
Where do some of Reinforcement Learning's great thinkers stand today?
Find out! Keynotes of the RL Conference are online:
www.youtube.com/playlist?lis...
Wanting vs liking, Agent factories, Theoretical limit of LLMs, Pluralist value, RL teachers, Knowledge flywheels
(guess who talked about which!)
27.08.2025 12:46 — 👍 75 🔁 23 💬 1 📌 1
One more day! One more day!
05.08.2025 01:45 — 👍 4 🔁 3 💬 0 📌 0
YouTube video by Boiler Room
100 gecs | Boiler Room: Los Angeles
If you haven’t seen this DJ set they did a few years ago, it is worth a watch: www.youtube.com/watch?v=8NWH...
07.07.2025 23:34 — 👍 4 🔁 0 💬 1 📌 0
RLC Call for Workshops
Propose some socials for RLC! Research topics, affinity groups, niche interests, whatever comes to mind!
rl-conference.cc/call_for_soc...
25.06.2025 13:26 — 👍 11 🔁 8 💬 0 📌 2
Reminder that early registration for RLC closes on the 30th! Please register early to save yourself some money and help us get the word out.
27.05.2025 14:56 — 👍 7 🔁 5 💬 0 📌 1
Science will take a huge hit; academic stars will leave; university reputations will crumble, and homegrown talent will be even harder to find.
Asia and Europe will profit.
Epic unforced errors, all in the overly narrow pursuit of cutting costs.
08.02.2025 14:40 — 👍 41 🔁 11 💬 5 📌 1
Check out some of the exciting changes to the RLC reviewing process! We're always trying new things to perfect it
26.01.2025 02:14 — 👍 6 🔁 1 💬 0 📌 0
YouTube video by Musical Novelties
The Plot To Blow Up The Eiffel Tower - Dissertation, Honey [FULL ALBUM]
Fellow THOU fan here. Converge—Jane Doe will forever be my go-to paper writing album though. Something about that record puts my fingers on automatic. Although this morning I’m ICMLing to this jazz-punk classic and highly recommend: youtu.be/rl4DnYwjjuU?...
21.01.2025 12:29 — 👍 4 🔁 0 💬 1 📌 0
Yeah, but on the other hand I might be wrong and underestimating how many people even Yarvin might convince. I’ve previously been annoyed at NYT platforming certain people for op-eds and I’m having trouble reconciling that with my feelings on this. Maybe interview at least pushes back slightly?
19.01.2025 21:23 — 👍 2 🔁 0 💬 1 📌 0
Concretely, when I imagine the population that would fall for the Vance version, I assume that some subset would reject his ideas if they had heard Yarvin's version first, came up with a refutation, and knew how to recognize more sneaky versions due to their prior experience with the rougher version
19.01.2025 20:15 — 👍 1 🔁 0 💬 1 📌 0
I think it can be a mistake to platform bad actors for reasons you mentioned. But once you have someone like a VP citing this stuff, it can be good to let a representative show off their own weakest ideas (and maybe even more effective when you are semi neutral and let the listener do the thinking)
19.01.2025 20:00 — 👍 1 🔁 0 💬 1 📌 0
The arguments were so wildly broken (governance shares no meaningful properties with a laptop!) that I hope it would be self evident to many. But with versions of these ideas hitting the mainstream via Thiel, Vance, etc., there’s no hiding from it, and I’d rather people see this unvarnished version
19.01.2025 19:53 — 👍 1 🔁 0 💬 1 📌 0
I still think it is good on balance that the interview happened. These are ideas that are now being pushed by more sophisticated, savvy, and powerful people than Yarvin. Hearing them in raw form helps to inoculate people against them before they get repackaged in sneakier, more palatable forms IMO.
19.01.2025 18:26 — 👍 1 🔁 0 💬 1 📌 0

First page of the paper Influencing Humans to Conform to Preference Models for RLHF, by Hatgis-Kessell et al.
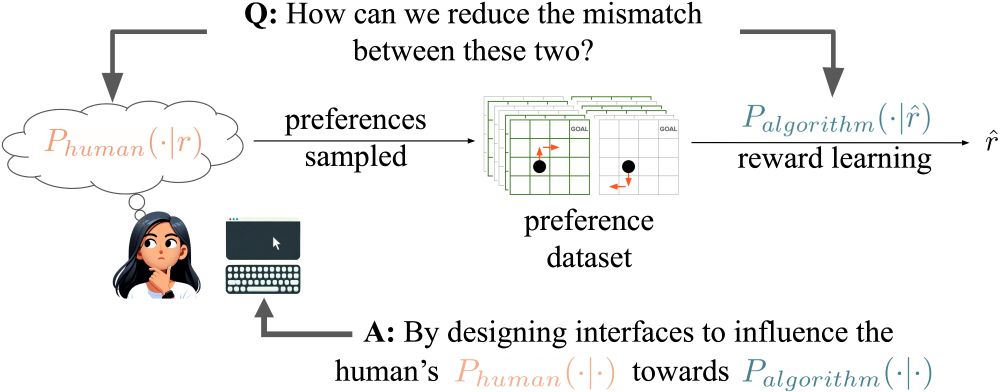
Our proposed method of influencing human preferences.
RLHF algorithms assume humans generate preferences according to normative models. We propose a new method for model alignment: influence humans to conform to these assumptions through interface design. Good news: it works!
#AI #MachineLearning #RLHF #Alignment (1/n)
14.01.2025 23:51 — 👍 7 🔁 3 💬 1 📌 0
I'm quite excited about this and still a bit shocked that it works as well as it does. Imitation via distribution matching has always felt like a clunky, brittle way to command agents. Language + zero-shot RL is natural, instantaneous, and scales well, due to the unsupervised nature of RL Zero.
11.12.2024 11:42 — 👍 0 🔁 0 💬 0 📌 0
If you're at NeurIPS, RLC is hosting an RL event from 8 till late at The Pearl on Dec. 11th. Join us, meet all the RL researchers, and spread the word!
10.12.2024 21:55 — 👍 63 🔁 18 💬 2 📌 4
RLJ | RLC Call for Papers
The call for papers for RLC is now up! Abstract deadline of 2/14, submission deadline of 2/21!
Please help us spread the word.
rl-conference.cc/callforpaper...
02.12.2024 15:39 — 👍 54 🔁 18 💬 1 📌 9
RLC will be held at the Univ. of Alberta, Edmonton, in 2025. I'm happy to say that we now have the conference's website out: rl-conference.cc/index.html
Looking forward to seeing you all there!
@rl-conference.bsky.social
#reinforcementlearning
22.11.2024 22:46 — 👍 60 🔁 19 💬 2 📌 2
Further details and a call for workshops will be posted soon. We hope to see you all in Amherst this August!
15.11.2023 15:16 — 👍 0 🔁 0 💬 0 📌 0
RLC is organized by @yayitsAmyZhang (UT Austin), @GlenBerseth (MILA), @EugeneVinitsky (NYU), @ScottNiekum (UMass Amherst), Philip Thomas (UMass Amherst), and @BrunoSilvaUMass (UMass Amherst)
15.11.2023 15:16 — 👍 0 🔁 0 💬 1 📌 0
We have a fantastic advisory board helping to guide us, including @PeterStone_TX, Satinder Singh, @EmmaBrunskill, @mlittmancs, @MannorShie, Michael Bowling, @svlevine, @ravi_iitm, @ShamKakade6, @BenjaminRosman, Marc Deisenroth, and Andrew Barto.
15.11.2023 15:16 — 👍 1 🔁 0 💬 1 📌 0
How will @RL_Conference be different from other ML conferences? Besides focusing on RL, peer review will primarily evaluate the correctness and support of claims, rather than subjective perceptions of importance.
15.11.2023 15:15 — 👍 0 🔁 0 💬 1 📌 0
Reinforcement Learning as a field has been growing significantly in the past 10 years but lacks a central archival venue. Other communities (CV, NLP, robotics) have benefited from having their own top-tier venues and RL is past due for the same.
15.11.2023 15:15 — 👍 1 🔁 0 💬 1 📌 0

Thrilled to announce the first annual Reinforcement Learning Conference @RL_Conference, which will be held at UMass Amherst August 9-12! RLC is the first strongly peer-reviewed RL venue with proceedings, and our call for papers is now available: rl-conference.cc.
15.11.2023 15:15 — 👍 8 🔁 1 💬 1 📌 1
There Is No Antimemetics Division (https://qntm.org/antimemetics) ~ "Lena" ~ Absurdle ~ HATETRIS ~ many other cool things
The Manning College of Information and Computer Sciences at UMass Amherst is a top-tier institution dedicated to the common good.
Professor at the University of Massachusetts Amherst
https://people.cs.umass.edu/~brun/
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
Professor a NYU; Chief AI Scientist at Meta.
Researcher in AI, Machine Learning, Robotics, etc.
ACM Turing Award Laureate.
http://yann.lecun.com
Information and updates about RLC 2025 at the University of Alberta from Aug. 5th to 8th!
https://rl-conference.cc
Assistant Prof at @UMontreal @mila-quebec.bsky.social @MontrealRobots
. CIFAR AI Chair, RL_Conference chair. Creating generalist problem-solving agents for the real world. He/him/il.
Foundation Models for Generalizable Autonomy.
Assistant Professor in AI Robotics, Georgia Tech
prev Berkeley, Stanford, Toronto, Nvidia
Associate professor @ Université Laval - IID - Mila
Interested in reinforcement learning, bandits, partial monitoring, active learning, ... anything that learns by getting its own data from the environment!
PhD student at UC Berkeley studying RL and AI safety.
https://cassidylaidlaw.com
machine learning and artificial intelligence | University of Chicago / Google
Machine learning, environmental modeling, sustainability, robotics
Professor @UCL
He/him
full-time ML theory nerd, part-time AI-non enthusiast
Research Scientist at GDM. Statistician. Mostly work on Responsible AI. Academia-industry flip-flopper.
Assistant Prof of CS at the University of Waterloo, Faculty and Canada CIFAR AI Chair at the Vector Institute. Joining NYU Courant in September 2026. Co-EiC of TMLR. My group is The Salon. Privacy, robustness, machine learning.
http://www.gautamkamath.com
Computer science, math, machine learning, (differential) privacy
Researcher at Google DeepMind
Kiwi🇳🇿 in California🇺🇸
http://stein.ke/
Assistant Professor at UW and Staff Research Scientist at Google DeepMind. Social Reinforcement Learning in multi-agent and human-AI interactions. PhD from MIT. Check out https://socialrl.cs.washington.edu/ and https://natashajaques.ai/.
Professor of Computer Science at Oxford. Senior Staff Research Scientist at Waymo.
RS DeepMind. Works on Unsupervised Environment Design, Problem Specification, Game/Decision Theory, RL, AIS. prev CHAI_Berkeley
final year PhD student at @cmurobotics.bsky.social working on efficient algorithms for interactive learning (e.g. imitation / RL / RLHF). no model is an island. prefers email. https://gokul.dev/.



![The Plot To Blow Up The Eiffel Tower - Dissertation, Honey [FULL ALBUM]](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:fjmwanfznmnjoj2utcad5ynm/bafkreiae7mzfmxhry65h3jbwcbczmzjw6nbep4ihzhdiui77z3iq7bsbre@jpeg)



















