This is joint work with wonderful collaborators @leenacvankadara.bsky.social , @cevherlions.bsky.social and Jin Xu during our time at Amazon.
🧵 10/10
10.12.2024 07:08 — 👍 3 🔁 1 💬 0 📌 0
How achieve correct scaling with arbitrary gradient-based perturbation rules? 🤔
✨In 𝝁P, scale perturbations like updates in every layer.✨
💡Gradients and incoming activations generally scale LLN-like, as they are correlated.
➡️ Perturbations and updates have similar scaling properties.
🧵 9/10
10.12.2024 07:08 — 👍 2 🔁 0 💬 1 📌 0

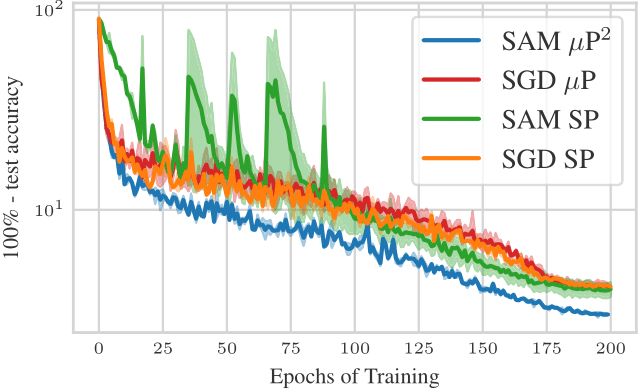
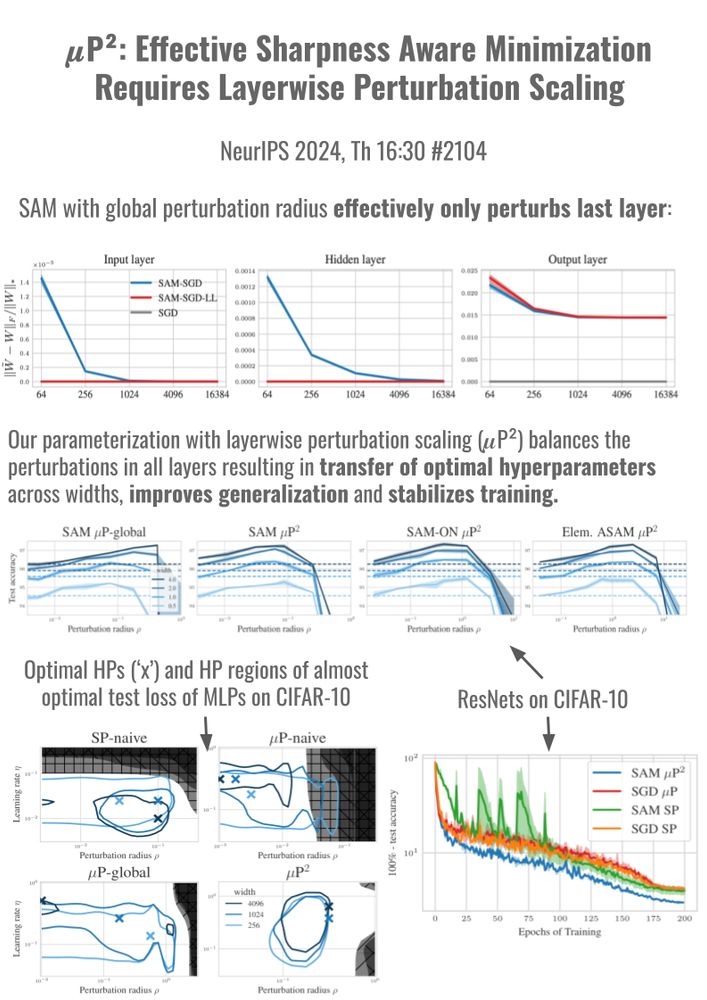
In experiments across MLPs and ResNets on CIFAR10 and ViTs on ImageNet1K, we show that 𝝁P² indeed jointly transfers optimal learning rate and perturbation radius across model scales and can improve training stability and generalization.
🧵 8/10
10.12.2024 07:08 — 👍 3 🔁 0 💬 1 📌 0
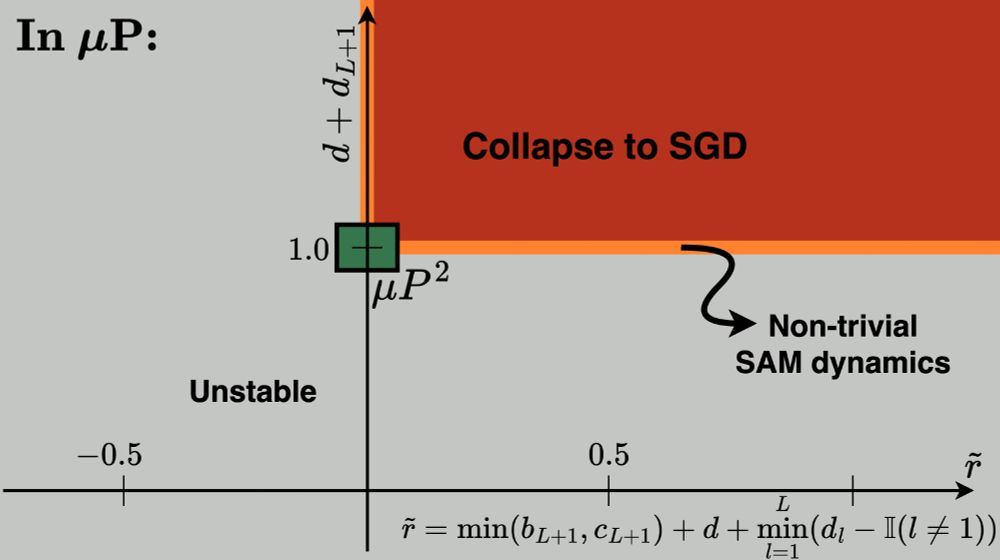
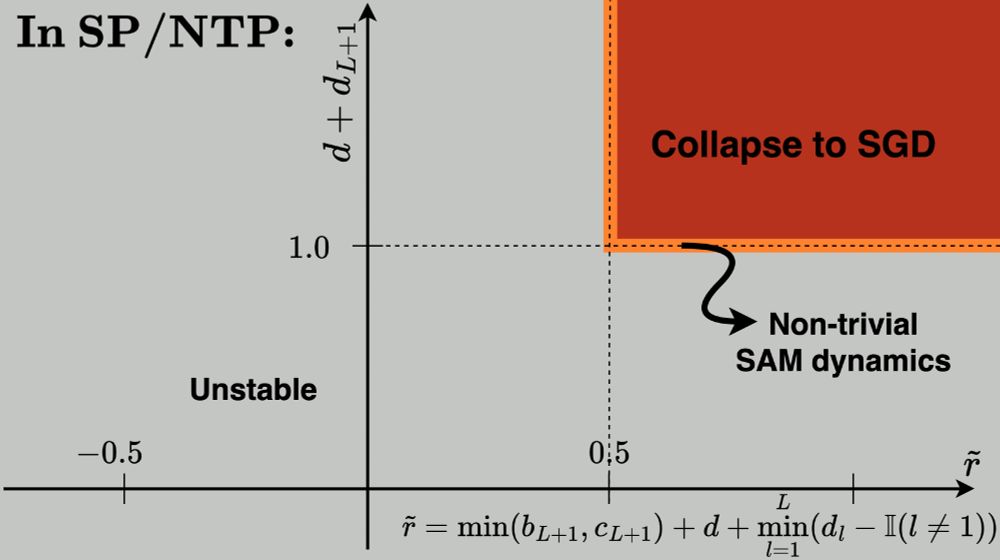
... there exists a ✨unique✨ parameterization with layerwise perturbation scaling that fulfills all of our constraints:
(1) stability,
(2) feature learning in all layers,
(3) effective perturbations in all layers.
We call it the ✨Maximal Update and Perturbation Parameterization (𝝁P²)✨.
🧵 7/10
10.12.2024 07:08 — 👍 2 🔁 0 💬 1 📌 0
Hence, we study arbitrary layerwise learning rate, initialization variance and perturbation scaling.
For us, an ideal parametrization should fulfill: updates and perturbations of all weights should have a non-vanishing and non-exploding effect on the output function. 💡
We show that ...
🧵 6/10
10.12.2024 07:08 — 👍 1 🔁 0 💬 1 📌 0
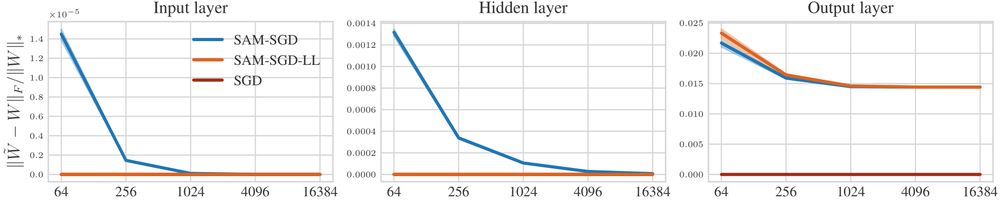
... we show that 𝝁P is not able to consistently improve generalization or to transfer SAM's perturbation radius, because it effectively only perturbs the last layer. ❌
💡So we need to allow layerwise perturbation scaling!
🧵 5/10
10.12.2024 07:08 — 👍 2 🔁 0 💬 1 📌 0

Feature Learning in Infinite-Width Neural Networks
As its width tends to infinity, a deep neural network's behavior under gradient descent can become simplified and predictable (e.g. given by the Neural Tangent Kernel (NTK)), if it is parametrized app...
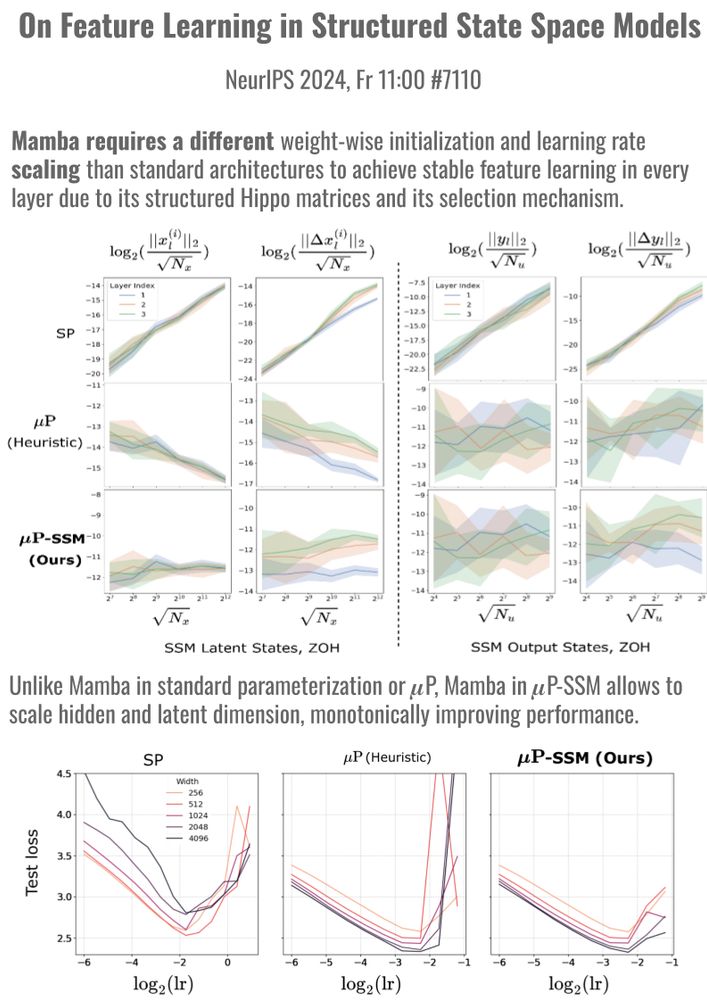
The maximal update parametrization (𝝁P) by arxiv.org/abs/2011.14522 is a layerwise scaling rule of learning rates and initialization variances that yields width-independent dynamics and learning rate transfer for SGD and Adam in common architectures. But for standard SAM, ...
🧵 4/10
10.12.2024 07:08 — 👍 2 🔁 0 💬 1 📌 0
SAM and model scale are widely observed to improve generalization across datasets and architectures. But can we understand how to optimally scale in a principled way? 📈🤔
🧵 3/10
10.12.2024 07:08 — 👍 3 🔁 0 💬 1 📌 0
Short thread for effective SAM scaling here.
arxiv.org/pdf/2411.00075
A thread on our Mamba scaling will be coming soon by
🔜 @leenacvankadara.bsky.social
🧵2/10
10.12.2024 07:08 — 👍 3 🔁 0 💬 1 📌 0
Stable model scaling with width-independent dynamics?
Thrilled to present 2 papers at #NeurIPS 🎉 that study width-scaling in Sharpness Aware Minimization (SAM) (Th 16:30, #2104) and in Mamba (Fr 11, #7110). Our scaling rules stabilize training and transfer optimal hyperparams across scales.
🧵 1/10
10.12.2024 07:08 — 👍 22 🔁 5 💬 1 📌 0
I'd love to be added :)
28.11.2024 19:28 — 👍 1 🔁 0 💬 1 📌 0
Institute of Science Tokyo / R. Yokota lab / Neural Network / Optimization
https://riverstone496.github.io/
New York Times columnist, author, backpacker and Oregon farmer. Always reporting on the ground. Trying to help democracy prevail and distracting myself by making great wine and cider at KristofFarms.com.
News and analysis with a global perspective. We’re here to help you understand the world around you. Subscribe here: https://econ.st/4fAeu4q
In-depth, independent reporting to better understand the world, now on Bluesky. News tips? Share them here: http://nyti.ms/2FVHq9v
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
Professor for Machine Learning, University of Tübingen, Germany
Postdoc at Simons at UC Berkeley; alumnus of Johns Hopkins & Peking University; deep learning theory.
https://uuujf.github.io
•PhD student @ https://www.ucl.ac.uk/gatsby 🧠💻
•Masters Theoretical Physics UoM|UCLA🪐
•Intern @zuckermanbrain.bsky.social|
@SapienzaRoma | @CERN | @EPFL
https://linktr.ee/Clementine_Domine
doing a phd in RL/online learning on questions related to exploration and adaptivity
> https://antoine-moulin.github.io/
phd student @ princeton · deep learning theory
eshaannichani.com
Researcher in Optimization for ML at Inria Paris. Previously at TU Munich. sbatch and apero.
https://fabian-sp.github.io/
Professor, University of Tübingen @unituebingen.bsky.social.
Head of Department of Computer Science 🎓.
Faculty, Tübingen AI Center 🇩🇪 @tuebingen-ai.bsky.social.
ELLIS Fellow, Founding Board Member 🇪🇺 @ellis.eu.
CV 📷, ML 🧠, Self-Driving 🚗, NLP 🖺
PhD Student at MPI-IS working on ML for Gravitational Waves | #MLforPhysics #SBI
https://www.annalenakofler.com
Graduate student at UMD CS
Harvard Applied Math PhD student. Neural computation
PhD in Computer Vision @UniFreiburg with Thomas Brox. Excited about AI! Working on VLMs.
https://lmb.informatik.uni-freiburg.de/people/bravoma/
PhD in Machine Learning at ETH Zürich, working on deep learning theory and principled large-scale AI models.
lorenzonoci.github.io




















