I will be at @iclr-conf.bsky.social next week! If you are interested in any of these four postdoc positions, reach out to me via whova app so that we can meet during the conference!
18.04.2025 13:57 — 👍 1 🔁 0 💬 0 📌 0

Mila Techaide 2025 | Mila
Conférence IA d'une journée au profit de Centraide du Grand Montréal
Join us on April 17th for Mila TechAide 2025! 🌟 Hear from amazing speakers in #AI like Sara Hooker, Kyunghyun Cho, Golnoosh Farnadi, David Adelani, Derek Nowrouzezahrai, and Tegan Maharaj. All proceeds support #Centraide. Let's make a difference together! 💡🤝
Get your tickets now! t.co/EBsatAqGTA
12.04.2025 10:46 — 👍 6 🔁 4 💬 0 📌 0

We have an amazing lineup of speakers, who will share their experience in deploying RL for power systems, industrial processes, nuclear fusion, logistics and more!
Consider submitting!
08.04.2025 13:53 — 👍 5 🔁 4 💬 0 📌 1
Do you care about applying RL to real systems? You should consider attending our RLC 2025 workshop on RL for real systems!
08.04.2025 14:06 — 👍 1 🔁 0 💬 0 📌 0
We know that policies learned through self-play can result in brittle, over-specialized strategies. But in our ICLR paper, we show that, provided the right representation and network architecture, self-play can learn generalizable cooperative policies! Congrats Arjun and Hadi for leading this work!
06.04.2025 14:44 — 👍 3 🔁 1 💬 0 📌 0
Collaborative Multi Agent Reinforcement Learning is key for AI in the future. Check out R3D2, a generalist agent working on text-based Hanabi, accepted at ICLR 2025.
Website: chandar-lab.github.io/R3D2-A-Gener...
04.04.2025 17:16 — 👍 1 🔁 2 💬 0 📌 0
Excited to share our ICLR 2025 paper: A Generalist Hanabi Agent!🎇
R3D2 agent plays all Hanabi settings at once and coordinates zero-shot with novel partners (Something SOTA LLMs can't do)—powered by flexible architecture that handle changing obs/action spaces. 🧵👇
04.04.2025 17:15 — 👍 2 🔁 1 💬 0 📌 0

A Generalist Hanabi Agent
Traditional multi-agent reinforcement learning (MARL) systems can develop cooperative strategies through repeated interactions. However, these systems are unable to perform well on any other setting t...
🤝 This was a project led by my students Arjun and
Hadi, in collaboration with Mathieu, Miao, and Janarthanan!
Paper: arxiv.org/abs/2503.14555
Code: github.com/chandar-lab/...
Models: huggingface.co/chandar-lab/...
Website: chandar-lab.github.io/R3D2-A-Gener.... 7/7
04.04.2025 17:12 — 👍 0 🔁 0 💬 0 📌 0
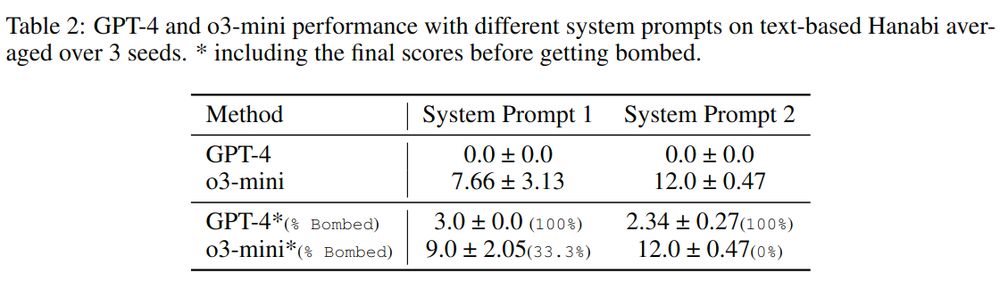
🧠 Can LLMs master Hanabi without RL? We tested SOTA models by prompting them or finetuning them with expert trajectories.
Results? Still far off—o3-mini scored only 12 out of 25 even with extensive prompting! 🚧 #LLMs 6/n
04.04.2025 17:12 — 👍 0 🔁 0 💬 1 📌 0
🎭 Robustness in Cross-Play: We introduce a new inter-setting eval alongside inter/intra-algorithm cross-play—R3D2 adapts smoothly to new agents & envs, outperforming others. Even our 12 (!) reviewers liked the thorough eval! 🔍 #CrossPlay
Openreview: openreview.net/forum?id=pCj...
5/n
04.04.2025 17:12 — 👍 0 🔁 0 💬 1 📌 0
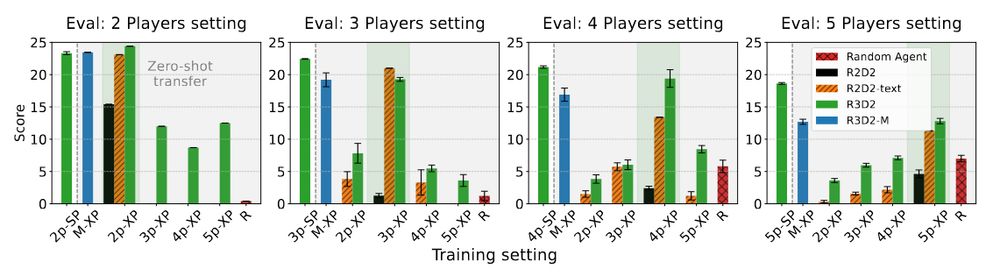
⚡Zero-Shot Coordination: R3D2 can be trained on multiple settings at once (e.g., 2p & 3p), using simpler games to boost learning in complex ones—letting it coordinate across unseen game settings and partners without explicit training on those settings! 4/n
04.04.2025 17:12 — 👍 1 🔁 0 💬 1 📌 0
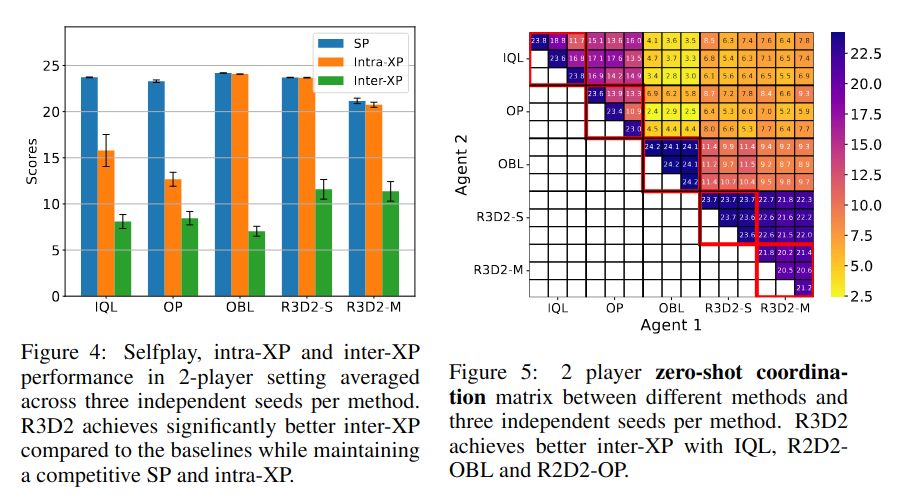
🔄 Self-Play & Generalization: R3D2 adapts to new partners & game setups without complex MARL tricks—just smart representations & architecture. Shows self-play alone can go far for generalizable policies! #ZeroShot #PolicyTransfer 3/n
04.04.2025 17:12 — 👍 0 🔁 0 💬 1 📌 0

🔡 Dynamic observation- and action-space: We frame Hanabi as a text game and use a dynamic action-space architecture, DRRN (He et al., 2015), letting R3D2 adapt across settings via text input—drawing on the power of language as representation. #TextGames 2/n
04.04.2025 17:12 — 👍 0 🔁 0 💬 1 📌 0
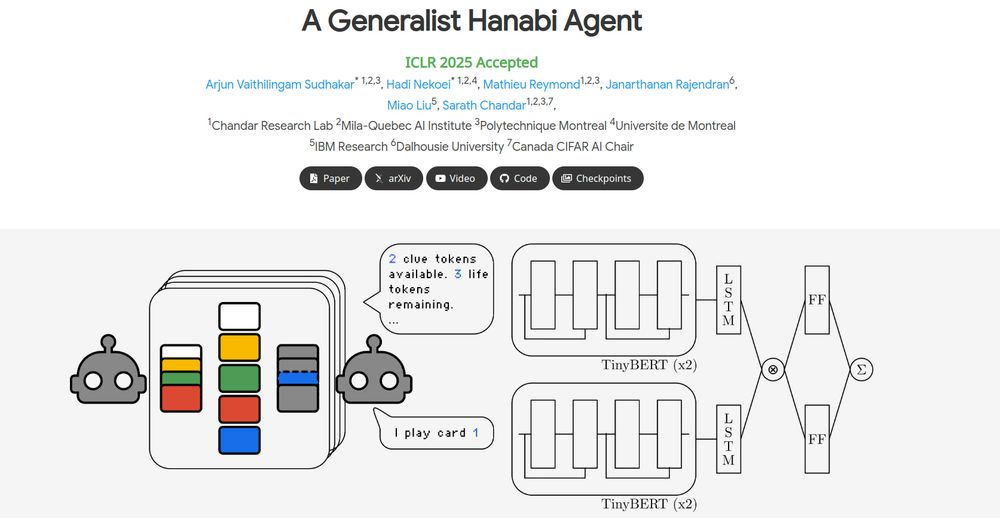
Can better architectures & representations make self-play enough for zero-shot coordination? 🤔
We explore this in our ICLR 2025 paper: A Generalist Hanabi Agent. We develop R3D2, the first agent to master all Hanabi settings and generalize to novel partners! 🚀 #ICLR2025 1/n
04.04.2025 17:12 — 👍 13 🔁 4 💬 1 📌 3
Apply here: tinyurl.com/crl-postdoc
Lab website: chandar-lab.github.io
2/2
21.03.2025 14:49 — 👍 1 🔁 0 💬 0 📌 0

In my lab, we have not one but four open postdoc positions! If you have strong research expertise and a PhD in LLMs and Foundation Models, and you are willing to learn about domain-specific problems and collaborate with domain experts, this is an ideal position for you! 1/2
21.03.2025 14:49 — 👍 6 🔁 1 💬 1 📌 4
 19.03.2025 14:07 — 👍 1 🔁 0 💬 0 📌 0
19.03.2025 14:07 — 👍 1 🔁 0 💬 0 📌 0
 19.03.2025 14:07 — 👍 1 🔁 0 💬 1 📌 0
19.03.2025 14:07 — 👍 1 🔁 0 💬 1 📌 0
 19.03.2025 14:07 — 👍 1 🔁 0 💬 1 📌 0
19.03.2025 14:07 — 👍 1 🔁 0 💬 1 📌 0
 19.03.2025 14:07 — 👍 1 🔁 0 💬 1 📌 0
19.03.2025 14:07 — 👍 1 🔁 0 💬 1 📌 0

I gave a talk on developing efficient foundation models for proteins and small molecules at the Helmholtz-ELLIS Workshop on Foundation Models in Science (www.mdc-berlin.de/news/events/...) today.
If you are interested in my spicy takes on ML for Biology, continue reading this thread! 1/n
19.03.2025 14:07 — 👍 3 🔁 0 💬 1 📌 0
I am excited to share that our BindGPT paper won the best poster award at #AAAI2025! Congratulations to the team! Work led by @artemzholus.bsky.social!
05.03.2025 14:54 — 👍 9 🔁 4 💬 0 📌 0

chandar-lab/NeoBERT · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
The best part? We are open-sourcing everything, including the intermediary model checkpoints. The main model is already on HuggingFace, be sure to check it out! (6/n)
Model: huggingface.co/chandar-lab/...
Paper: arxiv.org/abs/2502.19587
Code and checkpoints to be released soon!
28.02.2025 16:30 — 👍 7 🔁 1 💬 1 📌 0
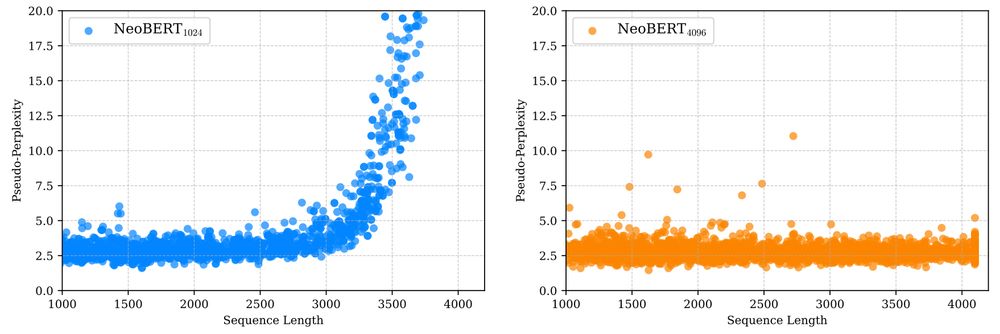
After training for 1M steps with a maximum sequence length of 1024, we did a final 50k steps at 4096. This two-step training was a cost-efficient strategy to scale the model’s maximum context window. For further scaling, our use of RoPE embeddings also lets us integrate YaRN! (5/n)
28.02.2025 16:30 — 👍 1 🔁 0 💬 1 📌 0
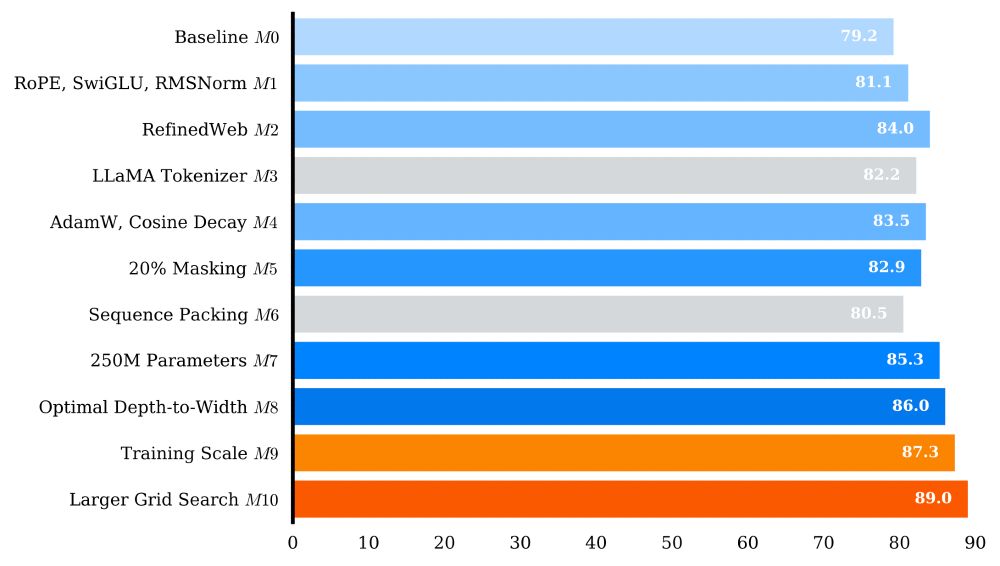
Before pre-training NeoBERT, we conducted thorough ablations on all our design choices by pre-training 9 different models at the scale of BERT (1M steps, 131k batch size). (4/n)
28.02.2025 16:30 — 👍 0 🔁 0 💬 1 📌 0
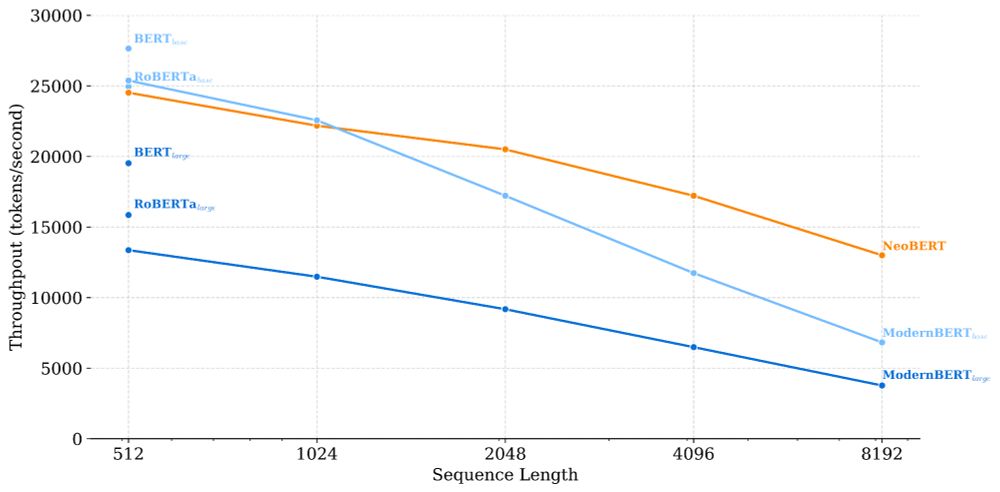
Its features include a native context length of 4,096, an optimal-depth-to-width ratio with 250M parameters, and the most efficient inference speeds of its kind! (3/n)
28.02.2025 16:30 — 👍 1 🔁 0 💬 1 📌 0
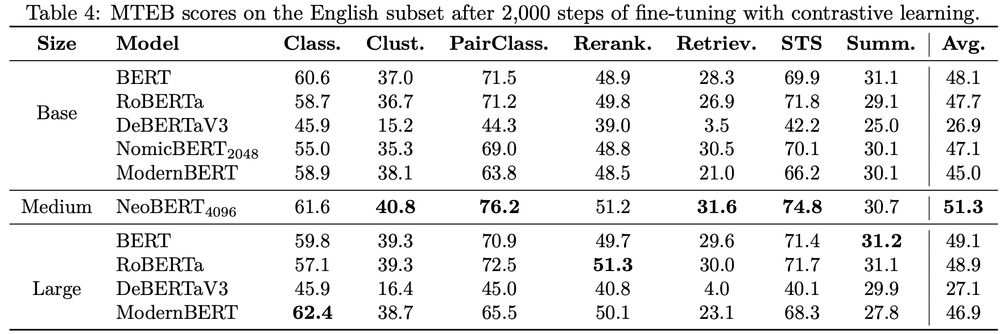
With identical finetuning, NeoBERT outperforms all baselines on MTEB! (2/n)
28.02.2025 16:30 — 👍 2 🔁 0 💬 1 📌 1

2025 BERT is NeoBERT! We have fully pre-trained a next-generation encoder for 2.1T tokens with the latest advances in data, training, and architecture. This is a heroic effort from my PhD student, Lola Le Breton, in collaboration with Quentin Fournier and Mariam El Mezouar (1/n)
28.02.2025 16:30 — 👍 39 🔁 11 💬 1 📌 4
Happy to share that one of my latest works has been accepted to AAAI25! BindGPT is a new foundational model for generative chemistry. It tackles various generative tasks, 3D molecule generation and 3D conformer generation, with a single model—something previously impossible. 1/2
bindgpt.github.io
27.02.2025 16:59 — 👍 5 🔁 1 💬 2 📌 0
PhD Candidate @ Mila/UdeM, Visiting Researcher @ServiceNowResearch
Assistant Professor at University of Pennsylvania.
Robot Learning.
https://www.seas.upenn.edu/~dineshj/
Final-year PhD student in AI at Mila (Quebec AI Institute) and McGill University w/ Doina Precup.
Research: RL, continual RL, and neuro-inspired RL.
Professor for AI at Hasso Plattner Institute and University of Potsdam
Berlin (prev. Rutgers NJ USA, Tsinghua Beijing, Berkeley)
http://gerard.demelo.org
Researcher and CIFAR Fellow, working on the intersection of machine learning and neuroscience in Montréal at @mcgill.ca and @mila-quebec.bsky.social.
Anti-cynic. Towards a weirder future. Reinforcement Learning, Autonomous Vehicles, transportation systems, the works. Asst. Prof at NYU
https://emerge-lab.github.io
https://www.admonymous.co/eugenevinitsky
AI @ OpenAI, Tesla, Stanford
Assistant Prof at @UMontreal @mila-quebec.bsky.social @MontrealRobots
. CIFAR AI Chair, RL_Conference chair. Creating generalist problem-solving agents for the real world. He/him/il.
FAIR Researcher @metaai.bsky.social Previously Mila-Quebec, Microsoft Research, Adobe Research, IIT Roorkee
official Bluesky account (check username👆)
Bugs, feature requests, feedback: support@bsky.app














