LLM Reasoning labs will be eating good today🍔
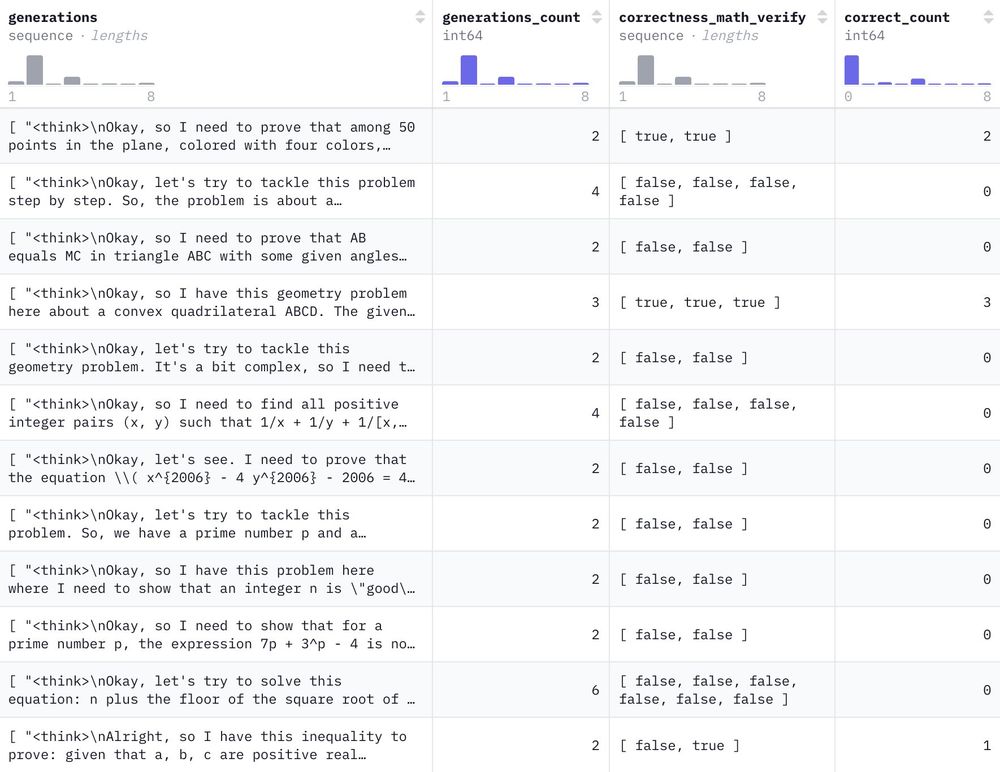
We commandeered the HF cluster for a few days and generated 1.2M reasoning-filled solutions to 500k NuminaMath problems with DeepSeek-R1 🐳
Have fun!

@eliebak.hf.co
Training LLM's at huggingface | hf.co/science
LLM Reasoning labs will be eating good today🍔
We commandeered the HF cluster for a few days and generated 1.2M reasoning-filled solutions to 500k NuminaMath problems with DeepSeek-R1 🐳
Have fun!
Last moments of closed-source AI 🪦 :
Hugging Face is openly reproducing the pipeline of 🐳 DeepSeek-R1. Open data, open training. open models, open collaboration.
🫵 Let's go!
github.com/huggingface/...

We are reproducing the full DeepSeek R1 data and training pipeline so everybody can use their recipe. Instead of doing it in secret we can do it together in the open!
Follow along: github.com/huggingface/...
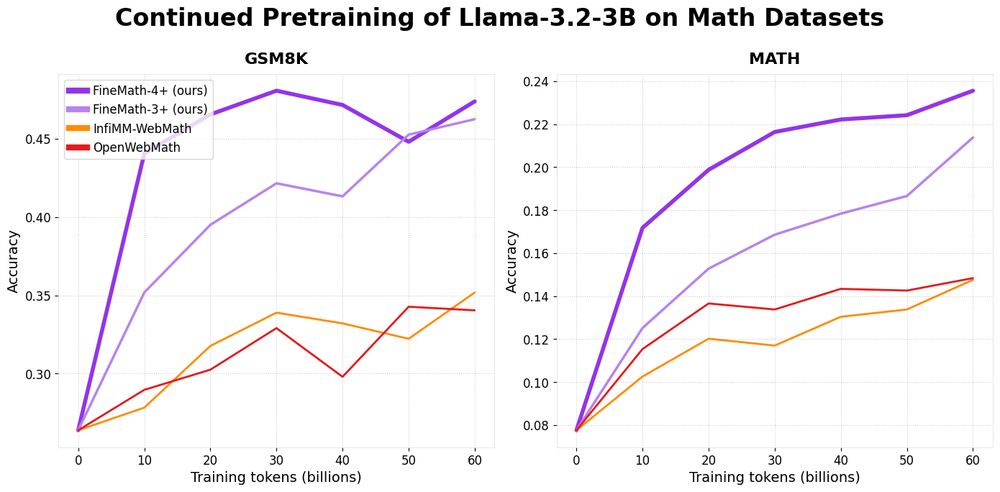
A plot showing increased performance of Llama-3.2-3B when pretrained on FineMath
Introducing 📐FineMath: the best open math pre-training dataset with 50B+ tokens!
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
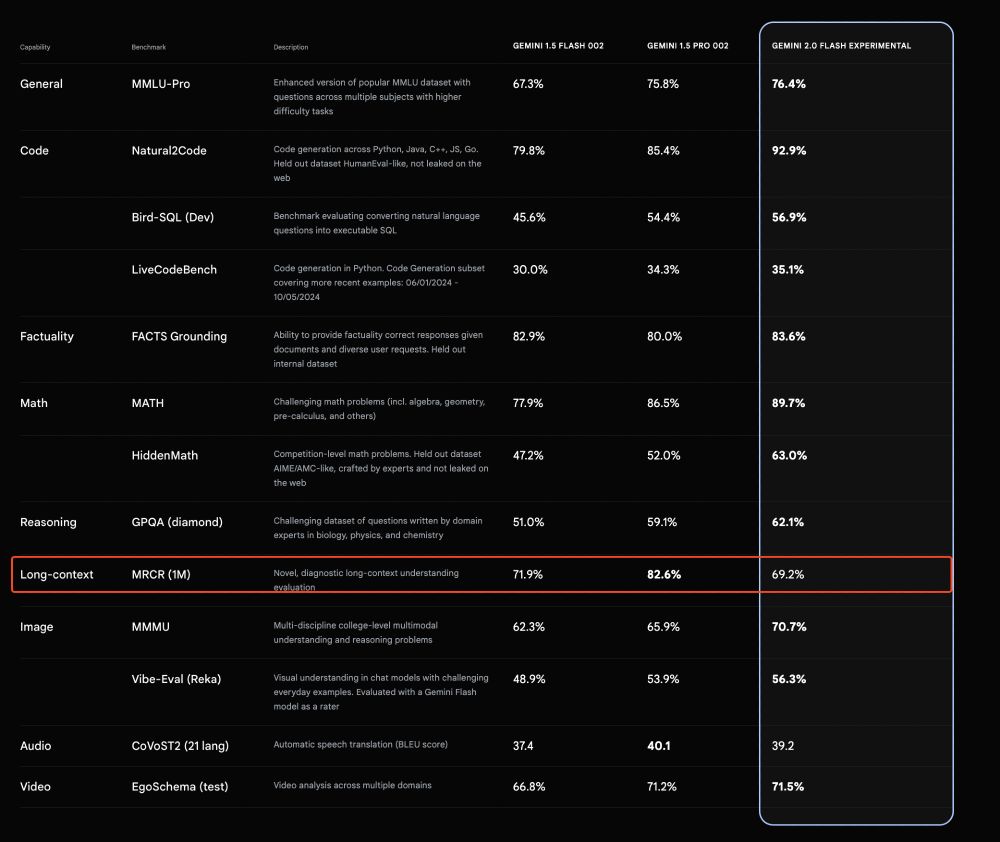
WOW, Gemini Flash 2.0 is really impressive. Wondering about the size of this supposedly smol model.
One odd thing is that the model seems to lose some ability with long contexts compared to Flash 1.5. If any google friends could share insights, I'd love to hear them!
👋👋
10.12.2024 00:23 — 👍 1 🔁 0 💬 1 📌 0Curious about this, what is the % of "new ideas" that you are not allowed to publish? (if you can answer ofc)
05.12.2024 22:57 — 👍 0 🔁 0 💬 0 📌 0should be good now
05.12.2024 19:59 — 👍 0 🔁 0 💬 0 📌 0Hey, I'll be at neurips next week! My DM are open if you want to meet and talk about pre-training/data/whatever you want 🫡
04.12.2024 08:06 — 👍 4 🔁 0 💬 1 📌 0Link: www.freepatentsonline.com/y2024/037844...
I've probably missed a lot, feel free to add more ⬇️
- They use some kind of metadata token to give information about toxicity, data leakage but also "quality" token?
- [0118] talk about using some kind of lora's during the finetuning/alignment phase to adapt on multiple downstream task
- ~[0154] some memory evaluation technique?

Google patent on "Training of large neural network". 😮
I don't know if this give much information but by going quickly through it seems that:
- They are not only using "causal language modeling task" as a pre-training task but also "span corruption" and "prefix modeling". (ref [0805]-[0091])

So many open-source and open releases last week!
Here's a recap, find the text-readable version here huggingface.co/posts/merve/...
📬 Summarize and rewrite your text/emails faster, and offline!
Check @andimara.bsky.social's Smol Tools for summarization and rewriting. It uses SmolLM2 to summarize text and make it more friendly or professional, all running locally thanks to llama.cpp github.com/huggingface/...
What else should we log during LLM training? Right now, it's just loss, grad_norm, and evals, but I want to log more to have a better understanding of pre-training. Thinking about adding stuff like entropix metrics (agreement, varentropy?)
Any thoughts or cool ideas?
Glad to have you back!
28.11.2024 21:52 — 👍 3 🔁 0 💬 0 📌 0i find it sad but imo it's good news that those people block 'us.' I'm tired of seeing hateful comments on my colleagues' (and other ML engineers/researchers') posts."
28.11.2024 14:37 — 👍 8 🔁 0 💬 0 📌 0why not flex attention?
28.11.2024 08:35 — 👍 2 🔁 0 💬 0 📌 0
my bad, here you go for US! apply.workable.com/huggingface/...
28.11.2024 06:20 — 👍 1 🔁 0 💬 0 📌 0should be okay!
28.11.2024 06:20 — 👍 2 🔁 0 💬 0 📌 0WOW! 🤯 Language models are becoming smaller and more capable than ever! Here's SmolLM2 running 100% locally in-browser w/ WebGPU on a 6-year-old GPU. Just look at that speed! ⚡️😍
Powered by 🤗 Transformers.js and ONNX Runtime Web!
How many tokens/second do you get? Let me know! 👇

A job description stating: About this Role This internship works at the intersections of software engineering, machine learning engineering, and education. With a strong focus on distributed training through the accelerate library (https://huggingface.co/docs/accelerate/index), we'll focus on bringing state-of-the-art training techniques into the library while also documenting and helping teach others how they work. By the end of this internship, the candidate will have touched on all aspects of distributed training and core library contributions, including large-scale distributed training, API design, writing educational material aimed at a semi-technical audience, and understanding the nuances of writing software that scales.
I'm looking for an intern!
If you are:
* Driven
* Love OSS
* Interested in distributed PyTorch training/FSDPv2/DeepSpeed
Come work with me!
Fully remote, more details to apply in the comments
10000% agree with omar, this is totally disproportionate
27.11.2024 13:09 — 👍 7 🔁 0 💬 1 📌 0
We’re looking for an intern to join our SmolLM team! If you’re excited about training LLMs and building high-quality datasets, we’d love to hear from you. 🤗
US: apply.workable.com/huggingface/...
EMEA: apply.workable.com/huggingface/...
super nice! 🤗
26.11.2024 18:08 — 👍 2 🔁 0 💬 0 📌 0
On the Xet team at @huggingface.bsky.social we're always looking for ways to move bytes to computer near you as fast as possible.
To do this, we're redesigning the upload and download infrastructure on the Hub. This post describes how, check the thread for details 🧵
huggingface.co/blog/rearchi...
yayyyyyy! 🔥
26.11.2024 16:48 — 👍 1 🔁 0 💬 0 📌 0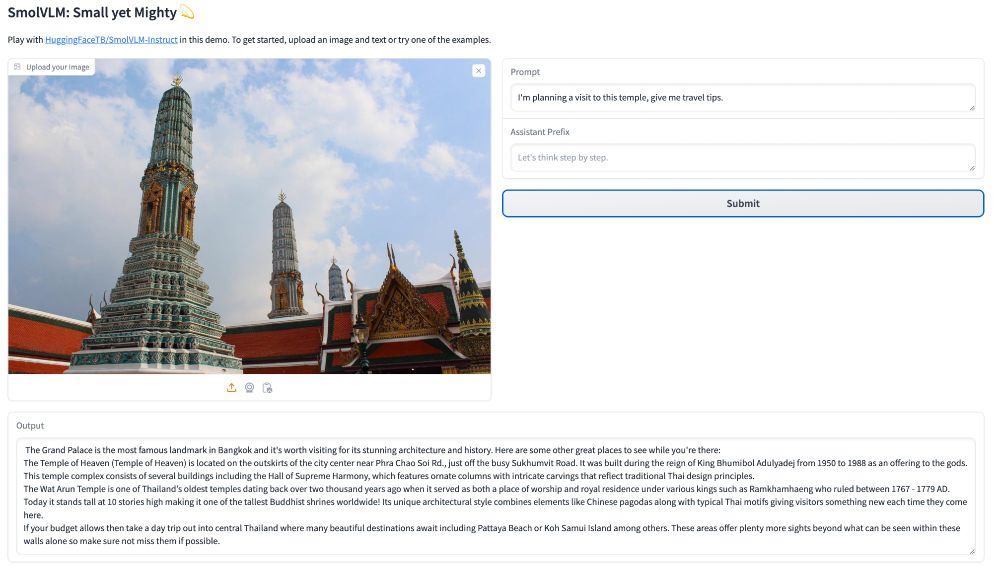
The SmolLM series has a new member: say hi to SmolVLM! 🤏
It uses a preliminary 16k context version of SmolLM2 to tackle long-context vision documents and higher-res images.
And yes, we’re cooking up versions with bigger context lengths. 👨🍳
Try it yourself here: huggingface.co/spaces/Huggi...

Small yet mighty! 💫
We are releasing SmolVLM: a new 2B small vision language made for on-device use, fine-tunable on consumer GPU, immensely memory efficient 🤠
We release three checkpoints under Apache 2.0: SmolVLM-Instruct, SmolVLM-Synthetic and SmolVLM-Base huggingface.co/collections/...

Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!



















