Enjoyed my first @interspeech.bsky.social conference. Seems like a great community. Well organized and great venue. This is how big conferences could look like. Take notes, ICASSP!
21.08.2025 08:18 — 👍 2 🔁 0 💬 0 📌 0
Now in Rotterdam at @interspeech.bsky.social with @cifkao.bsky.social and @hschreiber.bsky.social
17.08.2025 20:24 — 👍 0 🔁 0 💬 0 📌 0
Same here. With Claude 4, pandas becomes usable again but every time I tried torch models, all shapes are messed up. What I like though is that the AI agent often comes up with little clever helper bash scripts to test stuff (because it doesn’t understand the code base 😁)
11.07.2025 19:14 — 👍 1 🔁 0 💬 0 📌 0
Igniting Innovation: Evidence from PyTorch on Technology Control in Open Collaboration
<div>
Many companies offer free access to their technology to encourage outside add-on <span>innovation, hoping to later profit by raising prices or harne
Harvard Business on Open Source: When PyTorch left Meta for its own non-profit, "this shift led to a significant decrease in contributions from Meta but a notable increase from external companies...participation increased from complementors (Chip Manufacturers);" papers.ssrn.com/sol3/papers....
20.03.2025 21:08 — 👍 4 🔁 1 💬 0 📌 0

Internship: ML Optimization | Notion
Location: Paris preferred (remote within France/EU possible)
🚀 We’re looking for a Master’s student to join our research team for a 6-month internship at AudioShake!
Deep dive into PyTorch, optimize our SOTA audio models, and help make ML sound better (and faster) 🎶
Based in Paris or remote 🇫🇷 → audioshake.notion.site/Internship-M... #AudioML #Internship
25.06.2025 14:02 — 👍 1 🔁 3 💬 0 📌 0
Would I ever want to have the reviews written by LLMs? Hell, no!
27.05.2025 08:16 — 👍 1 🔁 0 💬 0 📌 0
I think they serve well as a guide of how to do reviews well. “Have you checked x?” I often find actual flaws that I would have missed otherwise. You don’t have to understand a paper to find flaws. Just think of: “we did x to improve y” - without backing it up by a citation.
27.05.2025 08:15 — 👍 0 🔁 0 💬 1 📌 0
Why? Isn’t the main point to identify flaws? I often found an LLM finds 10 flaws and only 1-2 of them are valid concerns. So yes this is dangerous if just used without human in the loop. But also often I find ideas what to check in detail based on the initial LLM summary.
27.05.2025 06:17 — 👍 0 🔁 0 💬 1 📌 0
Just wonder whether the reviewer demographics are something specific to your field. I review about 10-20 papers per year, I don’t get payed by the public and looking at our main conferences like ICASSP it looks like (no numbers) at least half of the reviewers do have an industry position.
27.05.2025 06:14 — 👍 0 🔁 0 💬 0 📌 0
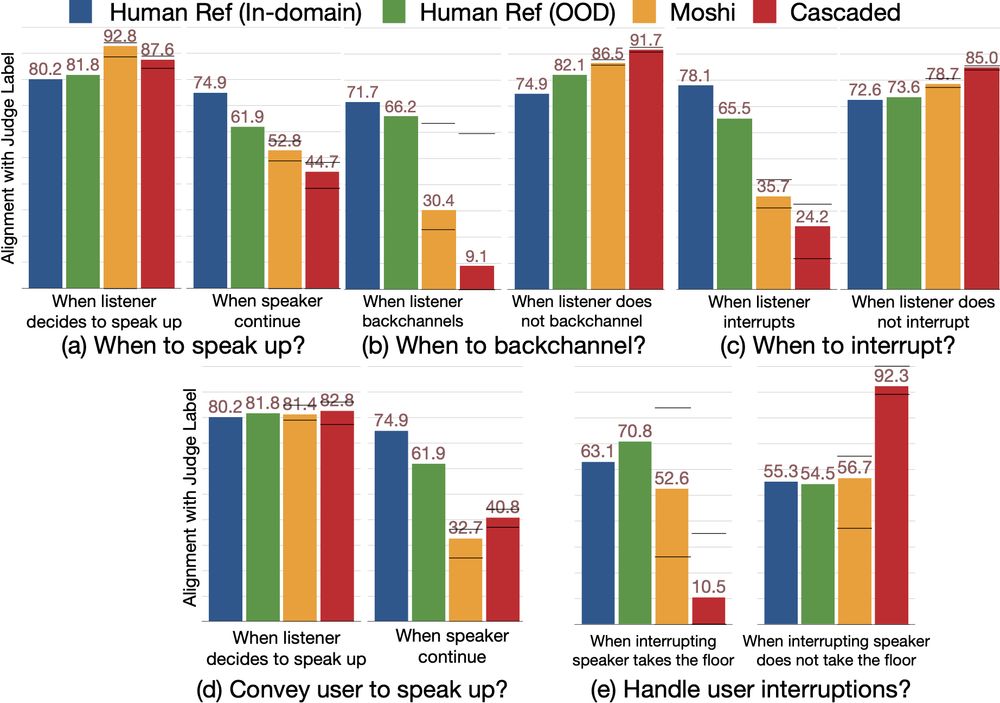
🚀 New #ICLR2025 Paper Alert! 🚀
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: arxiv.org/abs/2503.01174
05.03.2025 16:03 — 👍 9 🔁 6 💬 1 📌 0
true. But it thought IEEE owns the idea of paying much more and getting much less than at other conferences :-)
21.05.2025 12:24 — 👍 2 🔁 0 💬 0 📌 0

@interspeech.bsky.social new to the speech community coming from ISMIR/ICASSP/Eusipco/DAFX. How come Interspeech is that much more expensive than other conferences? This makes it very hard for many researchers to get approval!
20.05.2025 19:03 — 👍 1 🔁 0 💬 1 📌 0
@fakufaku.bsky.social can I do this with pyroomacoustics? Or do you know a simpler idea?
04.04.2025 13:21 — 👍 0 🔁 0 💬 0 📌 0
Not knowing much about spatial audio: how do people render multiple dry mono sources to a wet reverberated stereo image where each source has a fixed position in space? I guess one could use ambisonics RiRs to create stereo images? But whats the easier way to handle the positioning?
04.04.2025 13:18 — 👍 0 🔁 0 💬 1 📌 0

AudioShake’s Multi-Speaker Separation is the first-ever hi-res solution for isolating overlapping voices. Perfect for media pros, transcription, & AI voice workflows. 🔗www.audioshake.ai/post/introducing-multi-speaker-separation-from-audioshake
05.03.2025 18:58 — 👍 5 🔁 4 💬 0 📌 0

AudioShake Isolations Bring Maria Callas’ Voice to Life in Netflix film, “Maria”
Filmmakers and Warner Classics in partnership with the Maria Callas Estate, used AudioShake’s stem separation to isolate her voice to perfect the biopic’s music
How stem separation tech brought the legendary voice of Maria Callas back to life in “Maria". 🎶 Isolating Callas’s original vocals allowed @warnerclassics.bsky.social and filmmakers to control and blend her voice with Jolie’s performance. 🔗 Read: www.audioshake.ai/post/audiosh...
13.02.2025 20:41 — 👍 7 🔁 2 💬 0 📌 0
We just released the Helium-1 model , a 2B multi-lingual LLM which @exgrv.bsky.social and @lmazare.bsky.social have been crafting for us! Best model so far under 2.17B params on multi-lingual benchmarks 🇬🇧🇮🇹🇪🇸🇵🇹🇫🇷🇩🇪
On HF, under CC-BY licence: huggingface.co/kyutai/heliu...
13.01.2025 18:10 — 👍 25 🔁 8 💬 0 📌 0

Today, we’re introducing NatureLM-audio: the first large audio-language model tailored for understanding animal sounds. arxiv.org/abs/2411.07186 🧵👇
05.12.2024 00:45 — 👍 15 🔁 8 💬 2 📌 4
Where is AGI that charges all my devices and batteries?
27.12.2024 19:47 — 👍 0 🔁 0 💬 0 📌 0

utter-project/mHuBERT-147 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Since this is a new platform and mHuBERT-147 just reached 86k downloads, let me make some promotion!
This year we released a compact powerful multilingual SSL model. Trained on balanced, high-quality, open-license data, this model rivals MMS-1B but is 10x smaller.
huggingface.co/utter-projec...
21.11.2024 15:43 — 👍 15 🔁 3 💬 2 📌 0
Looking for reviewers before Christmas
11.12.2024 05:25 — 👍 676 🔁 89 💬 11 📌 23

interspeech2025.org challenge URGENT Organizers: Kohei Saijo, Wangyou Zhang, Samuele Cornell, Robin Scheibler, Chenda Li, Zhaoheng Ni, Anurag Kumar, Marvin Sach, Yihui Fu, Wei Wang, Tim Fingscheidt, Shinji Watanabe
🌟 URGENT Challenge @ #Interspeech2025 🌟
Join the Universal, Robust, & Generalizable Speech EnhancemeNT (URGENT) challenge! Explore noisy corpora, tackle diverse speech degradations, and test scalability across 2 tracks (~2.5k/60k hrs).
🚀 Learn more: urgent-challenge.github.io/urgent2025/
06.12.2024 12:36 — 👍 6 🔁 4 💬 0 📌 0
new paper! 🗣️Sketch2Sound💥
Sketch2Sound can create sounds from sonic imitations (i.e., a vocal imitation or a reference sound) via interpretable, time-varying control signals.
paper: arxiv.org/abs/2412.08550
web: hugofloresgarcia.art/sketch2sound
12.12.2024 14:43 — 👍 23 🔁 9 💬 2 📌 5
📢 Audio AI Job opportunity at Adobe!
The Sound Design AI Group (SODA) is looking for an exceptional research engineer to join us in building the future of AI-assisted audio and video creation.
Strong ML background, GenAI experience a plus.
Details: adobe.wd5.myworkdayjobs.com/external_exp...
09.12.2024 19:00 — 👍 11 🔁 3 💬 1 📌 3

DeepMind
🚨🚨My team @GoogleDeepMind in Tokyo is looking for a talented research scientist to work on audio generative models! 🔊
Please consider applying if you have expertise in the domain or related areas such as multimodal models, video generation 📹, etc.
boards.greenhouse.io/deepmind/job...
06.12.2024 07:09 — 👍 4 🔁 4 💬 0 📌 0
🎓Academia or the industry 💸? I wrote a detailed point of view on Twitter a few months ago, so maybe I should share it here again. I think that most things are still true, the only slight change would be linked to the GenAI bubble, but only time will tell.
www.darnault-parcollet.fr/documents/Ba...
01.12.2024 09:03 — 👍 4 🔁 1 💬 0 📌 0
“My AI startups is just a GPT Wrapper”
The Reality for AI Startups
01.12.2024 00:59 — 👍 139 🔁 23 💬 5 📌 0
mit Dir ist alles blauer 🥰
30.11.2024 20:35 — 👍 2 🔁 0 💬 0 📌 0
interspeech2026.org
27 September – 1 October, ICC, Sydney, Australia
'Speaking Together'
Proudly hosted by the Australasian Speech Science and Technology Association (ASSTA) and the International Speech Communication Association (ISCA).
Music Technologist. Software engineer at Ableton, lead developer of iPlug2 framework. Maker of VirtualCZ and Endless Series plug-ins.
AI @ OpenAI, Tesla, Stanford
Audio Signal Processing PhD @ UNSW, Sydney, Australia
Research Leader @ Sony CSL Paris
PhD in Music Information Retrieval @TélécomParis. https://morgan76.github.io/
I split sound at AudioShake. I write stories on paper. And I really like candy.
Audio Machine Learning and Signal Processing.
NYU / Georgia Tech.
universal musical approximator. research scientist at gorgle derpmind, magenta team. https://ethman.github.io
LLM @kyutai-labs.bsky.social
Studying genomics, machine learning, and fruit. My code is like our genomes -- most of it is junk.
Assistant Professor UMass Chan
Previously IMP Vienna, Stanford Genetics, UW CSE.
The new frontier of interspecies understanding.
We decode animal communication with advanced AI to illuminate the diverse intelligences on earth.
www.earthspecies.org/























