🔗 Resources for ESPnet-SDS:
📂 Codebase (part of ESPnet): github.com/espnet/espnet
📖 README & User Guide: github.com/espnet/espne...
🎥 Demo Video: www.youtube.com/watch?v=kI_D...
17.03.2025 14:29 — 👍 1 🔁 1 💬 0 📌 0
This was joint work with my co-authors at
@ltiatcmu.bsky.social , Sony Japan and Hugging Face ( @shinjiw.bsky.social @pengyf.bsky.social @jiatongs.bsky.social @wanchichen.bsky.social @shikharb.bsky.social @emonosuke.bsky.social @cromz22.bsky.social @reach-vb.hf.co @wavlab.bsky.social ).
17.03.2025 14:29 — 👍 1 🔁 0 💬 1 📌 0

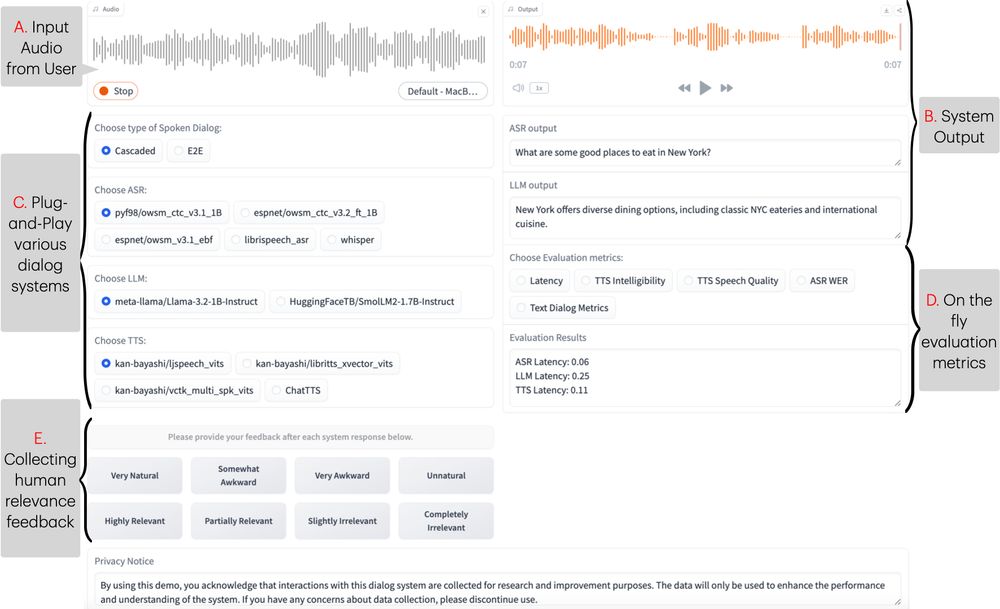
ESPnet-SDS provides:
✅ Unified Web UI with support for both cascaded & E2E models
✅ Real-time evaluation of latency, semantic coherence, audio quality & more
✅ Mechanism for collecting user feedback
✅ Open-source with modular code -> could easily incorporate new systems!
17.03.2025 14:29 — 👍 0 🔁 0 💬 1 📌 0
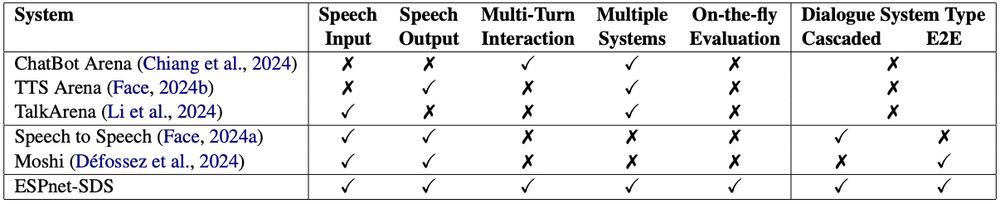
Spoken dialogue systems (SDS) are everywhere, with many new systems emerging.
But evaluating and comparing them is challenging:
❌ No standardized interface—different frontends & backends
❌ Complex and inconsistent evaluation metrics
ESPnet-SDS aims to fix this!
17.03.2025 14:29 — 👍 0 🔁 0 💬 1 📌 0
New #NAACL2025 demo, Excited to introduce ESPnet-SDS, a new open-source toolkit for building unified web interfaces for both cascaded & end-to-end spoken dialogue system, providing real-time evaluation, and more!
📜: arxiv.org/abs/2503.08533
Live Demo: huggingface.co/spaces/Siddh...
17.03.2025 14:29 — 👍 7 🔁 5 💬 1 📌 0
This work was done during my internship at Apple with Zhiyun Lu, Chung-Cheng Chiu, @ruomingpang.bsky.social
along with co-authors @ltiatcmu.bsky.social ( @shinjiw.bsky.social @wavlab.bsky.social).
(9/9)
05.03.2025 16:03 — 👍 1 🔁 1 💬 0 📌 0
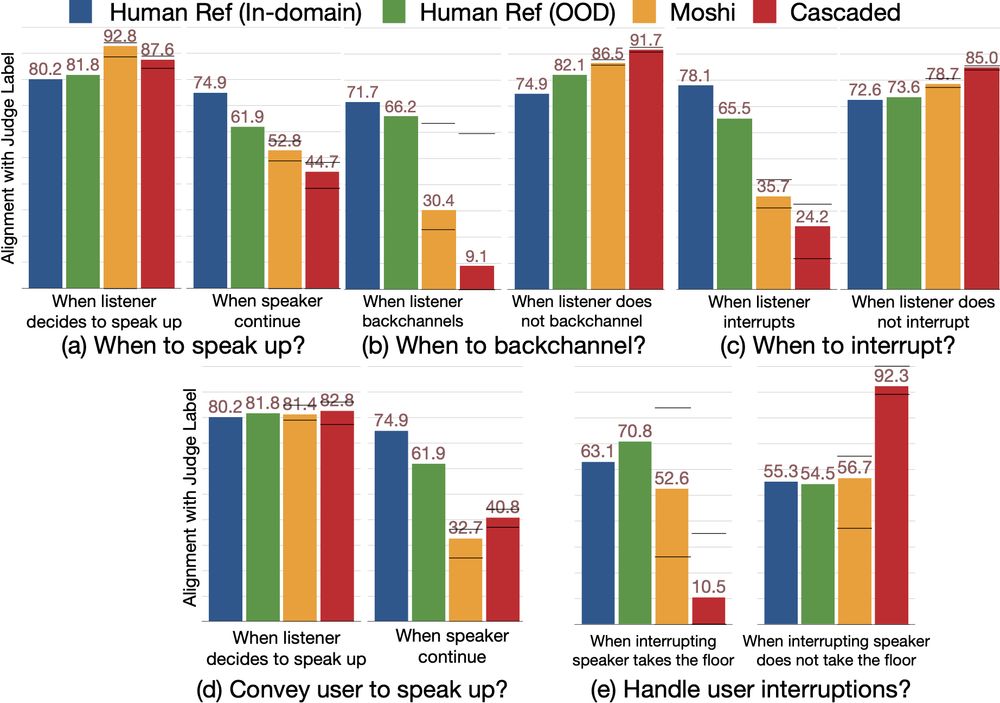
🤯 What did we find?
❌ Both systems fails to speak up when they should and do not give user enough cues when they wants to keep conversation floor.
❌ Moshi interrupt too aggressively.
❌ Both systems rarely backchannel.
❌ User interruptions are poorly managed.
(7/9)
05.03.2025 16:03 — 👍 0 🔁 0 💬 1 📌 0
We train a causal judge model on real human-human conversations that predicts turn-taking events. ⚡
Strong OOD generalization -> a reliable proxy for human judgment!
No need for costly human judgments—our model judges the timing of turn taking events automatically!
(6/9)
05.03.2025 16:03 — 👍 0 🔁 0 💬 1 📌 0
Global metrics fails to evaluate when turn taking event happens!
Moshi generates overlapping speech—but is it helpful or disruptive to the natural flow of the conversation? 🤔
(5/9)
05.03.2025 16:03 — 👍 0 🔁 0 💬 1 📌 0
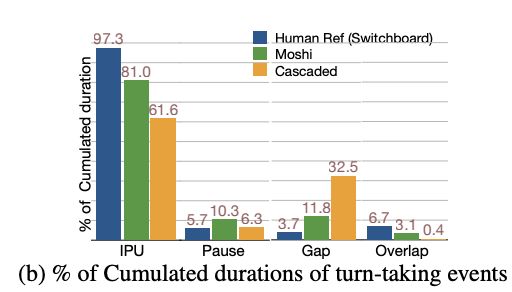
We compare E2E (Moshi us.moshi.chat) & cascaded (github.com/huggingface/...) dialogue systems through user study with global corpus level statistics!
Moshi: small gaps, some overlap—but less than natural dialogue
Cascaded: higher latency, minimal overlap.
(4/9)
05.03.2025 16:03 — 👍 0 🔁 0 💬 1 📌 0
Silence ≠ turn-switching cue! 🚫 Pauses are often longer than gaps in real conversations. 🤦♂️
Recent audio FMs claim to have conversational abilities but limited efforts to evaluate these models on their turn taking capabilities.
(3/9)
05.03.2025 16:03 — 👍 0 🔁 0 💬 1 📌 0
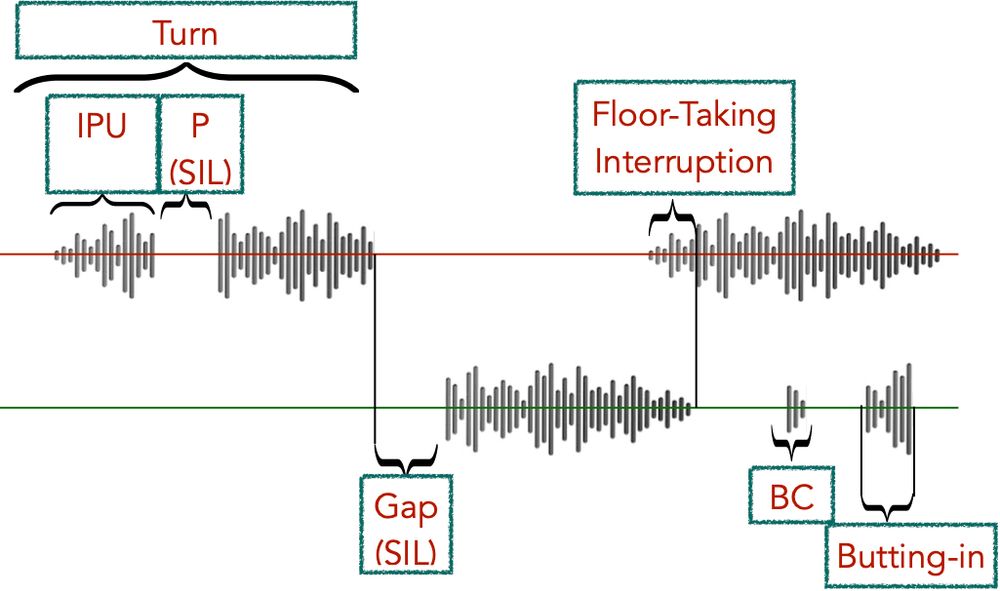
💡 Why does turn-taking matter?
In human dialogue, we listen, speak, and backchannel in real-time.
Similarly the AI should know when to listen, speak, backchannel, interrupt, convey to the user when it wants to keep the conversation floor and address user interruptions
(2/9)
05.03.2025 16:03 — 👍 0 🔁 0 💬 1 📌 0
🚀 New #ICLR2025 Paper Alert! 🚀
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: arxiv.org/abs/2503.01174
05.03.2025 16:03 — 👍 9 🔁 6 💬 1 📌 0
Master's student @ltiatcmu.bsky.social, working on speech AI at @shinjiw.bsky.social
PhD Student @CMU, Speech AI Research
https://pyf98.github.io/
PhD student WAVLab@LTI, CMU
Multimodality and multilinguality
prev. predoc Google Deepmind
PhD student at CMU LTI; Interested in pragmatics and cross-cultural understanding;
intern @ Allen Institute for AI |Prev: Senior Research Engineer @ Samsung Research America | Masters @ Stanford
https://akhila-yerukola.github.io/
PhD Student @ltiatcmu.bsky.social. Working on reasoning, code-gen agents and test-time compute.
PhD student @ltiatcmu.bsky.social. Working on NLP that centers worker agency. Otherwise: coffee, fly fishing, and keeping peach pits around, for...some reason
https://siree.sh
official Bluesky account (check username👆)
Bugs, feature requests, feedback: support@bsky.app