
read the full paper: https://arxiv.org/abs/2502.12996
@huggingface page: https://huggingface.co/papers/2502.12996
congrats to my collaborators @SatyenKale who led that work and Yani Donchev

@douillard.bsky.social
distributed (diloco) + modularity (dipaco) + llm @ deepmind | continual learning phd @ sorbonne
read the full paper: https://arxiv.org/abs/2502.12996
@huggingface page: https://huggingface.co/papers/2502.12996
congrats to my collaborators @SatyenKale who led that work and Yani Donchev

required bandwidth reduction is massive, for a 100B params model:
DP requires 471 Gbits/s
Streaming DiLoCo with inner com. overlap: 1.4 Gbits/s
Streaming DiLoCo with eager outer com. overlap: 400Mbits/s, more than 1000x reduction
400Mbits/s is consumer-grade bandwidth FYI
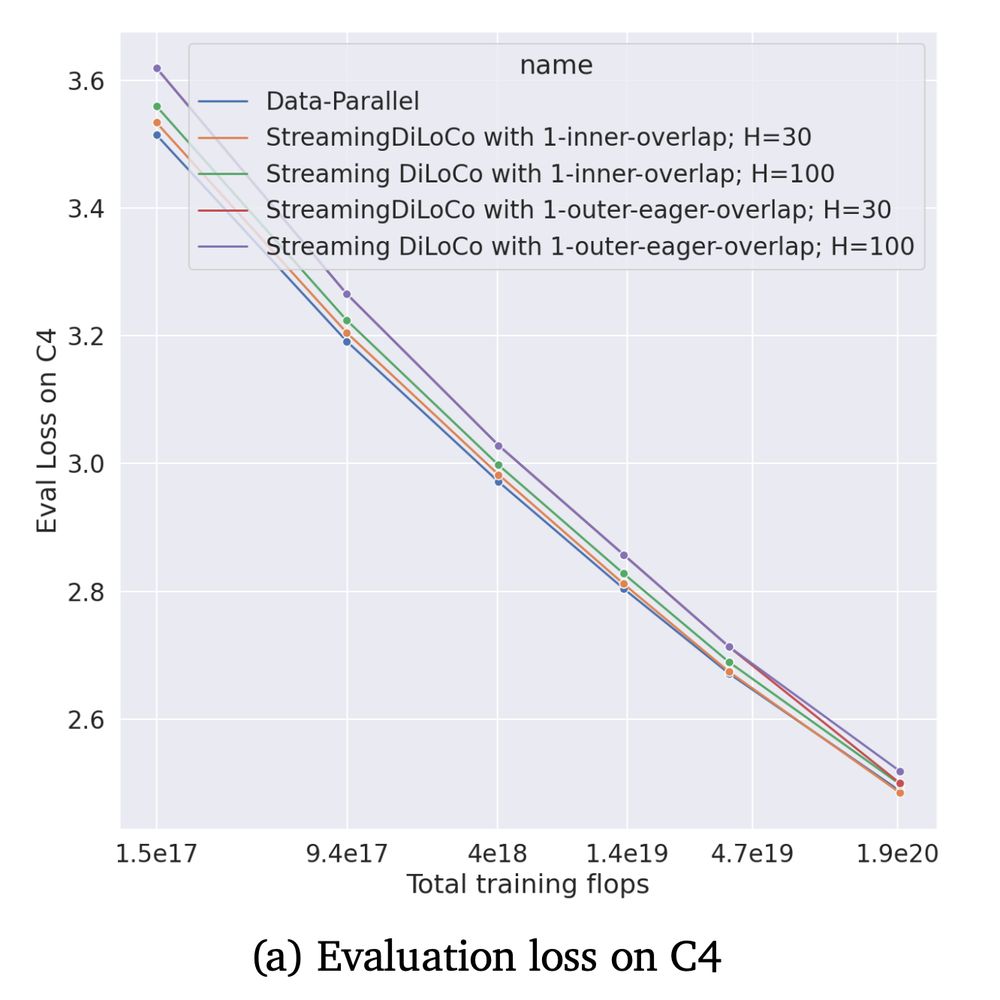
scaling up to 1B params, and we see that our eager method can reach no loss of performance when synchronizing every 30 steps (thus overlapping 30 computation steps!), and follow closely when overlapping 100 steps
19.02.2025 17:41 — 👍 0 🔁 0 💬 1 📌 0
thus we propose an *eager* version:
the update is made of the average of the *local up-to-date* update of the self replica and the *remote stale* update from the other replicas

but its performance are dramatically bad.
we can recover a bit by lowering the outer learning by 4x, but this is still unsatisfying

in this work, we explore if we can overlap an entire outer step, made of dozen to hundred of computation steps!
we first try a naive "delayed" version
Streaming DiLoCo's second contribution is to overlap communication with computation, massively increasing the tolerable latency
we can safely overlap up to 5 steps, but more than that and performance drops rapidly!
https://x.com/Ar_Douillard/status/1885292127678021751
DiLoCo allows us to distributed data-parallel across the world by only synchronizing once in a while, thus amortizing the communication cost
however, when syncing, this is a blocking operation!
https://x.com/Ar_Douillard/status/1724732329740976187

arxiv is here: https://arxiv.org/abs/2502.12996
read more below!


one more step towards decentralized learning: Eager Updates
can we overlap communication with computation over hundred of steps?
-- yes we can
in this work led by @SatyenKale, we improve DiLoCo and use x1177 less bandwidth than data-parallel
from Jeff Dean at The Dwarkesh podcast:
"asynchronous training where each copy of the model does local computation [...] it makes people uncomfortable [...] but it actually works"
yep, i can confirm, it does work for real
see arxiv.org/abs/2501.18512
We received an outstanding interest in our #ICLR2025 @iclr-conf.bsky.social workshop on modularity! Please sign up to serve as a reviewer if you are interested in Model Merging, MoEs, and Routing, for Decentralized and Collaborative Learning t.co/HIsZKWNaOx
14.02.2025 14:08 — 👍 1 🔁 1 💬 0 📌 0
I'll be in SF in two weeks to talk at the AlgoPerf workshop, and i have a bunch of stickers to give, so let me know if you want to meet!
31.01.2025 13:35 — 👍 1 🔁 0 💬 0 📌 0Big thanks to all my collaborators!
We finished this last spring, and it was one of the coolest project i've been on.
The future will be distributed 🫡
https://arxiv.org/abs/2501.18512v1
All of this is why we say Streaming DiLoCo is a good step towards distributed free lunch 🥪
So so many ideas we try just work on top of DiLoCo. And it can scale too! Look at the cracked folks of @PrimeIntellect who scaled their version to 10B
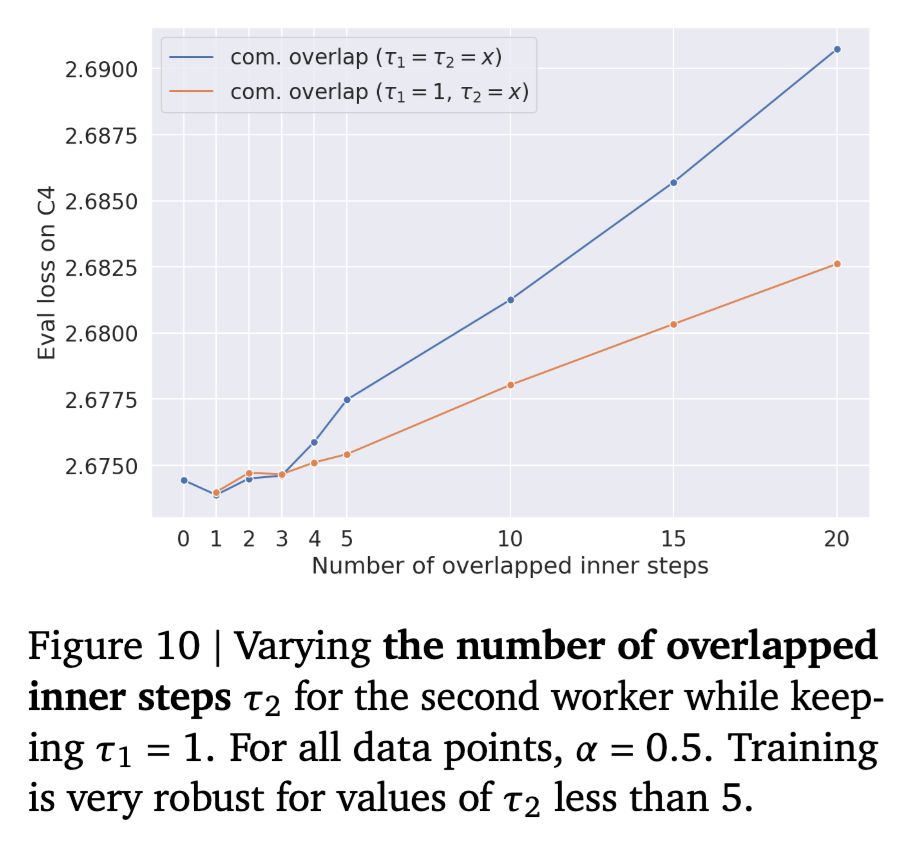
What if each replica overlap a different num of steps (\tau) because they run a different speeds?
Can we break away from the lockstep synchronization? yes!
Workers can have a few delay steps, and it just work, w/o any special handling.

There are tons of plots, tables, and charts in our paper; but let me share two more exciting plots:
Over how many steps can you overlap safely communication?
At least 5 without any significant loss of perf! That's a massive increase of tolerated latency.

Likewise, with a Llama with 405B parameters.
31.01.2025 13:35 — 👍 0 🔁 0 💬 1 📌 0
Speaking about DeepSeek, how to distribute its pretraining across the world with low-bandwidth?
It has only 35B activated params, but you need to sync 671B params in total! Hard to do across continents with data-parallel...
However, with our method? ❤️🔥

Indeed, post-training RL reasoning is easier to distribute (good post here primeintellect.ai/blog/intellect-math ) than pretraining
but we need to scale more our pretraining, this is still a relevant axis!
DeepSeek-R1 also notes it:

Of course the number displayed in that table are from a "simulation", but it's a pretty good indicator to what we find in practice.
Abolish the tyranny of requiring huge bandwidth! ✊
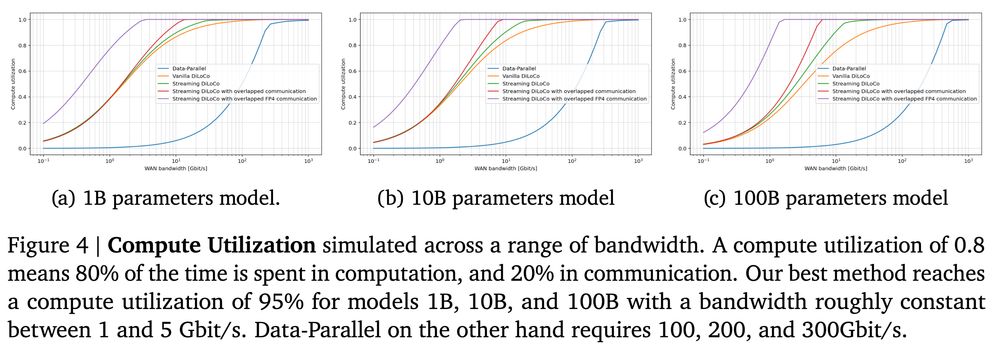
The good part of overlapping communication with computation?
As @m_ryabinin noted in Swarm Parallelism: larger networks spent more time doing computation O(n^3) vs doing communication O(n^2).
We have much more time to sync at larger scales!

My co-author, Yani, built a simulator: a DAG with fwd, bwd, and gradient reduction nodes.
It estimates how much time is spent in the costly com. between non-colocated devices and how much is spent crunching flops.

Put everything together, scale it to 4B, and reach similar performance than data-parallel.
It's even better when overtraining with a larger token budget? remember the bitter lesson? just put more data and flops in your model, Streaming DiLoCo enables that.

[3] You don't need full precision for your communication.
Quantize your update with 4 bits is enough -- you can barely see any changes on the performance.
And that's the free dessert 🍦

[2] Instead of blocking computation to receive the communication, we do several compute steps asynchronously.
See L9-12: the longer your model takes to do fwd/bwd, the more time you have to do communication!
That's the free main course 🍱

[1] Instead of syncing the whole model every hundreds of steps, sync a subset of it!
We split the model in fragments of three layers, it reduces massively the peak bandwidth w/o hurting ML performance.
That's the free appetizer 🥗

With Streaming DiLoCo, we improve over the successful recipe of DiLoCo in three ways:
1. partial synchronization
2. communication overlapping with computation
3. quantized communication
This is a distributed free lunch 🥪

Problem: in data-parallel's every step synchronization, communication is costly!
DiLoCo (arxiv.org/abs/2311.08105 ) synchronizes less often --> amortizing the cost
Later, @PrimeIntellect released Intellect-1, a repro of DiLoCo, with a 10B model! arxiv.org/abs/2412.01152

PrimeIntellect's OpenDiLoCo, an open-source reproduction of DiLoCo, where compute is distributed across the world.
The bitter lesson is that neural networks *really* want more flops and data. This has been the key success behind LLMs. It also means you need tons of compute.
however it's hard to have all that compute available in a single place, can we distribute it across the world?




















