Michael X Cohen on why he left academia/neuroscience.
mikexcohen.substack.com/p/why-i-left...

@kokiikeda.bsky.social
Research fellow at Meiji Gakuin University in Tokyo. https://sites.google.com/view/dlpsychology/home
Michael X Cohen on why he left academia/neuroscience.
mikexcohen.substack.com/p/why-i-left...

Intervening on a central node in a network likely does little given that its connected neighbors will "flip it back" immediately. Happy to see this position supported now.
"Change is most likely [..] if it spreads first among relatively poorly connected nodes."
www.nature.com/articles/s41...

NEW: California could soon enact the most significant protections for AI companions in the U.S. Debate over two bills, AB1064 & SB243, has sparked a major lobbying blitz as tech industry groups and consumer advocates vie to shape the rules www.techpolicy.press/inside-the-l... tip @techmeme.com
23.09.2025 14:14 — 👍 5 🔁 2 💬 1 📌 3Great thread. One of the subtler things that seems to go missing here is that you can’t use typical statistics on silicon samples… because they’re not samples with reference to a population.
Also you can arbitrarily select N and guarantee significance.

Can large language models stand in for human participants?
Many social scientists seem to think so, and are already using "silicon samples" in research.
One problem: depending on the analytic decisions made, you can basically get these samples to show any effect you want.
THREAD 🧵




Claude, "We all know among Sauron's many evils was that he ran Mordor using an Excel spreadsheet with multiple tabs. Show me the spreadsheet"
It made 12 tabs "so bureaucratically complex that even the Eye of Sauron would need reading glasses to review it." Some very funny stuff. Creative, even.

In a new paper, my colleagues and I set out to demonstrate how method biases can create spurious findings in relationship science, by using a seemingly meaningless scale (e.g., "My relationship has very good Saturn") to predict relationship outcomes. journals.sagepub.com/doi/10.1177/...
10.09.2025 18:18 — 👍 158 🔁 69 💬 7 📌 11
Workflows for agentic coding (and the limits of vibe coding) russpoldrack.substack.com/p/workflows-... - the latest in my Better Code, Better Science series
09.09.2025 15:07 — 👍 10 🔁 3 💬 0 📌 0We're experiencing an unbelievable deluge of submissions. At our journal we got ~200 per year in 2020. Last year it was 600. This year it's 800 with several months to go. So that's why we're slower to get stuff out for review.
06.09.2025 23:09 — 👍 450 🔁 43 💬 5 📌 18At long last, I can post my team's summer project: applied modules to teach how ML/AI tools are changing social science and humanities research: ubcecon.github.io/praxis-ubc/
Highlights:
LegalBERT to analyze anti/pro-immigrant sentiment in 19th c. BC law: ubcecon.github.io/praxis-ubc/d...
🧵1

Perhaps still the best general purpose explainer of how an LLM works and the one I give to students. Here’s why I like it (short🧵): ig.ft.com/generative-ai/
05.09.2025 18:16 — 👍 113 🔁 43 💬 13 📌 2
We are about a month away from releasing a complete refresh of the OSF user interface. The team has been working on this for a very long time, and we are very excited to be able to share it soon. A preview picture:
04.09.2025 21:57 — 👍 149 🔁 31 💬 10 📌 3
(AI generated) “Event poster: ‘Deep Learning and Psychology 3 — Advancing Persuasion-AI Research.’ Large green number 3 with network motif on a black background, Japanese text listing organizers/speakers, a QR code, and details: Sept 7, 2025, 15:50–17:30, Venue 2 (L401), Japanese Psychological Association 89th Annual Convention.”
今週末 9/7 (日) に、日本心理学会で「深層学習と心理学3:説得 AI 研究の展開」というシンポジウムを開催します。詳細は以下をご覧ください。
sites.google.com/view/dlpsych...
Regardless of whether current AI Labs fail (and there is no indication they are at risk today) & even if AI development stops (more unlikely), things will keep getting weirder: today's models are good enough for long-term disruption, and the weights & inference infrastructure aren't going away.
31.08.2025 18:00 — 👍 66 🔁 5 💬 5 📌 1Just made a manuscript/PAP feedback GPT built from 150+ previous peer reviews - identifies problems and provides actionable feedback on the points that I raise most frequently
chatgpt.com/g/g-68af4d19...
Anyone can use - try it out! (Editors/authors: feel free to cut me out of the loop 😉.)
Due to a recent influx of problematic submissions, PsyArXiv has switched to pre-moderating its content. If your submitted preprint had not yet been approved, it will be temporarily inaccessible to the public (you can still view your preprint when logged into your OSF account). #PsychSciSky
19.08.2025 16:58 — 👍 59 🔁 26 💬 7 📌 14
9.2% of all citations go to just 0.32% of psychology articles.
To have the most impact, post-publication peer-review should focus on these influential articles with ≥30 citations per year.
@error.reviews will systemically sample from such articles.
Blog post:
mmmdata.io/posts/2025/0...




Important work from @dgrand.bsky.social looking at political persuasion from generative AI
Good news/bad news: it worked. “Friendliness” and use of facts seemed to be primary drivers #pacss2025 #polnet2025
Suddenly retiring every other model without warning was a weird move by OpenAI
… and they did it without explaining how switching models worked or even details of various GPT-5 models
…and they did it after many built workflows & training & assignments around older models, maybe breaking them. Odd
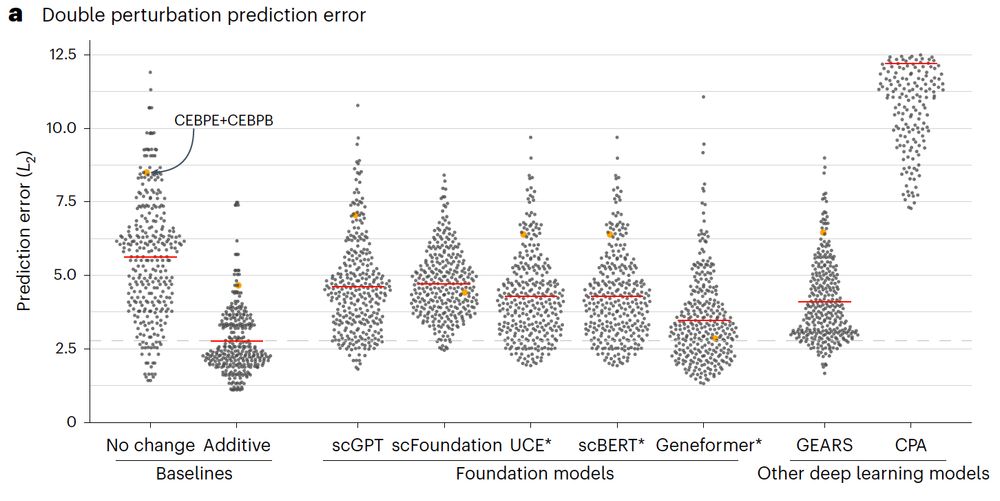
Beeswarm plot of the prediction error across different methods of double perturbations showing that all methods (scGPT, scFoundation, UCE, scBERT, Geneformer, GEARS, and CPA) perform worse than the additive baseline.
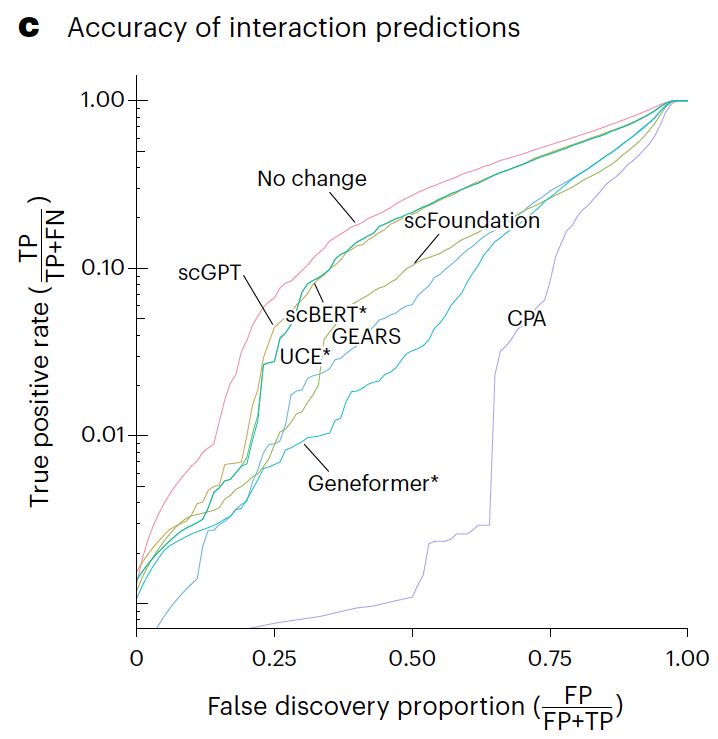
Line plot of the true positive rate against the false discovery proportion showing that none of the methods is better at finding non additive interactions than simply predicting no change.
Our paper benchmarking foundation models for perturbation effect prediction is finally published 🎉🥳🎉
www.nature.com/articles/s41...
We show that none of the available* models outperform simple linear baselines. Since the original preprint, we added more methods, metrics, and prettier figures!
🧵

This report about the ISQOLS conference in Luxembourg by @markfabian.bsky.social is a good read. Especially fascinating about the changing of the guard and some of the elders of the field sounding like a broken record. Also congrats to Mark on the Young Scholar Award (you’re senior to me!).
02.08.2025 09:09 — 👍 11 🔁 4 💬 3 📌 1
AI Ethics Literacy | A growing need, a growing list of issues, and a growing collection of resources from the Markkula Center for Applied Ethics | This is a great resource! www.scu.edu/ethics/focus...
31.07.2025 23:04 — 👍 4 🔁 1 💬 1 📌 0
How many chips are in a bag of chips? Measurement and conceptualization can lead to radically different outcomes. www.nature.com/articles/s44... @justanormaldino.bsky.social
31.07.2025 07:33 — 👍 7 🔁 3 💬 1 📌 2Kinda wow: the mystery model "summit" (rumored to be OpenAI) with the prompt "create something I can paste into p5js that will startle me with its cleverness in creating something that invokes the control panel of a starship in the distant future" & "make it better"
2,351 lines of code. First time
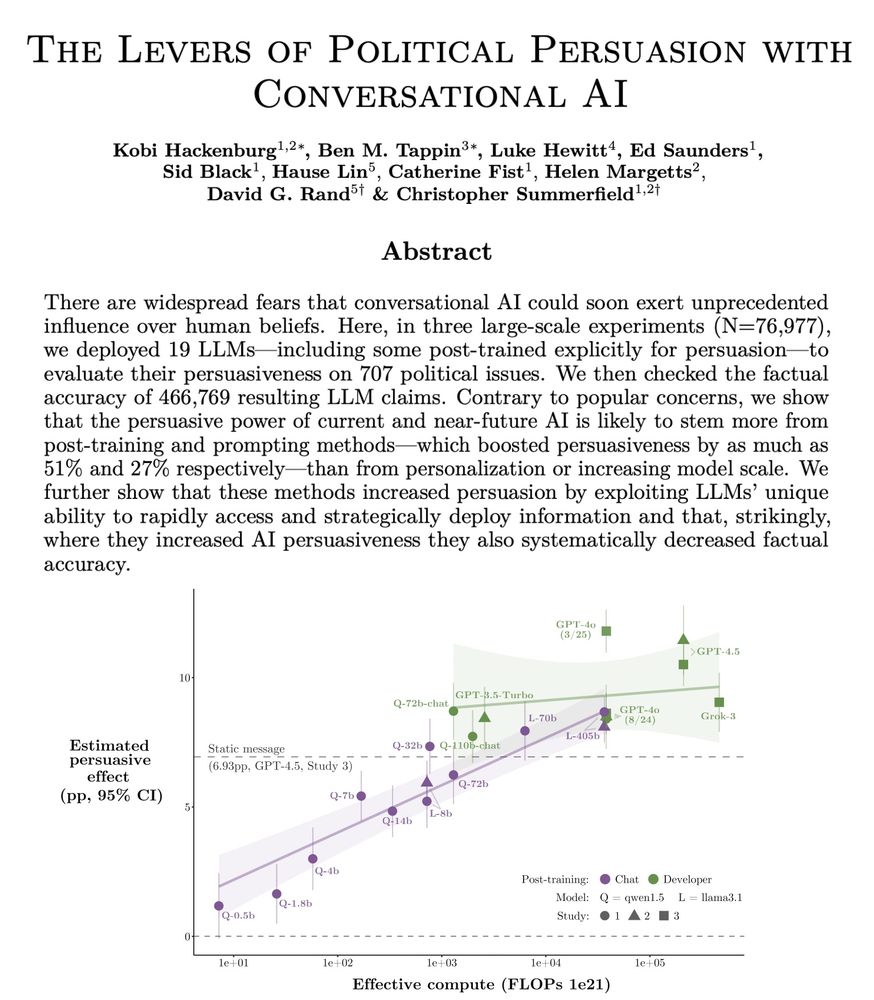
Today (w/ @ox.ac.uk @stanford @MIT @LSE) we’re sharing the results of the largest AI persuasion experiments to date: 76k participants, 19 LLMs, 707 political issues.
We examine “levers” of AI persuasion: model scale, post-training, prompting, personalization, & more!
🧵:
Been really enjoying the Complexity Science Discussion Group hosted by Paul Middlebrooks, where we're working our way through the Santa Fe Institute's "Classic Papers in Complexity Science". The group is open for anyone interested:
braininspired.co/complexity-g...
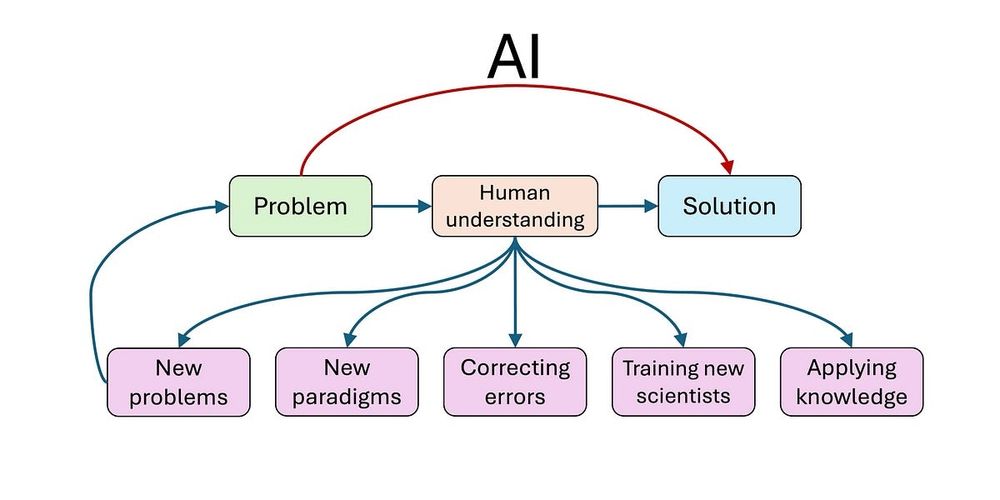
Fabulous post by @randomwalker.bsky.social & Sayash raising the same concern many of us have about whether we're on the right track with how we're using AI for science. Everyone should read it, take a deep breath & think through the implications.
www.aisnakeoil.com/p/could-ai-s...
Such a useful framing (which I first heard from @alexanderhoyle.bsky.social). The prompt is ultimately just a bunch of numbers that we input to the model, and why we should prefer one set of numbers over another set is hard to answer, as we can’t search the space the way we normally would in ML.
16.07.2025 16:27 — 👍 56 🔁 8 💬 9 📌 2
Screenshot of the first page of a journal article titled "Developmental Channeling and Evolutionary Dappling" by Grant Ramsey and Cristina Villegas, published in Philosophy of Science (2024), Volume 91, pages 869–886. The page includes logos of the Philosophy of Science Association and the journal Philosophy of Science.
How does #development steer #evolution? Through 'developmental channeling'—organisms’ dispositions to develop in some ways, not others—yielding 'evolutionary dappling,' where only parts of the morphospace get filled. Check out our recent 📃👇 www.cambridge.org/core/journal... #evodevo #philsci #HPbio
16.07.2025 12:23 — 👍 25 🔁 8 💬 0 📌 0I used Veo 3 to solve Shakespearean tragedies as pictured in classical art. (sound on)
09.07.2025 21:38 — 👍 149 🔁 28 💬 12 📌 2