This was a collaborative work with Siddhant Agarwal,
@pranayajajoo.bsky.social
, Samyak Parajuli, Caleb Chuck, Max Rudolph, Peter Stone, Amy Zhang, @scottniekum.bsky.social .Also, a joint effort across universities:
@texasrobotics.bsky.social
, UMass Amherst, U Alberta
11.12.2024 07:12 —
👍 0
🔁 0
💬 0
📌 0
(9/n) For instance,
a) future approaches can initialize a behavior instantly by prompting for later finetuning,
b) Or come up with approaches to plan in lang. space and translate each instruction to low-level control
c) With gen. video models getting better (e.g. Sora) RLZero will only get better.
11.12.2024 07:11 —
👍 0
🔁 0
💬 1
📌 0
(8/n) Zero-shot = no inference time training (no costly/unsafe RL training during inference)
+
Unsupervised = no costly dataset labeling (a big issue for robotics!)
is a promising recipe for scaling up robot learning.
11.12.2024 07:11 —
👍 0
🔁 0
💬 1
📌 0
(7/n) This project is close to my heart as it realizes a dream I shared with @scottniekum.bsky.social when I started my PhD to go beyond the limitation of matching observations in imitation learning rather than capturing the semantic understanding of what doing a task means.
11.12.2024 07:11 —
👍 0
🔁 0
💬 1
📌 0
(6/n) With RLZero, you can just pass in a YouTube video and ask an agent to mimic the behavior instantly. This brings us closer to true zero-shot cross-embodiment transfer.
11.12.2024 07:11 —
👍 1
🔁 0
💬 1
📌 0
(5/n) RLZero’s Prompt to Policy: Asking a humanoid agent to perform a headstand.
11.12.2024 07:11 —
👍 0
🔁 0
💬 1
📌 0
(4/n) Reward is an inconvenient and easily hackable form of task specification. Now, we can prompt and obtain behaviors zero-shot with language. Example: Asking a walker agent to perform a cartwheel.
11.12.2024 07:11 —
👍 0
🔁 0
💬 1
📌 0
(3/n) Given a text prompt, RL Zero imagines 🧠 the expected behavior of the agent using generative video models. The imaginations are projected and grounded to the observations that the agent has encountered in the past. Finally, zero-shot imitation learning converts the grounded obs into a policy.
11.12.2024 07:11 —
👍 0
🔁 0
💬 1
📌 0
(2/n) RL Zero enables prompt-to-policy generation, and we believe this unlocks new capabilities in scaling up language-conditioned RL, providing an interpretable link between RL agents and humans and achieving true cross-embodiment transfer.
11.12.2024 07:11 —
👍 0
🔁 0
💬 1
📌 0
🤖 Introducing RL Zero 🤖: a new approach to transform language into behavior zero-shot for embodied agents without labeled datasets!
11.12.2024 07:11 —
👍 15
🔁 4
💬 1
📌 2
(7/n) This project is close to my heart as it realizes a dream I shared with @scottniekum.bsky.social when I started my PhD to go beyond the limitation of matching observations in imitation learning rather than capturing the semantic understanding of what doing a task means.
10.12.2024 08:14 —
👍 0
🔁 0
💬 0
📌 0
(6/n) With RLZero, you can just pass in a YouTube video and ask an agent to mimic the behavior instantly. This brings us closer to true zero-shot cross-embodiment transfer.
10.12.2024 08:14 —
👍 0
🔁 0
💬 1
📌 0
(5/n) RLZero’s Prompt to Policy: Asking a humanoid agent to perform a headstand.
10.12.2024 08:14 —
👍 0
🔁 0
💬 1
📌 0
(4/n) Reward is an inconvenient and easily hackable form of task specification. Now, we can prompt and obtain behaviors zero-shot with language. Example: Asking a walker agent to perform a cartwheel.
10.12.2024 08:14 —
👍 0
🔁 0
💬 1
📌 0
(3/n) Given a text prompt, RL Zero imagines 🧠 the expected behavior of the agent using generative video models. The imaginations are projected and grounded to the observations that the agent has encountered in the past. Finally, zero-shot imitation learning converts the grounded obs into a policy.
10.12.2024 08:14 —
👍 0
🔁 0
💬 1
📌 0
(2/n) RL Zero enables prompt-to-policy generation, and we believe this unlocks new capabilities in scaling up language-conditioned RL, providing an interpretable link between RL agents and humans and achieving true cross-embodiment transfer.
10.12.2024 08:14 —
👍 0
🔁 0
💬 1
📌 0
(3/5) We give an efficient algorithm to learn such basis, and once these are learned as a part of pretraining, inference amounts to solving a simple linear program. This allows PSM to do zero-shot RL in a way that is more performant and stable than baselines.
03.12.2024 00:33 —
👍 0
🔁 0
💬 1
📌 0
(2/5) Our work, Proto-Successor Measures (PSM), shows that valid successor measures form an affine set. PSM learns a basis of the affine set where the dimensionality of the basis controls the compression of MDP (or the information lost). After all, learning is compression.
03.12.2024 00:33 —
👍 1
🔁 0
💬 1
📌 0
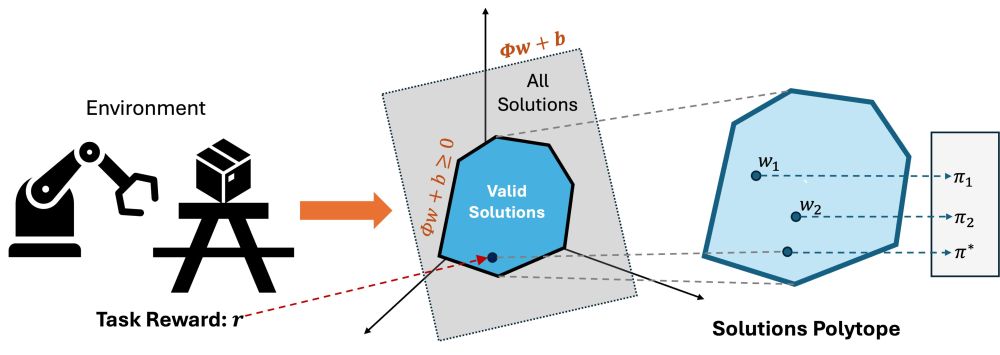
What if I told you all solutions for RL lie on a (hyper) plane? Then, we can use that fact to learn a compressed representation for MDP that unlocks efficient policy inference for any reward fn. On this plane, solving RL is equivalent to solving a linear constrained optimization!
03.12.2024 00:33 —
👍 7
🔁 0
💬 1
📌 0
Harshit Sikchi
I will be attending @neuripsconf.bsky.social and am on the job market. Hit me up to chat about topics in RL (Zero-shot RL, Imitation Learning, Offline RL, Deep RL) or Alignment!
Learn more about my research interests: hari-sikchi.github.io/research/
02.12.2024 00:39 —
👍 9
🔁 1
💬 0
📌 0
we should catch up if you are available!
01.12.2024 00:42 —
👍 1
🔁 0
💬 1
📌 0
This is just a bad year for ICLR authors and reviewers 😥
25.11.2024 16:35 —
👍 4
🔁 0
💬 1
📌 0
Can you add me too? 🙋♂️
17.11.2024 01:18 —
👍 1
🔁 0
💬 1
📌 0
🙋♂️Seems relevant to me too!
17.11.2024 01:15 —
👍 0
🔁 0
💬 0
📌 0






