senior Research Director at Google DeepMind in our San Francisco office. I created Magenta (magenta.withgoogle.com) and sometimes find time to be a musician.
⛷️ ML Theorist carving equations and mountain trails | 🚴♂️ Biker, Climber, Adventurer | 🧠 Reinforcement Learning: Always seeking higher peaks, steeper walls and better policies.
https://ualberta.ca/~szepesva
#RobotLearning Professor (#MachineLearning #Robotics) at @ias-tudarmstadt.bsky.social of
@tuda.bsky.social @dfki.bsky.social @hessianai.bsky.social
Research Engineer at Google DeepMind.
Interests in game theory, reinforcement learning, and deep learning.
Website: https://www.lukemarris.info/
Google Scholar: https://scholar.google.com/citations?user=dvTeSX4AAAAJ
Professor, Santa Fe Institute. Research on AI, cognitive science, and complex systems.
Website: https://melaniemitchell.me
Substack: https://aiguide.substack.com/
AI at Google DeepMind. Previously: Orbital Insight, A9/Amazon.
adamwkraft.github.io
ML. Biology. Research Engineer at Google DeepMind.
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
Reinforcement learning researcher, dabbled in robotics, and generative techniques that were later made out of date by diffusion. Currently at Sony AI, working on game AI
Teaching Faculty @ Princeton University | CMU, MIT alum | reinforcement learning, AI ethics, equity and justice, baking | ADHD 💖💜💙






















