As a deaf person with a deaf kid, I'm the first to admit IDEA isn't perfect. I fight people's (often willful) misinterpretations of the Least Restrictive Environment every day. Just gave a lecture at BU about how change is needed. Deleting all legal oversight in the middle of the night isn't it.
13.10.2025 12:23 — 👍 183 🔁 37 💬 4 📌 2

Measuring the semantic priming effect across many languages - Nature Human Behaviour
In this Stage 2 Registered Report, Buchanan et al. show evidence confirming the phenomenon of semantic priming across speakers of 19 diverse languages.
@clauslamm.bsky.social & I contributed to a global study that analyzed 21 million trials across 30 languages, revealing semantic priming [SP] as a robust cognitive mechanism across cultures and writing systems.
Lead by @aggieerin.bsky.social and @slewis5920.bsky.social
doi.org/10.1038/s415...
25.09.2025 18:25 — 👍 9 🔁 4 💬 1 📌 0
as in: don't send them research statements / CVs, just start showing up at faculty meetings?
21.09.2025 15:11 — 👍 2 🔁 0 💬 0 📌 0
Proposal for how to fix family wise error rates.
For every uncorrected p value you must add an extra letter to the claim.
“Eating chocolate maaaaaaaaay be associated with lower rates of stroke”
16.09.2025 18:55 — 👍 177 🔁 50 💬 0 📌 1
At #SNL2025? Go check out this poster with @zedsehyr.bsky.social
12.09.2025 15:42 — 👍 5 🔁 1 💬 0 📌 0
psych departments post a faculty job that has nothing to do with AI challenge
10.09.2025 11:02 — 👍 120 🔁 16 💬 8 📌 4
Bicycles Deliver the Freedom that Auto Ads Promise.
10.09.2025 10:43 — 👍 660 🔁 76 💬 15 📌 11

ggplot2 4.0.0
A new major version of ggplot2 has been released on CRAN. Find out what is new here.
I am beyond excited to announce that ggplot2 4.0.0 has just landed on CRAN.
It's not every day we have a new major #ggplot2 release but it is a fitting 18 year birthday present for the package.
Get an overview of the release in this blog post and be on the lookout for more in-depth posts #rstats
11.09.2025 11:20 — 👍 847 🔁 282 💬 9 📌 51
lil blogpost ab a cool paper led by the amazing @erinecampbell.bsky.social thnx to NSF. also features a coda ab the very active threat to science funding we’re facing (cc @standupforscience.bsky.social) & a ht to @sciencehomecoming.bsky.social’s good work. thnx @infantstudies.bsky.social!
19.08.2025 18:03 — 👍 6 🔁 5 💬 0 📌 1
Thanks for putting this together! May I join?
31.07.2025 19:38 — 👍 1 🔁 0 💬 0 📌 0

Data collection is underway!
We're using mobile eye tracking to study action comprehension in dogs. Django is helping us understand how dogs see and interpret our actions — more coming soon! 🐶👁️ #Science #DogResearch #CognitiveScience
Thanks @asab.org for funding this project!
14.07.2025 09:15 — 👍 53 🔁 7 💬 2 📌 1


I was finally able to make these visualizations of what what "light", "dark" and other modifiers do to colors jofrhwld.github.io/blog/posts/2...
14.07.2025 18:19 — 👍 24 🔁 10 💬 2 📌 0
ooooh, can you share the % that end up being real / still-valid addresses?
14.07.2025 01:55 — 👍 0 🔁 0 💬 1 📌 0
NASA is more than rockets and moonwalks. NASA is behind much of our everyday technology. From space discovery, to Air Jordans, to CAT scans, NASA has played a role. We get it all on less than a penny of every federal dollar. Now their science may be gutted by 50%.
#NASADidThat
10.07.2025 22:39 — 👍 8086 🔁 2632 💬 260 📌 184

Jenna Norton and Naomi Caselli in front of Naomi’s poster at the science fair for canceled grants.
At the Science Fair for canceled grants, I had the privilege of speaking with @naomicaselli.bsky.social. Her team (which includes deaf researchers) were making breakthroughs to better identify & address language deprivation — when the Trump administration terminated their grant.
10.07.2025 04:31 — 👍 46 🔁 19 💬 1 📌 1
Okay y’all, gather round for a chat. It’s been a roller coaster, and I thought I’d share what we’ve learned. 🧵 (1/16)
bsky.app/profile/luck...
10.07.2025 15:59 — 👍 43 🔁 25 💬 1 📌 2

BTSCON 2025 is now seeking submission proposals for their annual conference. All session submissions are due on July 31st. You can submit on the website https://bigteamscienceconference.github.io/submissions/. We are also excited to say that registration is also now live!
BTSCON 2025 is now seeking submission proposals for their annual conference. All session submissions are due on July 31st. You can submit on the website https://bigteamscienceconference.github.io/submissions/. We are also excited to say that registration is also now live!
Session Submission and registration is now open for BTSCON2025!
bigteamscienceconference.github.io/submissions/
@abrir.bsky.social @psysciacc.bsky.social @manybabies.org
07.07.2025 22:55 — 👍 13 🔁 20 💬 1 📌 2
screenshot of our public handbook
every year my lab does a re-read + edit of our Handbook, a documentation resource for how we do science
this year we also updated our Public Handbook, an open-access version for folks wanting to improve their own docs
it's at handbook-public.themusiclab.org and available for noncommercial re-use
23.06.2025 01:33 — 👍 132 🔁 27 💬 4 📌 1
Exciting news - three years after visiting @amymlieberman.bsky.social in Boston for 6 wonderful weeks, our project on joint attention and sign familiarity in ASL has been published!
10.06.2025 20:02 — 👍 9 🔁 2 💬 1 📌 1
its amazing how chatgpt knows everything about subjects I know nothing about, but is wrong like 40% of the time in things im an expert on. not going to think about this any further
08.03.2025 00:13 — 👍 12451 🔁 3121 💬 88 📌 109
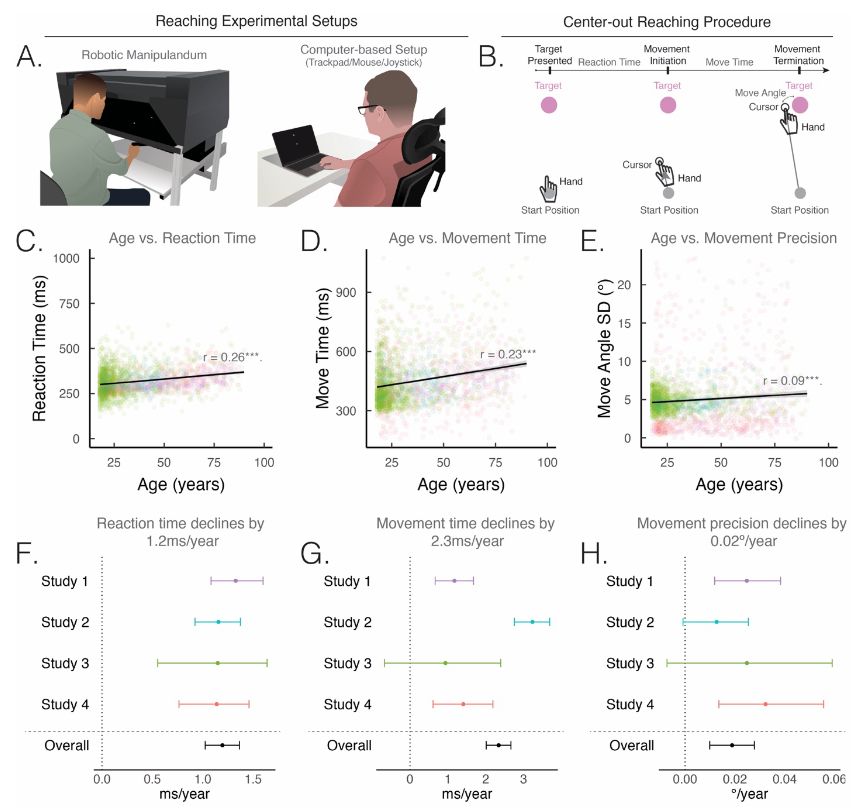
As we age, we move slower and less precisely—but how much, exactly?
We analyzed one of the largest datasets on motor control to date—2,185 adults performing a reaching task.
Findings
• Reaction time: –1.2 ms/year
• Movement time: –2.3 ms/year
• Precision: –0.02°/year
tinyurl.com/f9v66jut
1/2
08.05.2025 00:33 — 👍 21 🔁 6 💬 1 📌 1
those of us staring down the @bucld.bsky.social #BUCLD50 deadline feel seen.
19.05.2025 21:08 — 👍 4 🔁 1 💬 0 📌 0
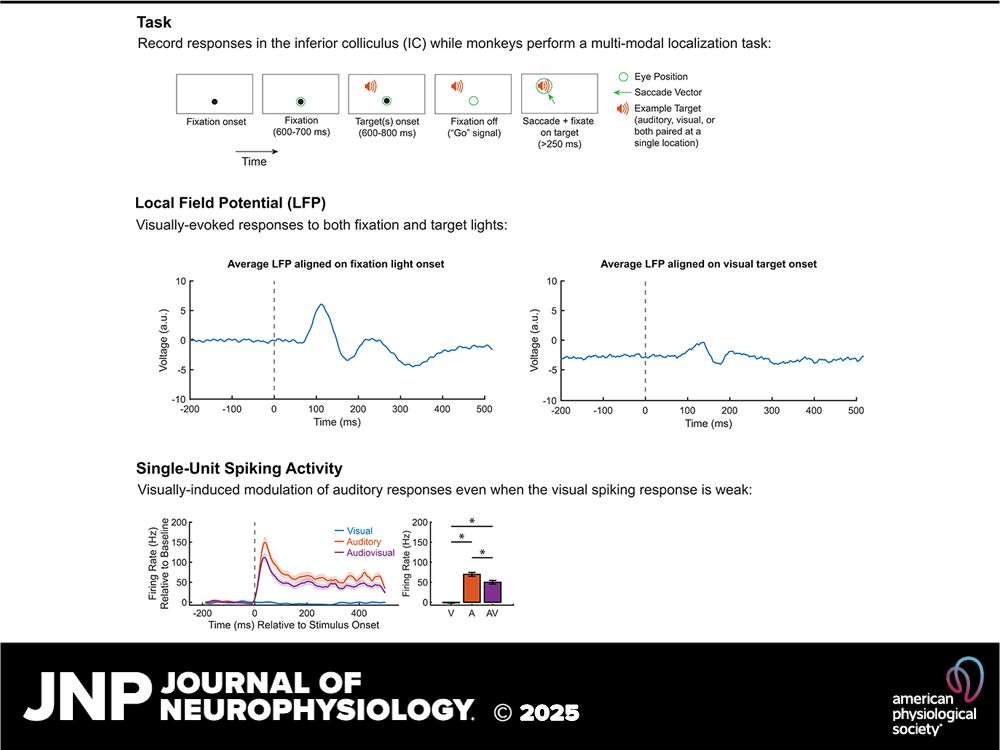
Graphical abstract from the Journal of Neurophysiology with 3 panels. The first panel is titled "Task" with the text: "Record responses in the inferior colliculus (IC) while monkeys perform a multi-modal localization task." A diagram depicts a behavioral task requiring a subject to fixate their eyes on a central light, wait for a target (auditory, visual, or both at a single location) to appear, and then move their eyes to the location of the target. The second panel is titled "Local Field Potential (LFP)" with the text: "Visually-evoked responses to both fixation and target lights." Two figures show the average local field potential (LFP) from multiple recording sites over time during a trial, showing a response that deviates from the pre-stimulus baseline in response to the fixation light (left figure) and visual targets (right figure). Finally, the third panel is titled "Single-Unit Spiking Activity" with the text: "Visually-induced modulation of auditory responses even when the visual spiking response is weak." Two figures follow. The first figure is a peri-stimulus time histogram (PSTH) from one neuron, showing the response to a visual, auditory, and audiovisual target over time. The second figure is a bar plot quantifying the first figure, showing that the audiovisual response has a lower firing rate than the auditory response, despite the visual response for this neuron being near zero. Below the 3 main panels of the graphical abstract is a footer with the logo of the American Physiological Society and the Journal of Neurophysiology.
I'm happy to share a new paper from my PhD research!
Exciting work about how visual info helps us process sound, and an example of federal funding that benefits all of us - from your health to community health.
doi.org/10.1152/jn.0...
With @jmgrohneuro.bsky.social & Jesse Herche
Thread: 🧵👇
1/10
14.05.2025 20:13 — 👍 18 🔁 7 💬 2 📌 1

a picture of a bald man with the words " i would very much like to hear your thoughts "
Alt: Captain Picard of Star Trek in uniform seriously says to someone off camera "I would very much like to hear your thoughts" (which appears as white text on the bottom)
Daz @drdazzy.bsky.social and I are current board members of SLLS (slls.eu/board/) and are seeking feedback about TISLR conferences
Anyone who's interested in signed languages can respond even if you haven't been to TISLR. Please share widely!
Thank you for your time!
gu.live/RWCkP
13.05.2025 18:52 — 👍 3 🔁 6 💬 0 📌 0
Maybe blind children are doing something different with the language input 🤷♀️🤷♀️🤷♀️ (underspecified, I know)
Maybe language input supports language development regardless of vision status, but without vision, it takes a little longer to derive meaning from language input.
10/N
12.05.2025 18:34 — 👍 5 🔁 0 💬 1 📌 0
Back to the present paper!
My interpretation?
The input doesn’t look *that* different.
I don’t feel compelled by the explanation that parents of blind children talk to them in some special magic way that allows them to overcome initial language delays.
So then what?
9/N
12.05.2025 18:34 — 👍 2 🔁 0 💬 1 📌 0
Links to those two papers ⬇️
🐠 Deep dive into vocabulary in blind toddlers: onlinelibrary.wiley.com/doi/abs/10.1...
👻 Production of "imperceptible" words (in my own biased opinion, this one is a banger)
direct.mit.edu/opmi/article...
12.05.2025 18:34 — 👍 1 🔁 0 💬 1 📌 0
Author TRUE BIZ + GIRL AT WAR
🧏🏻 deafie | they/she/👉🏼 |📍Philly
https://buttondown.com/signs+wonders
https://linktr.ee/Novic
Postdoc @univie.ac.at / scanunit.bsky.social, collab 🇦🇹 & 🇧🇪
Lecturer @IESabroad
Ass. Dir. Data & Methods @psysciacc.bsky.social
Programm committee @improvingpsych.bsky.social
NO 2 WAR!
https://www.pronizius.com
Echoes In Motion, formerly Dangerous Signs, is a Deaf theater group blending ASL, dance, mime, and storytelling, awarded for diversity in the arts
Linguist at the University of Bergen 🇳🇴
#SignLanguages, #linguistics, #RStats & #dataviz
JMU (BS) & Vanderbilt (MS-SLP) alum, PhD candidate @ Vanderbilt Hearing & Speech!
Passionate about language development, caregiver-infant interaction, & autism.🧠🗣
Hizkuntzalaria/Linguist/Lingüista
Language & Cognition
Investigo, enseño y divulgo sobre el maravilloso mundo del lenguaje y las lenguas
#Psycholinguistics #SemanticTypology #CognitiveLinguistics #Ideophone #Senses #MinorityLanguages
Distinguished Professor, Departments of Cognitive Sciences & Language Science, University of California Irvine. Author, Wired for Words: The Neural Architecture of Language (MIT Press, forthcoming).
Non-profit Open Access journal the Neurobiology of Language published by MIT Press and Society for the Neurobiology of Language
https://direct.mit.edu/nol
Professor at Boston University | Speech Scientist | Voxologist | Academic Mama | See lab happenings @stepplab
Professor at San Diego State University; sign languages, neuroscience, reading, gesture, all things linguistic
Word nerd @ Rice in Texas but currently at the National Science Foundation. Cogsci of written language, aphasia, disability.
Definitely not speaking on behalf of the NSF! Only my views here…
Educational Neurosci. at Gallaudet. Brains, actions, language, emerging tech. ASL in XR. 🪴
I study language using tools from cognitive science and neuroscience. I also like snuggles.
Psycholinguist @UCDavis. Made in Portugal, raised in Canada, living in California. Author of "Psycholinguistics: A Very Short Introduction" from Oxford University Press, coming out January 23, 2025.
Phonetician at Oxford University. Very into stops, Danish/Germanic, Rstats. Also have other hobbies. https://rpuggaardrode.github.io
Postdoc at @theneuro.bsky.social | semantic knowledge, socialness & cognitive control 🧠 💭🫂 | OHBM Open Science SIG Treasurer | McGill Postdoc Assoc. Chair
NSERC Postdoctoral Associate at @westernu.ca
🧠 Cognitive scientist | 🔤 language | 🤲 embodiment | 👁️ mental imagery
Fueled by coffee, curiosity, and two very good dogs 🐾
Likely overthinking something (on purpose)
PhD candidate at Aix-Marseille Université (LIS/ILCB) with Abdellah Fourtassi & Benoit Favre.
CogSci + NLP
Trying to understand children's conversational skill development
Neuroscience PhD. Vision science: dark adaptation, colour vision, glare, mathematical modelling. Data analysis/viz, CV and ML. Fixing an old house and two old cars.
Dad, husband, carer, ally. BLM and LGBTQIA+ he/him ♾️🇮🇪🇮🇹🏳️🌈🇵🇸🐓🐶
Neuroscientist supporting #OpenScience @HHMI.org
Connecting science & society through #SciPol, #SciComm, & community building for a more equitable & informed future
Past:
📢 Comms @ National SciPol Network
🧠 Ph.D. @DukeBrain.bsky.social
🧬 B.S. x2 @CMU.edu


























