We believe that leveraging EC-Diffuser’s state generation capability for planning is a promising avenue for future work.
This is a joint work with an amazing team: Carl Qi, Dan Haramati, Tal Daniel, Aviv Tamar, and Amy Zhang.
19.02.2025 16:16 — 👍 0 🔁 0 💬 0 📌 0

We also trained EC-Diffuser on the real world Language-Table dataset and showed it can also produce high-quality real world rollouts. This demonstrates that the model implicitly matches objects and enforces object consistency over time, aiding in predicting multi-object dynamics.
19.02.2025 16:16 — 👍 0 🔁 0 💬 1 📌 0
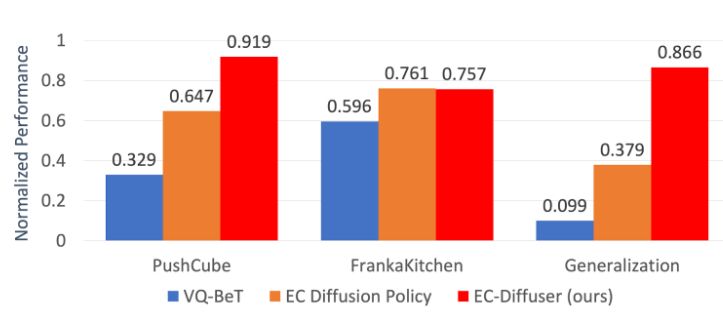
The result? EC-Diffuser outperforms baselines and achieves zero-shot generalization to novel object configurations—even scaling to more objects than seen during training. See more of the rollouts: sites.google.com/view/ec-diff...
19.02.2025 16:15 — 👍 0 🔁 0 💬 1 📌 0
It also enables the Transformer to denoise unordered object-centric particles and actions jointly, capturing multi-modal behavior distributions and complex inter-object dynamics.
19.02.2025 16:14 — 👍 0 🔁 0 💬 1 📌 0
Why diffusion? Since noise is added independently to each particle, a simple L1 loss is effective for particle-wise denoising—eliminating the need for complex set-based metrics.
19.02.2025 16:14 — 👍 0 🔁 0 💬 1 📌 0
Our model takes in a sequence of unordered state particles (from multi-view images) and actions. Conditioned on the current state and goal, it generates a denoised sequence of future states and actions that can be used for MPC-style control—by executing the first action.
19.02.2025 16:13 — 👍 0 🔁 0 💬 1 📌 0
We encode actions as a separate particle. This design allows our Transformer to treat actions and state particles in the same embedding space. We further condition the Transformer with the diffusion timestep and the action tokens via Adaptive layer normalization (AdaLN).
19.02.2025 16:13 — 👍 0 🔁 0 💬 1 📌 0
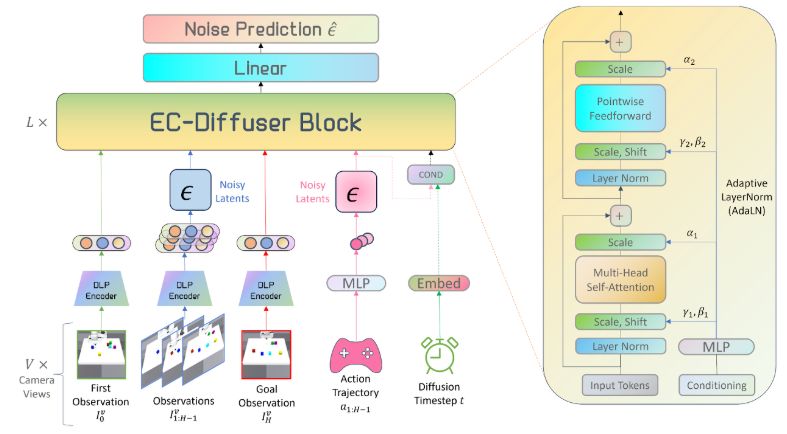
Our entity-centric Transformer is designed to process these unordered particle inputs with a permutation-equivariant architecture, computing self-attention over object-level features without positional embeddings.
19.02.2025 16:13 — 👍 0 🔁 0 💬 1 📌 0
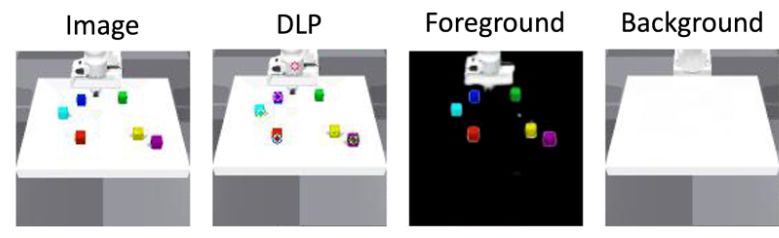
We begin by converting high-dimensional pixels into unsupervised object-centric representations using Deep Latent Particles (DLP). Each image is decomposed into an unordered set of latent “particles” from multiple views, capturing key object properties.
19.02.2025 16:12 — 👍 0 🔁 0 💬 1 📌 0
This work was led by Carl Qi!
Object manipulation from pixels is challenging: high-dimensional, unstructured data creates a combinatorial explosion in states & goals, making multi-object control hard. Traditional BC methods need massive data/compute and still miss the diverse behaviors required.
19.02.2025 16:11 — 👍 0 🔁 0 💬 1 📌 0
Check out our new #ICLR2025 paper: EC-Diffuser leverages a novel Transformer-based diffusion denoiser to learn goal-conditioned multi-object manipulation policy from pixels!👇
Paper: www.arxiv.org/abs/2412.18907
Project page: sites.google.com/view/ec-diff...
Code: github.com/carl-qi/EC-D...
19.02.2025 16:10 — 👍 2 🔁 1 💬 1 📌 1

If interested on our take on addressing inverse RL in large state spaces, go to meet @filippo_lazzati and @alberto_metelli in the poster session 5 #NeurIPS2024 today (paper -> arxiv.org/abs/2406.03812)
13.12.2024 14:33 — 👍 5 🔁 2 💬 1 📌 0
CS PhD student at Cornell University;
Interested in vision
https://haian-jin.github.io/
PhD candidate @polimi | Reinforcement Learning @rl3polimi | I do stuff, I see stuff. Some with purpose, most by chance.
https://ricczamboni.github.io
Professor, University of Tübingen @unituebingen.bsky.social.
Head of Department of Computer Science 🎓.
Faculty, Tübingen AI Center 🇩🇪 @tuebingen-ai.bsky.social.
ELLIS Fellow, Founding Board Member 🇪🇺 @ellis.eu.
CV 📷, ML 🧠, Self-Driving 🚗, NLP 🖺
computer vision + machine learning. Perception at Zoox. Prev: Cobot, PhD. Arxiv every day.
Researcher & faculty member @DPKM dedicated to the field of AI, with the focus on knowledge technologies (knowledge graphs, semweb, RAG) & their use in e-gov, skills matching, research ecosystem, digital humanities and education. Partner @km-a.bsky.social.
Pioneering the future of robotics since 1979. We’re transforming industries and everyday life through cutting-edge innovation & world-class education.
🌐 https://linktr.ee/cmuroboticsinstitute
TMLR Homepage: https://jmlr.org/tmlr/
TMLR Infinite Conference: https://tmlr.infinite-conf.org/
@PyTorch "My learning style is Horace twitter threads" -
@typedfemale
I work at Sakana AI 🐟🐠🐡 → @sakanaai.bsky.social
https://sakana.ai/careers
Advocate for tech that makes humans better | Spatial Computing, Holodeck, and AI Futurist | Ex-Microsoft, Rackspace | Co-author, "The Infinite Retina."
From SLAM to Spatial AI; Professor of Robot Vision, Imperial College London; Director of the Dyson Robotics Lab; Co-Founder of Slamcore. FREng, FRS.
Technical Lead on Accelerate @ Hugging Face | Passionate about Open Source | https://muellerzr.github.io
Prof (CS @Stanford), Co-Director @StanfordHAI, Cofounder/CEO @theworldlabs, CoFounder @ai4allorg #AI #computervision #robotics #AI-healthcare
Faculty Fellow and Assistant Professor at
NYU's Center of Data Science
Postdoc @ Brown DSI
VP R&D @ ClearMash
🔬 Passionate about high-fidelity numerical representations of reality, aligned with human perception.
https://omri.alphaxiv.io/
#nlp #multimodality #retrieval #hci #multi-agent
LLMs and ratings at lmarena.ai
Esports stuff for fun:
https://cthorrez.github.io/riix/riix.html
https://huggingface.co/datasets/EsportsBench/EsportsBench
Postdoc @csail.mit.edu, Ph.D. from @scai-asu.bsky.social
Working on AI Safety, AI Assessment, Automated Planning, Interpretability, Robotics
Previously: Masters from IITGuwahati, Research Intern at MetaAI
https://pulkitverma.net
Building tools for AI datasets. 😽
Looking in AI datasets. 🙀
Sharing clean open AI datasets. 😻
at https://bsky.app/profile/hf.co
AI and robotics researcher at Technion
avivt.github.io/avivt/
























