
📢 Webinar - 6/18 at 9am PST!
Stop re-running complex recursive queries when your graph data changes. Feldera incrementally evaluates recursive graph computations. Learn to easily build these mechanisms with #SQL, without the hassle of constant recomputation.
tinyurl.com/rb5my7d8
11.06.2025 22:13 — 👍 7 🔁 4 💬 0 📌 1
We’ll be at the #Databricks Data + AI Summit in SF next week (6/9–12).
If you’re around and want to chat about how incremental computing can make your #SparkSQL workloads go from hours to seconds — let’s connect.
Grab some time here: calendly.com/matt-feldera...
#DataAISummit #DataEngineering
05.06.2025 20:47 — 👍 4 🔁 2 💬 0 📌 1
🧵1/ Real-Time Medallion, No Re-Architecture Required.
A customer came to us with a classic Medallion setup: Spark + Delta Lake, batch jobs moving data from bronze to gold. It worked—until users started asking for fresher insights.
28.05.2025 23:33 — 👍 5 🔁 2 💬 1 📌 1
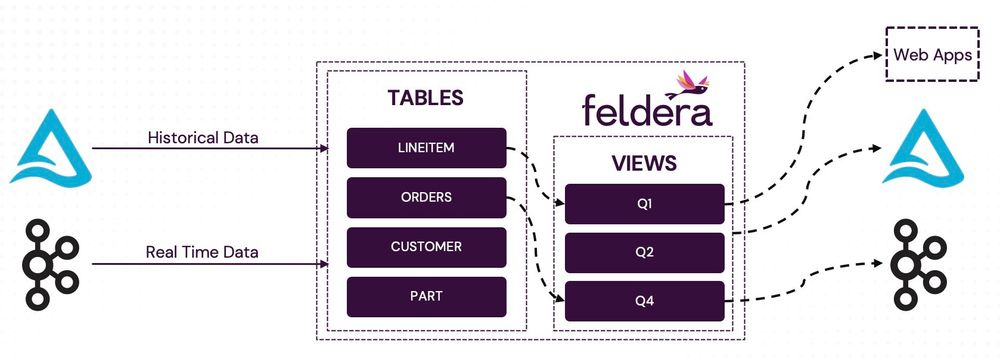
Learn how to transform your slow batch jobs into real-time, always-up-to-date insights with our new user guide for converting Spark jobs to incremental Feldera pipelines.
www.feldera.com/blog/warpspeed
08.05.2025 15:21 — 👍 2 🔁 3 💬 1 📌 0
Software Engineer: Cloud
Software Engineer: Cloud
It's a wonderful time to join us at @feldera.bsky.social! 🚀
If you're a systems engineer who loves working on data-intensive systems and is fluent in Rust, Kubernetes, Docker and cloud tech, do apply!
jobs.ashbyhq.com/feldera/9754...
02.05.2025 22:41 — 👍 7 🔁 3 💬 0 📌 0
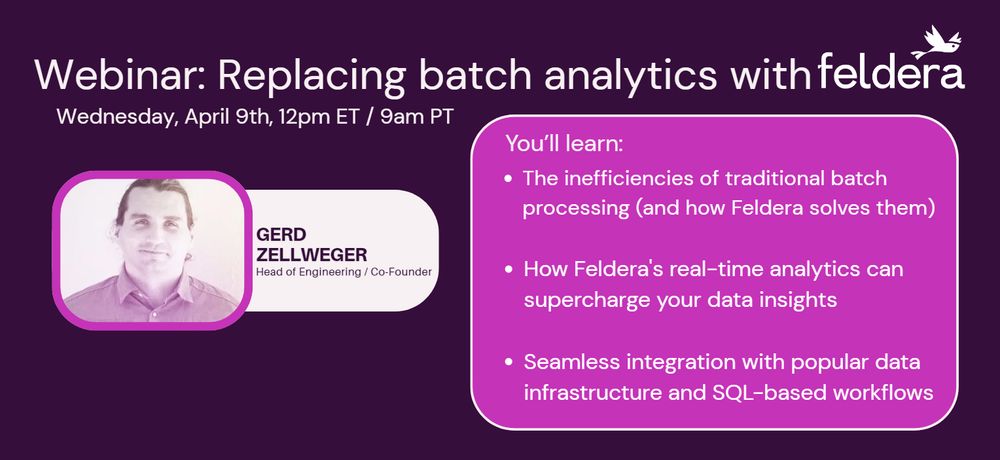
Join us for an in-depth webinar on how Feldera transforms batch analytics with its incremental computation engine.
Register shorturl.at/zQTLu
Wednesday, April 9th at 9am PST, 12pm EST
28.03.2025 16:34 — 👍 3 🔁 3 💬 0 📌 1

🛠️ Our new user guide describes how to convert a Spark batch job into an incremental Feldera pipeline: docs.feldera.com/use_cases/ba....
24.03.2025 15:58 — 👍 2 🔁 1 💬 0 📌 0
YouTube video by The Geek Narrator
Powering Incremental Compute with Mathematics - Feldera
Listen to @thegeeknarrator.bsky.social podcast! @feldera.bsky.social CEO, @lalithsuresh.bsky.social, discusses Feldera's approach to incremental view maintenance and the foundational breakthrough -- DBSP -- that powers it, engine internals, storage, handling late events.
youtu.be/GpcIoABwF60?...
17.03.2025 17:26 — 👍 8 🔁 4 💬 0 📌 1

If you're attending the Fintech Meetup next week in Las Vegas, come find @feldera.bsky.social at the startup lounge (Booth S6).
We want to meet you!
06.03.2025 20:19 — 👍 2 🔁 2 💬 0 📌 1

Last month, we announced S3 support for our pipelines.
Today, we're making it real: You can now try it out directly in the online sandbox.
No SQL changes are needed—tweak a bit of JSON in your pipeline settings, and you're set.
www.feldera.com/blog/leverag...
05.03.2025 19:37 — 👍 5 🔁 3 💬 0 📌 0

@feldera.bsky.social v0.38 release - packed with improvements:
- A new redis output connector, easily and efficiently send data to the popular KV-store.
- Support for input connector orchestration so you can easily manage complex backfill scenarios
Learn more: www.feldera.com/blog/increme...
26.02.2025 20:27 — 👍 4 🔁 2 💬 0 📌 0

From Traces to Insights: How to Analyze OpenTelemetry Data in Real-Time with SQL
Analyzing OpenTelemetry data to generate insightful visualizations using Feldera.
Are you OTel Curious? Feldera Engineer Abhinav Gyawali breaks down how to compute on streams of OTel data using Feldera.
If you're looking to build your own observability solutions, check out this blog!
www.feldera.com/blog/opentel...
13.02.2025 20:59 — 👍 7 🔁 5 💬 0 📌 0

Hello v0.37, what's new?
Storage: Bloom filters, file compression, smarter data management, a configurable memory cache.
Code Generation: Avoids data duplication & optimizes outer joins.
Runtime Optimizations: Data is stored, handled internally, for the better.
www.feldera.com/blog/increme...
13.02.2025 16:15 — 👍 1 🔁 1 💬 0 📌 1
You can learn more about Feldera's capabilities in our interactive sandbox environment. No commitment, just pure exploration.
Take the first step towards faster, more efficient data processing.
try.feldera.com
10.02.2025 20:01 — 👍 6 🔁 4 💬 0 📌 0

Announcing S3-backed Pipelines
S3-backed pipelines allow your incremental compute pipelines to use zero disks and scale far beyond typical local storage sizes.
📢 S3-backed Pipelines coming to Feldera!
🚀Handle datasets larger than local storage with ease using Amazon S3, Google Cloud Storage, or Azure Blob Store.
Unprecedented scalability for real-time & batch processing.
Preview for Enterprise users in Feb!
www.feldera.com/blog/s3-back...
04.02.2025 00:19 — 👍 6 🔁 1 💬 0 📌 1

Incremental Update 15 at Feldera
Big records and JSON!
Feldera v0.36 is here:
-📈 runtime & compilation performance for big programs & complex SQL schemas
-Optimized LEFT JOINs for ⬇️memory usage & ⬆️throughput
-Data compression capabilities for ⬆️storage $
-Multiway merging strategy for improved LSM-tree mgmt
www.feldera.com/blog/increme...
28.01.2025 23:08 — 👍 5 🔁 2 💬 0 📌 0

Implementing Batch Processes with Feldera
Implementing Batch Processes with Feldera
Unlike traditional databases that slow down with data growth, our fully automatic incremental computation maintains consistent performance. Ideal for both batch and real-time data processing.
Learn more about steady performance as your #data grows!
www.feldera.com/blog/batch-p...
#datastreaming
22.01.2025 21:06 — 👍 3 🔁 4 💬 0 📌 0

Solving Fine-Grained Authorization by Turning the Problem on its Head
Build a high-performance policy engine with only a few lines of SQL.
Have you heard of fine-grained authorization (FGA)? It uses a lot of compute, which makes it expensive. But with Feldera, you can implement it more cheaply using incremental computation. See the full story in the @feldera.bsky.social blog at: www.feldera.com/blog/fine-gr...
15.01.2025 18:46 — 👍 6 🔁 3 💬 0 📌 0
Incremental Update 14 at Feldera
Updated documentation, faster HTTP ingest and SQL fixes!
We've posted two exciting new use cases to our documentation
🔐 a policy engine for fine-grained authorization
🚀 building live and real-time web applications
We have also improved HTTP performance and sprinkled in some SQL compiler bug fixes.
www.feldera.com/blog/increme...
13.01.2025 20:18 — 👍 1 🔁 3 💬 0 📌 1
YouTube video by Feldera, Inc.
Feldera Webinar: Incremental Billion Cell Spreadsheets
Federa Tutorial: Building a Billion-Cell Spreadsheet: create a fully functional, scalable spreadsheet web application using just 100 lines of SQL!
www.youtube.com/watch?v=ROa4...
09.01.2025 17:00 — 👍 5 🔁 1 💬 0 📌 1
How about a billion-cell online spreadsheet built with <300 lines of SQL+Rust!
06.01.2025 20:01 — 👍 2 🔁 0 💬 0 📌 0

Tired of slow batch processing as your data grows? @felderainc 's incremental processing maintains lightning-fast performance no matter your data size. Perfect for batch, real-time, or hybrid processing needs! ⚡️
www.feldera.com/blog/batch-p...
18.12.2024 22:52 — 👍 7 🔁 4 💬 0 📌 1
Feldera Webinar: Incremental Billion Cell Spreadsheets
Join our Feldera Webinar to learn how to build a real-time application that can scale effortlessly!
🚀 Tech wizards!
Join our webinar on building apps for billion-cell spreadsheets.
Learn to create a spreadsheet app in 100 lines of SQL, explore Feldera's incremental engine, and dive into advanced SQL.
Jan 8, 9-10 am PST. Register below:
www.eventbrite.com/e/feldera-we...
17.12.2024 19:56 — 👍 2 🔁 1 💬 0 📌 1

Real-time feature engineering with Feldera. Part 2.
We put Feldera to work to implement real-time feature engineering for credit card fraud detection on top of a Delta Lake.
🚨 Catch credit card fraudsters in real time!
💳Our blog post shows how to use Feldera for live transaction feature engineering, achieving seamless offline-online parity in fraud detection. www.feldera.com/blog/feature...
#FraudDetection #MachineLearning #Feldera
17.12.2024 17:48 — 👍 2 🔁 2 💬 0 📌 0

Real-time feature engineering is hard (but it doesn't need to be)
Real-time feature engineering is among the most important applications of streaming analytics today.
✍️ Over the past few months, I’ve written a series of blogs on real-time feature engineering, focusing on key challenges in this space—such as online/offline parity and feature freshness—and how @feldera.bsky.social addresses these challenges.
📖 Check them out here: www.feldera.com/blog/feature...
12.12.2024 22:33 — 👍 14 🔁 2 💬 1 📌 1

Recursive SQL queries in Feldera
Recursive SQL queries in Feldera
📢New recursive query support in Feldera's SQL compiler.
Allows for mutually recursive views without needing common table expressions, making it easier to express complex queries.
Unlocking use cases for graph compute, security policy engines, & more
www.feldera.com/blog/recursi...
12.12.2024 17:42 — 👍 2 🔁 2 💬 0 📌 1
Incremental Update 12 at Feldera
Better compiler cache, better delta-lake adapter and many bugs fixed.
🚀 Feldera has released version 0.32!
This update features an optimized compilation cache that cuts down on unnecessary Rust compilations.
The Delta Lake connector now processes large datasets much more efficiently-spend less time sorting.
Read more here: www.feldera.com/blog/increme...
11.12.2024 20:27 — 👍 3 🔁 3 💬 0 📌 0

Fault tolerance means that if a compute node fails, the pipelines seamlessly restart and resume processing from where they left off. We're diving into the technical magic behind it—periodic checkpointing and careful logging ensure your workflow stays uninterrupted.
www.feldera.com/blog/fault-t...
09.12.2024 21:11 — 👍 2 🔁 1 💬 0 📌 1












