

Good news everyone!
I’ll be presenting the paper I did with Marco and Iuri "Prediction Hubs are Context-Informed Frequent tokens in LLMs" at the ELLIS UnConference on December 2nd in Copenhagen. arxiv.org/abs/2502.10201
Good news everyone!
I’ll be presenting the paper I did with Marco and Iuri "Prediction Hubs are Context-Informed Frequent tokens in LLMs" at the ELLIS UnConference on December 2nd in Copenhagen. arxiv.org/abs/2502.10201

Do you use a pronoun more often when the entity you’re talking about is more predictable?
Previous work offers diverging answers so we conducted a meta-analysis, combining data from 20 studies across 8 different languages.
Now out in Language: muse.jhu.edu/article/969615

First paper is out! Had so much fun presenting it in Marseille last July 🇨🇵
We explore how transformers handle compositionality by exploring the representations of the idiomatic and literal meaning of the same noun phrase (e.g. "silver spoon").
aclanthology.org/2025.jeptaln...

Sigmoid function. Non-linearities in neural network allow it to behave in distributed and near-symbolic fashions.
New paper! 🚨 I argue that LLMs represent a synthesis between distributed and symbolic approaches to language, because, when exposed to language, they develop highly symbolic representations and processing mechanisms in addition to distributed ones.
arxiv.org/abs/2502.11856
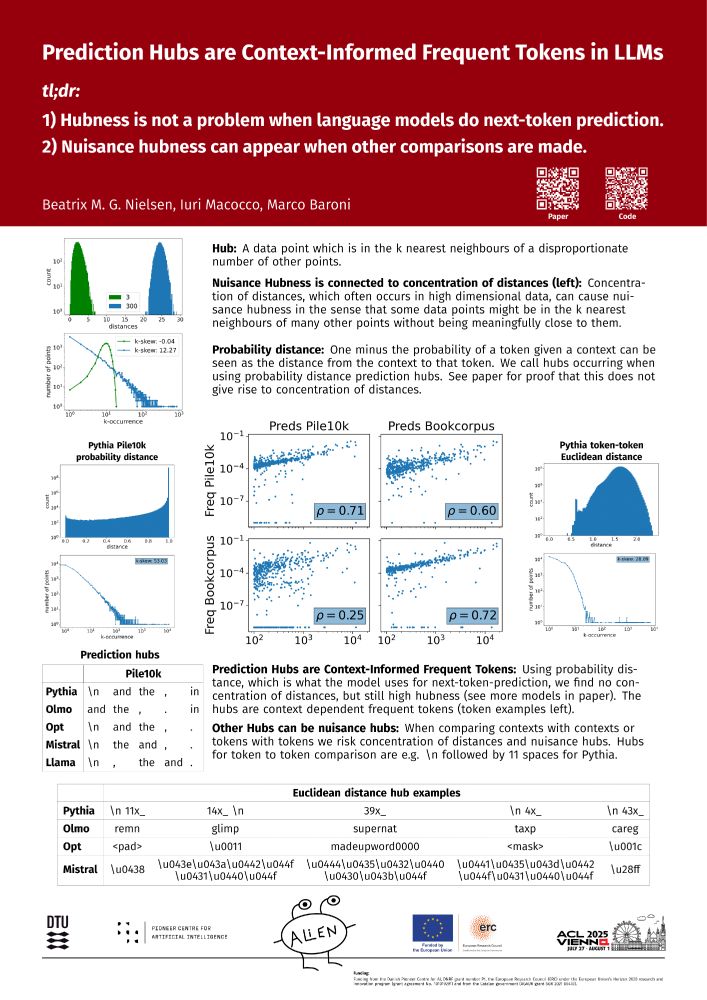
Our paper "Prediction Hubs are Context-Informed Frequent Tokens in LLMs" has been accepted at ACL 2025!
Main points:
1. Hubness is not a problem when language models do next-token prediction.
2. Nuisance hubness can appear when other comparisons are made.

The @interspeech.bsky.social early registration deadline is coming up in a few days!
Want to learn how to analyze the inner workings of speech processing models? 🔍 Check out the programme for our tutorial:
interpretingdl.github.io/speech-inter... & sign up through the conference registration form!
Last day to sign up for the COLT Symposium!
Register: tinyurl.com/colt-register
📢 𝗟𝗼𝗰𝗮𝘁𝗶𝗼𝗻 𝗰𝗵𝗮𝗻𝗴𝗲📢
June 2nd, 14:30 - 19:00
UPF Campus de la Ciutadella
Room 40.101
maps.app.goo.gl/1216LJRsWmTE...
⭐ Registration open til May 27th! ⭐
Website: www.upf.edu/web/colt/sym...
June 2nd, UPF
𝗦𝗽𝗲𝗮𝗸𝗲𝗿 𝗹𝗶𝗻𝗲𝘂𝗽:
Arianna Bisazza (language acquisition with NNs)
Naomi Saphra (emergence in LLM training dynamics)
Jean-Rémi King (TBD)
Louise McNally (pitfalls of contextual/formal accounts of semantics)

🧵 Excited to share our paper "Unique Hard Attention: A Tale of Two Sides" with Selim, Jiaoda, and Ryan, where we show that the way transformers break ties in attention scores has profound implications on their expressivity! And it got accepted to ACL! :)
The paper: arxiv.org/abs/2503.14615
Announcing the COLT Symposium on June 2nd!
𝗘𝗺𝗲𝗿𝗴𝗲𝗻𝘁 𝗳𝗲𝗮𝘁𝘂𝗿𝗲𝘀 𝗼𝗳 𝗹𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗶𝗻 𝗺𝗶𝗻𝗱𝘀 𝗮𝗻𝗱 𝗺𝗮𝗰𝗵𝗶𝗻𝗲𝘀
What properties of language are emerging from work in experimental and theoretical linguistics, neuroscience & LLM interpretability?
Info: tinyurl.com/colt-site
Register: tinyurl.com/colt-register
🧵1/3
🌍📣🥳
I could not be more excited for this to be out!
With a fully automated pipeline based on Universal Dependencies, 43 non-Indoeuropean languages, and the best LLMs only scoring 90.2%, I hope this will be a challenging and interesting benchmark for multilingual NLP.
Go test your language models!

NYU canceled an invited talk by the former president of Doctors Without Borders, out of fear her talk would be accused by the government of being both anti-Trump and antisemitic: ici.radio-canada.ca/nouvelle/215...
28.03.2025 04:12 — 👍 411 🔁 224 💬 14 📌 69
new pre-print: LLMs as a synthesis between symbolic and continuous approaches to language arxiv.org/abs/2502.11856
24.02.2025 16:29 — 👍 15 🔁 2 💬 0 📌 2
The project I did with Marco Baroni and Iuri Macocco while I was in Barcelona is now on Arxiv: arxiv.org/abs/2502.10201 🎉
TLDR below 👇
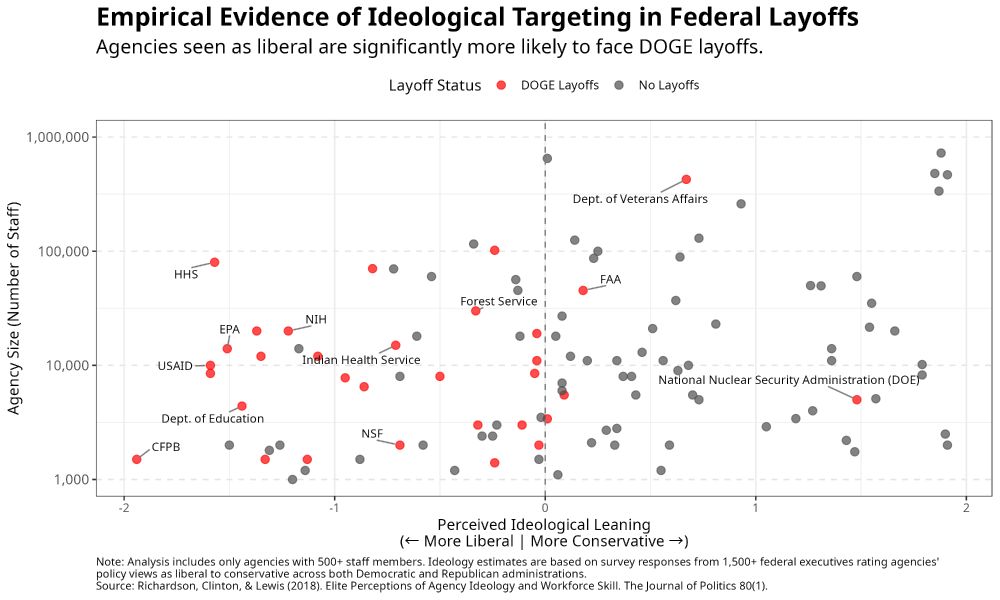
Scatterplot titled “Empirical Evidence of Ideological Targeting in Federal Layoffs: Agencies seen as liberal are significantly more likely to face DOGE layoffs.” • The x-axis represents Perceived Ideological Leaning of federal agencies, ranging from -2 (Most Liberal) to +2 (Most Conservative), based on survey responses from over 1,500 federal executives. • The y-axis shows Agency Size (Number of Staff) on a logarithmic scale from 1,000 to 1,000,000. Each point represents a federal agency: • Red dots indicate agencies that experienced DOGE layoffs. • Gray dots indicate agencies with no layoffs. Key Observations: • Liberal-leaning agencies (left side of the plot) are disproportionately represented among red dots, indicating higher layoff rates. • Notable targeted agencies include: • HHS (Health & Human Services) • EPA (Environmental Protection Agency) • NIH (National Institutes of Health) • CFPB (Consumer Financial Protection Bureau) • Dept. of Education • USAID (U.S. Agency for International Development) • The National Nuclear Security Administration (DOE), despite its conservative leaning (+1 on the scale), is an exception among targeted agencies. • A notable outlier: the Department of Veterans Affairs (moderately conservative) also faced layoffs despite its size. Takeaway: The figure visually demonstrates that DOGE layoffs disproportionately targeted liberal-leaning agencies, supporting claims of ideological bias. The pattern reveals that layoffs were not driven by agency size or budget alone but were strongly associated with perceived ideology. Source: Richardson, Clinton, & Lewis (2018). Elite Perceptions of Agency Ideology and Workforce Skill. The Journal of Politics, 80(1).
The DOGE firings have nothing to do with “efficiency” or “cutting waste.” They’re a direct push to weaken federal agencies perceived as liberal. This was evident from the start, and now the data confirms it: targeted agencies overwhelmingly those seen as more left-leaning. 🧵⬇️
20.02.2025 02:18 — 👍 10678 🔁 4785 💬 252 📌 397
list of banned keywords
🚨BREAKING. From a program officer at the National Science Foundation, a list of keywords that can cause a grant to be pulled. I will be sharing screenshots of these keywords along with a decision tree. Please share widely. This is a crisis for academic freedom & science.
04.02.2025 01:26 — 👍 27848 🔁 15746 💬 1272 📌 3657
arxiv.org/abs/2405.15471
with Diego Doimo, Corentin Kervadec, Iuri Macocco, Jade Yu, Alessandro Laio, and Marco Baroni.
6/6
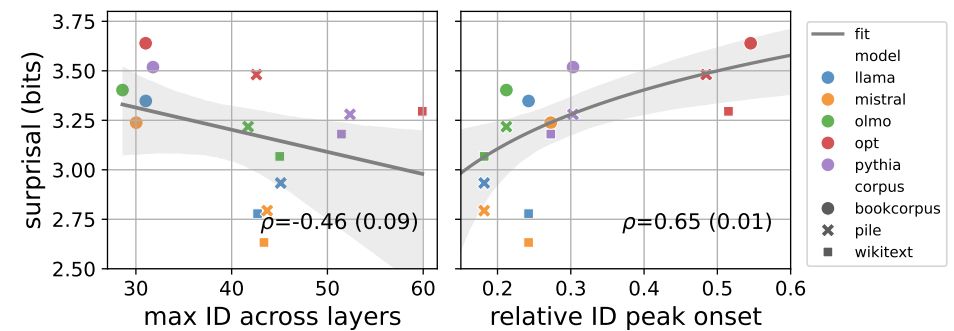
3️⃣LLMs that are better at next-token prediction have higher, earlier ID peaks.
5/6
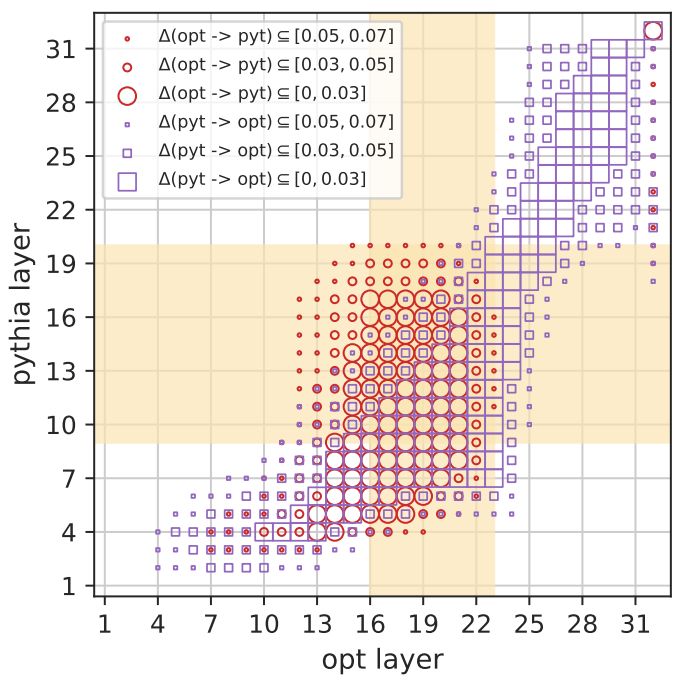
2️⃣ The ID peak (beige) is where different LLMs are most similar (big shapes).
All LLMs share this high-dimensional phase of linguistic abstraction, but...
4/6
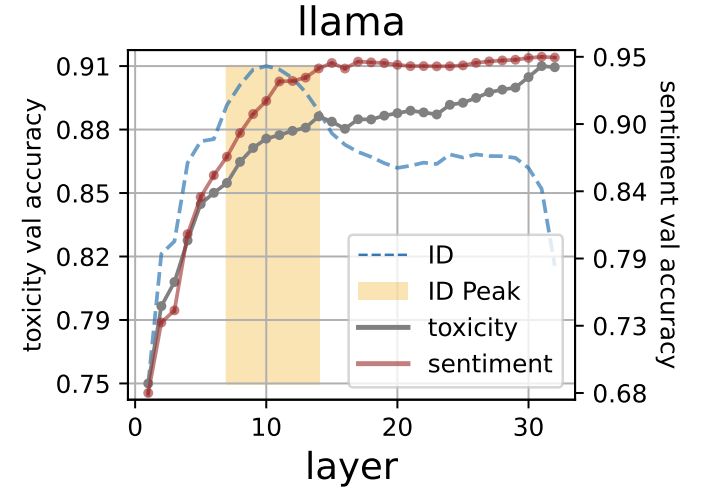
... the ID peak marks where syntactic, semantic, and abstract linguistic features like toxicity and sentiment are first decodable.
⭐use these layers for downstream transfer!
(e.g., for brain encoding models, see arxiv.org/abs/2409.05771)
3/6
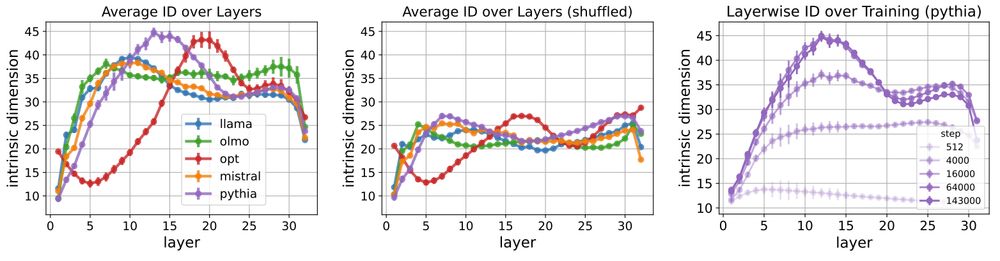
1️⃣ The ID peak is linguistically relevant.
- it collapses on shuffled text (destroying syntactic/semantic structure)
- it grows over the course of training...
2/6
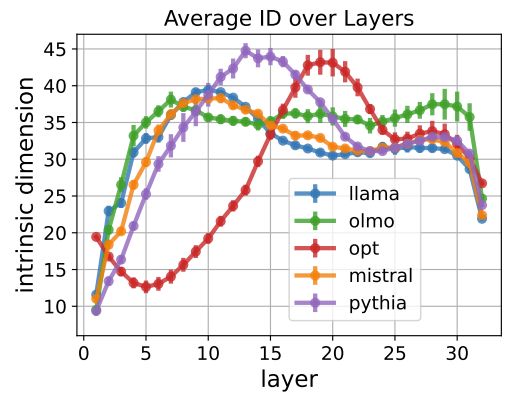
Here's our work accepted to #ICLR2025!
We look at how intrinsic dimension evolves over LLM layers, spotting a universal high-dimensional phase.
This ID peak is where:
- linguistic features are built
- different LLMs are most similar,
with implications for task transfer
🧵 1/6

I think some people hear “grants” and think that without them, scientists and government workers just have less stuff to play with at work. But grants fund salaries for students, academics, researchers, and people who work in all areas of public service.
“Pausing” grants means people don’t eat.

🔊New EMNLP paper from Eleonora Gualdoni & @gboleda.bsky.social !
Why do objects have many names?
Human lexicons contain different words that speakers can use to refer to the same object, e.g., purple or magenta for the same color.
We investigate using tools from efficient coding...🧵
1/3
⚡Postdoc opportunity w/ COLT
Beatriu de Pinós contract, 3 yrs, competitive call by Catalan government.
Apply with a PI (Marco Gemma or Thomas)
Reqs: min 2y postdoc experience outside Spain, not having lived in Spain for >12 months in the last 3y.
Application ~December-February (exact dates TBD)
Hello🌍! We're a computational linguistics group in Barcelona headed by Gemma Boleda, Marco Baroni & Thomas Brochhagen
We do psycholinguistics, cogsci, language evolution & NLP, with diverse backgrounds in philosophy, formal linguistics, CS & physics
Get in touch for postdoc, PhD & MS openings!

My lab has been working on comparing neural representations for the past few years - methods like RSA, CKA, CCA, Procrustes distance
We are often asked: What do these things tell us about the system's function? How do they relate to decoding?
Our new paper has some answers arxiv.org/abs/2411.08197