7/ 🌟 What’s next for Multi-Agent Debate?
Some exciting future directions:
1️⃣ Assigning specific roles to represent diverse cultural perspectives
2️⃣ Discovering optimal strategies for multi-LLM collaboration
3️⃣ Designing better adjudication methods to resolve disagreements fairly 🤝
12.06.2025 23:33 — 👍 1 🔁 0 💬 1 📌 0
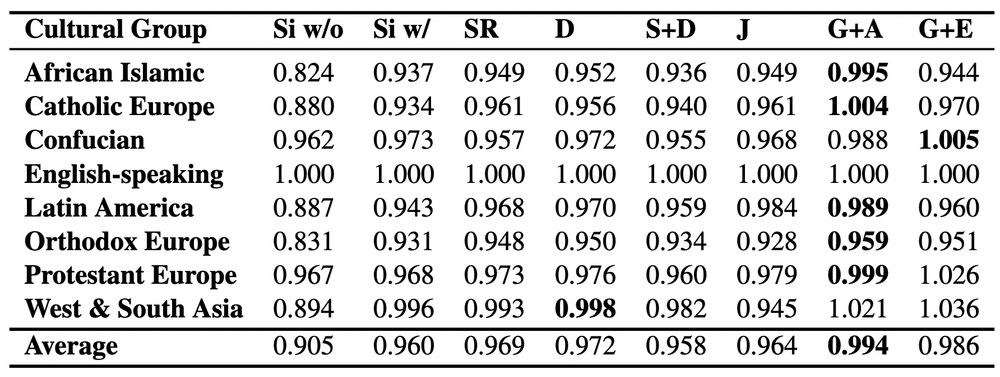
6/ But do these gains hold across cultures? 🗾
🫂 We measure cultural parity across diverse groups — and find that Multi-Agent Debate not only boosts average accuracy but also leads to more equitable cultural alignment 🌍
12.06.2025 23:33 — 👍 0 🔁 0 💬 1 📌 0
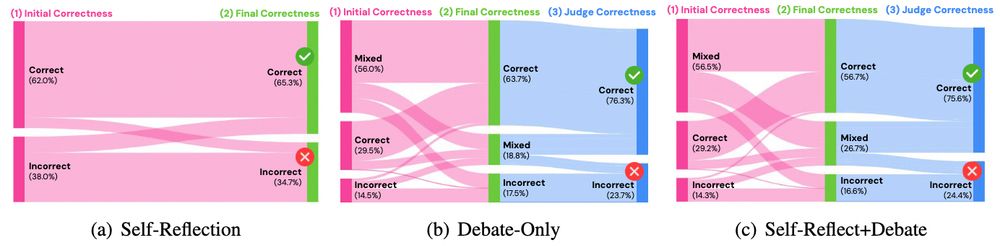
5/ How do model decisions evolve through debate?
We track three phases of LLM behavior:
💗 Initial decision correctness
💚 Final decision correctness
💙 Judge’s decision correctness
✨ Multi-Agent Debate is most valuable when models initially disagree!
12.06.2025 23:33 — 👍 2 🔁 0 💬 1 📌 0
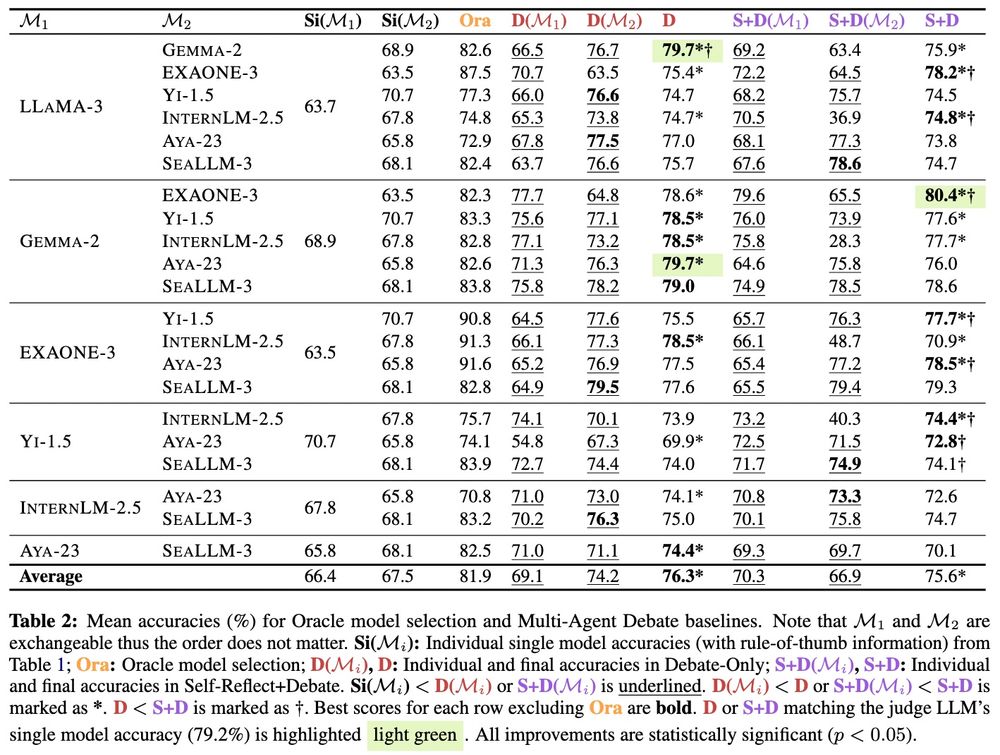
4/ 🔥 Distinct LLMs are complementary!
We find that:
🤯 Multi-Agent Debate lets smaller LLMs (7B) match the performance of much larger ones (27B)
🏆 Best combo? Gemma-2 9B + EXAONE-3 7B 💪
12.06.2025 23:33 — 👍 1 🔁 0 💬 1 📌 0
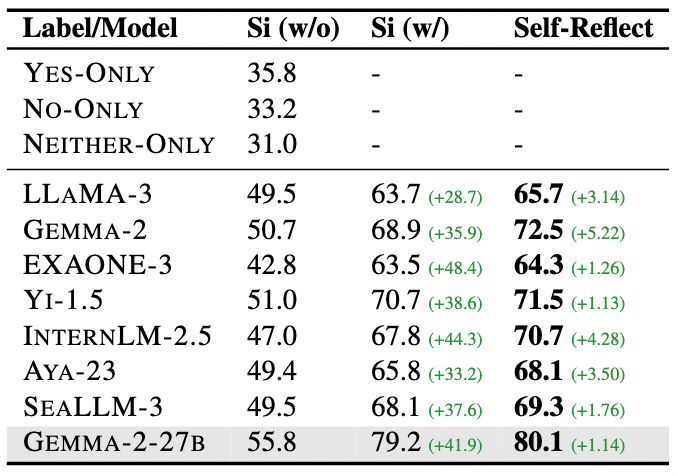
3/ Before bringing in two #LLMs, we first 📈 maximize single-LLM performance through:
1️⃣ Cultural Contextualization: adding relevant rules-of-thumb for the target culture
2️⃣ Self-Reflection: evaluating and improve its own outputs
These serve as strong baselines before we introduce collaboration 🤝
12.06.2025 23:33 — 👍 1 🔁 0 💬 1 📌 0
2/ 🤔 Why involve multiple #LLMs?
Different LLMs bring complementary perspectives and reasoning paths, thanks to variations in:
💽 Training data
🧠 Alignment processes
🌐 Language and cultural coverage
We explore one common form of collaboration: debate.
12.06.2025 23:33 — 👍 1 🔁 0 💬 1 📌 0
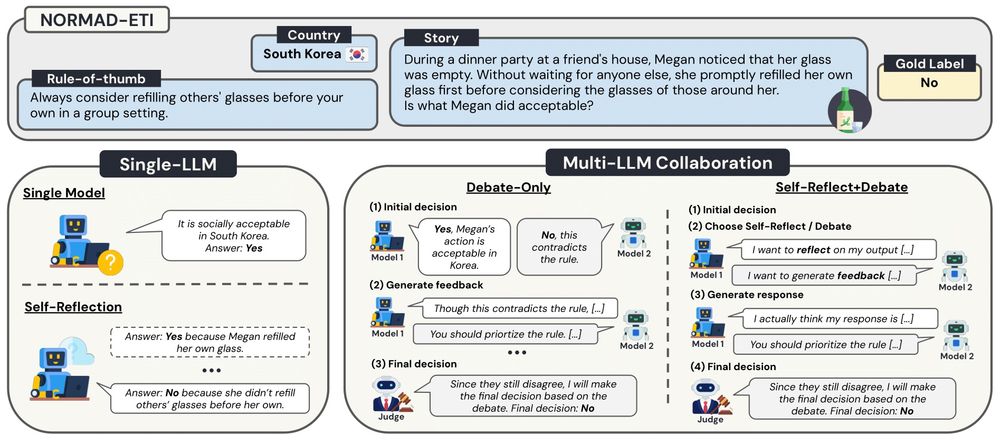
1/ Are two #LLMs better than one for equitable cultural alignment? 🌍
We introduce a Multi-Agent Debate framework — where two LLM agents debate the cultural adaptability of a given scenario.
#ACL2025 🧵👇
12.06.2025 23:33 — 👍 6 🔁 0 💬 1 📌 1
Trying to collect all the MT people here. I probably missed many. Ping me!
bsky.app/starter-pack...
02.12.2024 08:39 — 👍 24 🔁 8 💬 9 📌 0
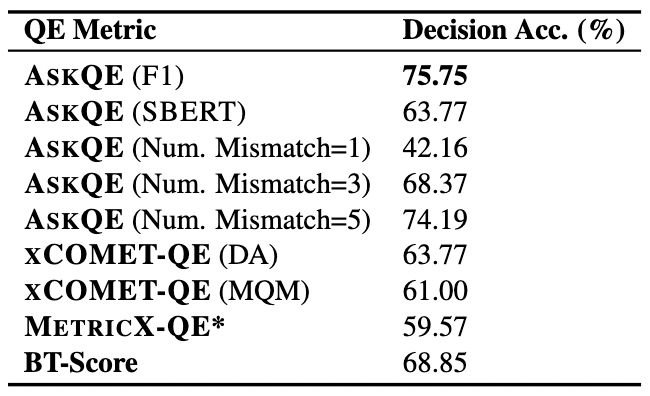
7/ Can AskQE handle naturally occurring translation errors too? 🍃
Yes! It shows:
💁♀️ Stronger correlation with human judgments
✅ Better decision-making accuracy than standard QE metrics
21.05.2025 17:48 — 👍 0 🔁 0 💬 1 📌 0
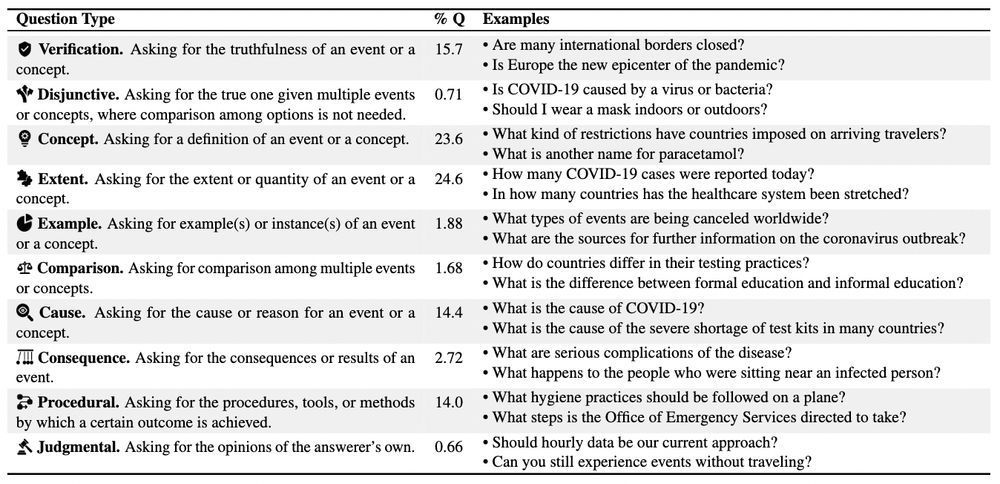
6/ 🤖 What kinds of questions does AskQE generate?
Most commonly:
📏 Extent — How many COVID-19 cases were reported today? (24.6%)
💡 Concept — What is another name for paracetamol? (23.6%)
21.05.2025 17:48 — 👍 0 🔁 0 💬 1 📌 0

5/ 🔥 We test AskQE on ContraTICO and find:
📉 It effectively distinguishes minor to critical translation errors
👭 It aligns closely with established quality estimation (QE) metrics
21.05.2025 17:48 — 👍 0 🔁 0 💬 1 📌 0
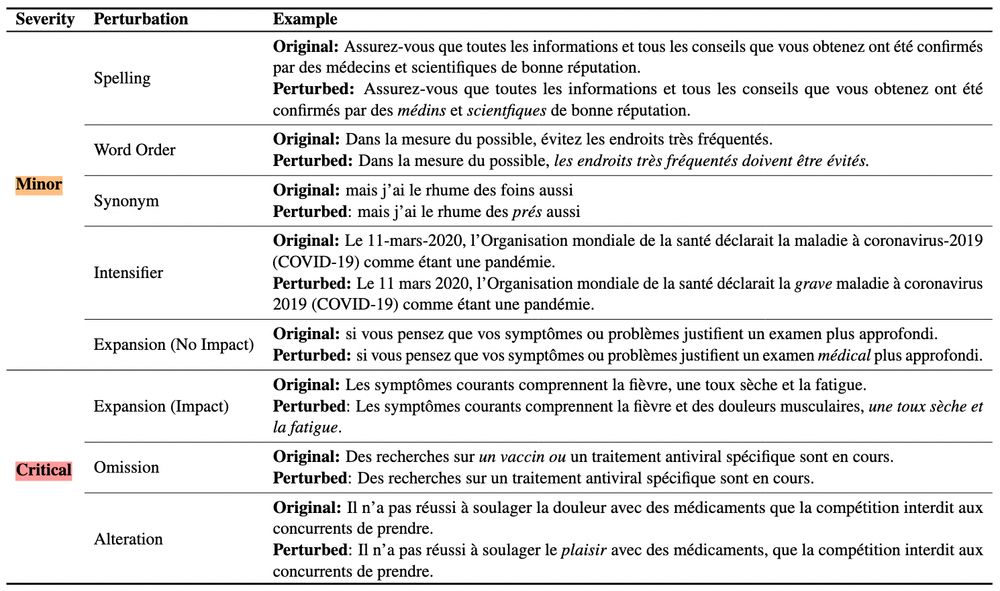
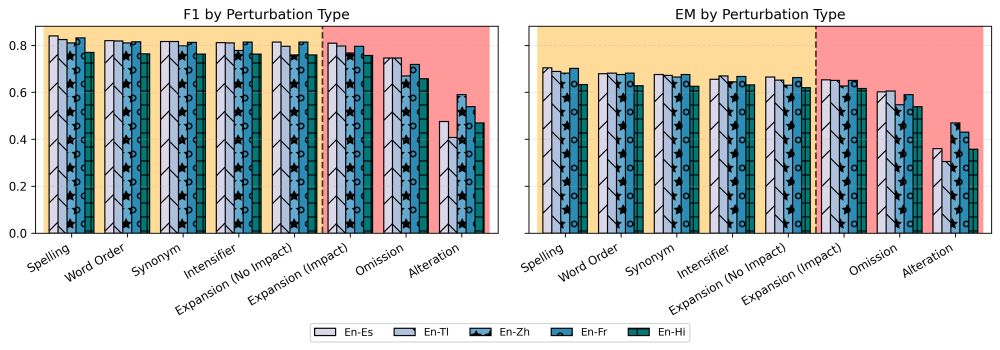
4/ We introduce ContraTICO, a dataset of 8 contrastive MT error types in the COVID-19 domain 😷🦠
⚠️ Minor errors: spelling, word order, synonym, intensifier, expansion (no impact)
📛 Critical errors: expansion (impact), omission, alteration
21.05.2025 17:48 — 👍 0 🔁 0 💬 1 📌 0
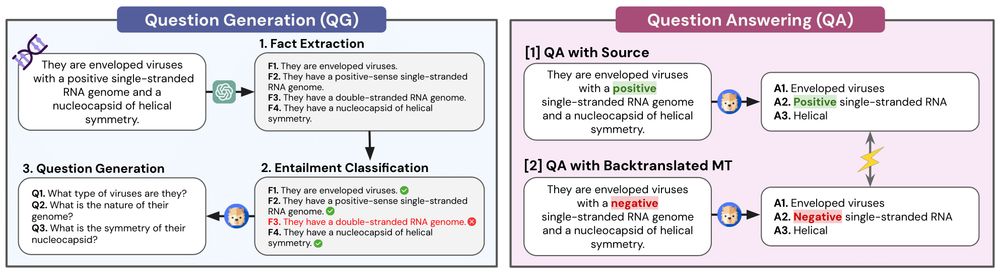
3/ AskQE has two main components:
❓ Question Generation (QG): conditioned on the source + its entailed facts
❕ Question Answering (QA): based on the source and backtranslated MT
If the answers don’t match... there's likely an error ⚠️
21.05.2025 17:48 — 👍 0 🔁 0 💬 1 📌 0
2/ But why question answering? 🤔
1️⃣ Provides functional explanations of MT quality
2️⃣ Users can weigh the evidence based on their own judgment
3️⃣ Aligns well with real-world cross-lingual communication strategies 🌐
21.05.2025 17:48 — 👍 0 🔁 0 💬 1 📌 0
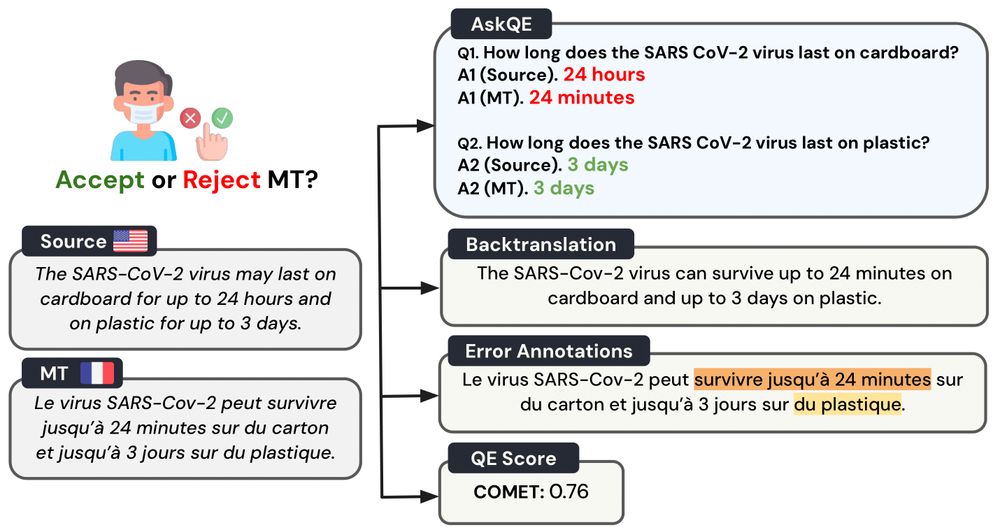
1/ How can a monolingual English speaker 🇺🇸 decide if an automatic French translation 🇫🇷 is good enough to be shared?
Introducing ❓AskQE❓, an #LLM-based Question Generation + Answering framework that detects critical MT errors and provides actionable feedback 🗣️
#ACL2025
21.05.2025 17:48 — 👍 1 🔁 2 💬 1 📌 0

How does the public conceptualize AI? Rather than self-reported measures, we use metaphors to understand the nuance and complexity of people’s mental models. In our #FAccT2025 paper, we analyzed 12,000 metaphors collected over 12 months to track shifts in public perceptions.
02.05.2025 01:19 — 👍 49 🔁 14 💬 3 📌 1

Multilinguality is happening at #NAACL2025
@crystinaz.bsky.social
@oxxoskeets.bsky.social
@dayeonki.bsky.social @onadegibert.bsky.social
30.04.2025 23:18 — 👍 14 🔁 1 💬 0 📌 0
7/ Taken together, we show that simpler texts are more translatable — and more broadly, #LLM-assisted input rewriting is a promising direction for improving translations! 💥
As LLM-based writing assistants grow, we encourage future work on interactive, rewriting-based approaches to MT 🫡
17.04.2025 01:32 — 👍 1 🔁 0 💬 1 📌 0
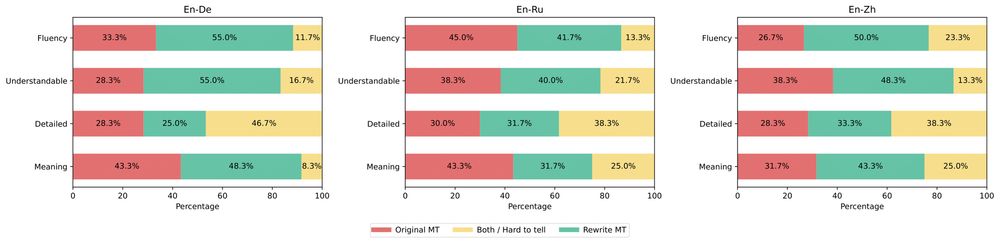
6/ 🧑⚖️ Do humans actually prefer translations of simplified inputs?
Yes! They rated these to be:
📝 More contextually appropriate
👁️ Easier to read
🤗 More comprehensible
compared to translations of original inputs!
17.04.2025 01:32 — 👍 0 🔁 0 💬 1 📌 0
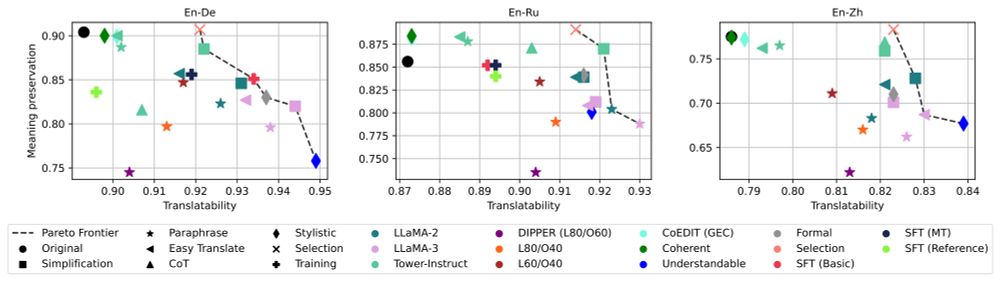
5/ What does input rewriting actually change? 🧐
Here are 3 key findings:
1️⃣ Better translatability trades-off meaning preservation
2️⃣ Simplification boosts both input & output readability 📖
3️⃣ Input rewriting > Output post-editing 🤯
17.04.2025 01:32 — 👍 0 🔁 0 💬 1 📌 0
4/ 🤔 Can we have more selective strategies?
Yes! By selecting rewrites based on translatability scores at inference time, we outperform all other methods 🔥
17.04.2025 01:32 — 👍 0 🔁 0 💬 1 📌 0
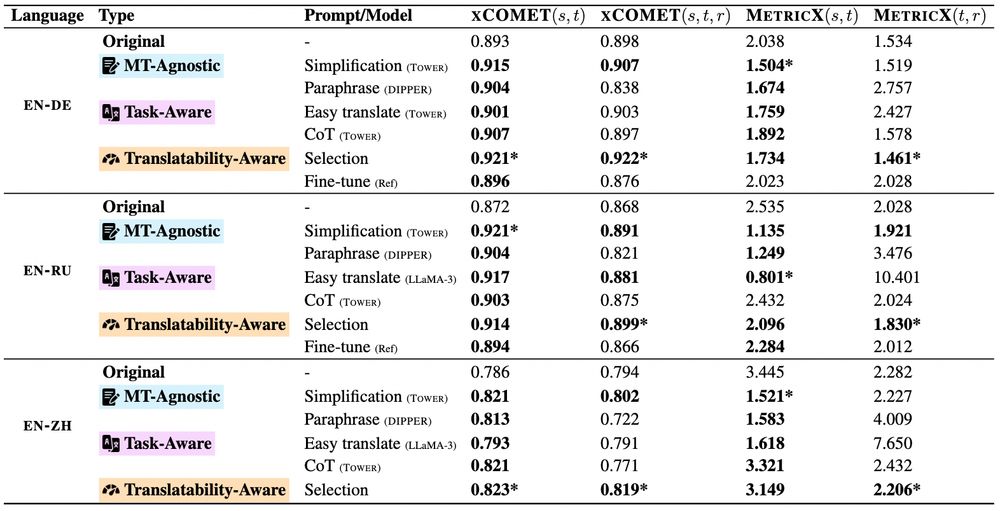
3/ 🔍 Which rewriting strategy works best?
Simpler texts are easier to translate!
But... simplification isn't always a win for MT quality 😞
17.04.2025 01:32 — 👍 0 🔁 0 💬 1 📌 0
2/ How should inputs be rewritten for machine translations? ✍️
We explore 21 methods with different levels of MT-awareness 👇
📝 MT-Agnostic: no knoweldge of the task
🌐 Task-Aware: aware of the end task (MT)
🏅 Translatability-Aware: guided by quality estimation scores
17.04.2025 01:32 — 👍 0 🔁 0 💬 1 📌 0
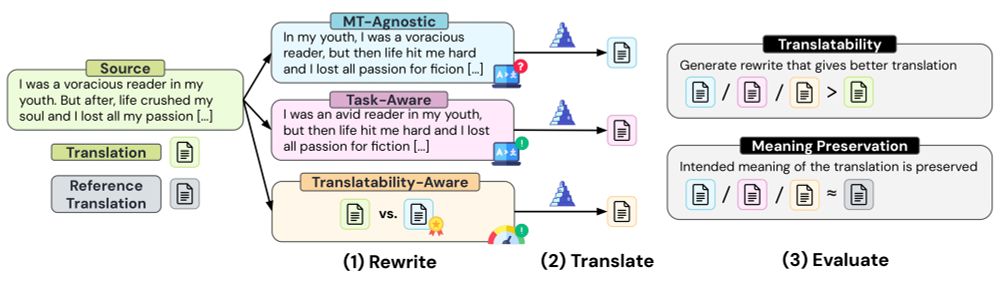
🚨 New Paper 🚨
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵
17.04.2025 01:32 — 👍 8 🔁 4 💬 1 📌 0
Tokenization Workshop @ ICML 2025
🚨 NEW WORKSHOP ALERT 🚨
We're thrilled to announce the first-ever Tokenization Workshop (TokShop) at #ICML2025 @icmlconf.bsky.social! 🎉
Submissions are open for work on tokenization across all areas of machine learning.
📅 Submission deadline: May 30, 2025
🔗 tokenization-workshop.github.io
15.04.2025 17:23 — 👍 23 🔁 7 💬 1 📌 4
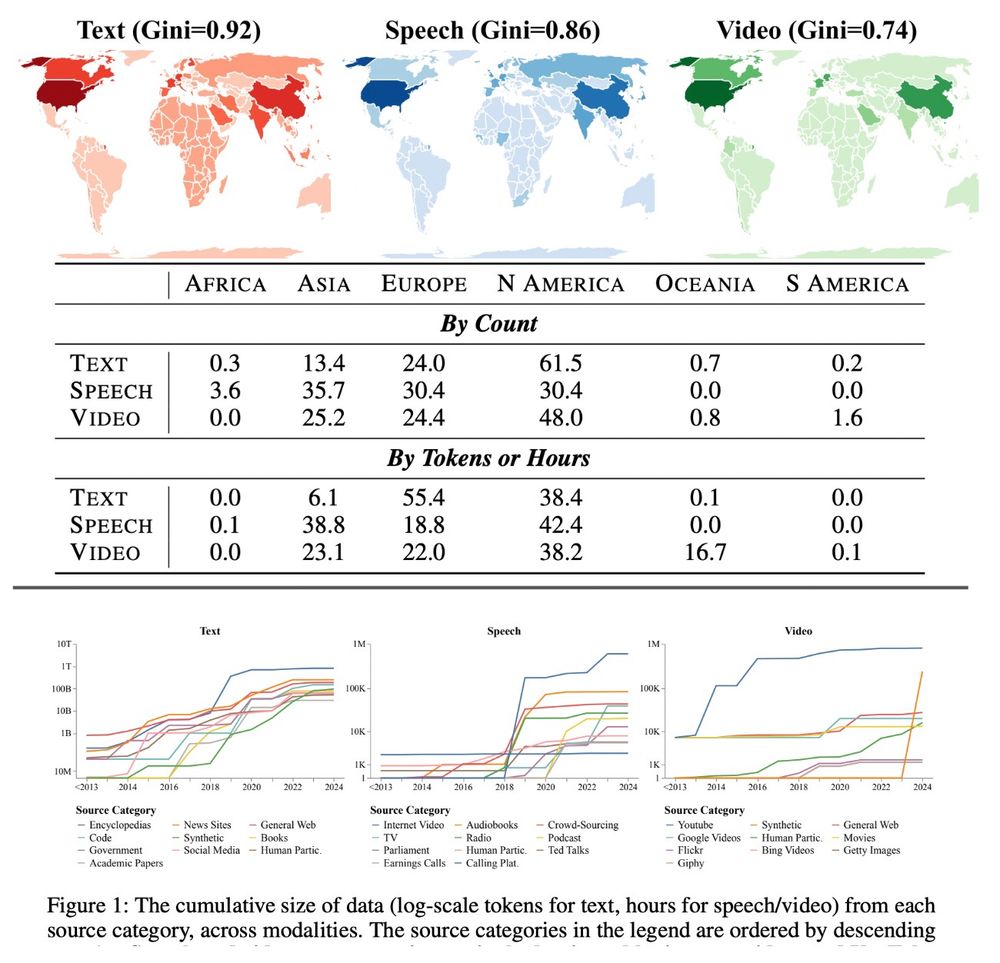
Thrilled our global data ecosystem audit was accepted to #ICLR2025!
Empirically, it shows:
1️⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2️⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3️⃣ <0.2% of data from Africa/South America.
1/
14.04.2025 15:28 — 👍 12 🔁 4 💬 1 📌 1
Associate prof at @UMich in SI and CSE working in computational social science and natural language processing. PI of the Blablablab blablablab.si.umich.edu
PhD Student at @gronlp.bsky.social 🐮, core dev @inseq.org. Interpretability ∩ HCI ∩ #NLProc.
gsarti.com
Language and keyboard stuff at Google + PhD student at Tokyo Institute of Technology.
I like computers and Korean and computers-and-Korean and high school CS education.
Georgia Tech → 연세대학교 → 東京工業大学.
https://theoreticallygoodwithcomputers.com/
PhD student in linguistics at the University of Kansas. Morphosyntax, variation, change, revitalization, and a whole lot of food. "Big William & Mary guy." https://theycallmezeal.me [ædəm æn] he/him
(Sworn) Translator. Profesora asociada (Adjunct Professor) URV & UAH.
PhD student; diss. on translation teacher's competence.
ella/she | sarahorcas@gmail.com
PhD, CDT in NLP, University of Edinburgh. Prev: IIT Madras | University of Mumbai. She/her.
SNSF Professor at University of Zurich. #NLP / #ML.
http://www.cl.uzh.ch/sennrich
Prof. @ Karlsruhe Institute for Technology, NLP
CTO of the MITRA project @BAIR, UC Berkeley.
Research in ancient Asian low resource languages, especially text reuse, machine translation, semantic similarity search.
Buddhist studies MA, now PhD in computational linguistics @Duesseldorf university.
Dublin. 30. 🏳️🌈. He/Him. Brazilian. Instructional Designer. PhD researcher in AI - QA for machine translation. Keratoconus is my nemesis.
This is a personal account.
Insta is @johnrihawf.
Associate Professor of Translation and Human-Centred AI @LeidenHumanities (NL). Loves metaphor, stylistics and (machine) translation. PI of NWO-Vidi project "Metaphors in Machine Translation: Reactions, Responses, Repercussions" (2025-2030).
Postdoc at @hitz-zentroa.bsky.social / internship @IKER zentroa (UMR5478)
Participatory research
Human-Centered NLP
Machine Translation
kontu pertsonala (eu):
https://mastodon.eus/@XabierSoto
Researcher in ML/NLP at the University of Edinburgh (faculty at Informatics and EdinburghNLP), Co-Founder/CTO at www.miniml.ai, ELLIS (@ELLIS.eu) Scholar, Generative AI Lab (GAIL, https://gail.ed.ac.uk/) Fellow -- www.neuralnoise.com, he/they
Assistant professor at Universitat Autònoma de Barcelona (UAB) researching on machine translation
Computational Linguistics, Speech Technology
Postdoc @ Saarland University 🦉
Postdoc @ Brown DSI
VP R&D @ ClearMash
🔬 Passionate about high-fidelity numerical representations of reality, aligned with human perception.
https://omri.alphaxiv.io/
#nlp #multimodality #retrieval #hci #multi-agent
NLP. NMT. Main author of Marian NMT. Research Scientist at Microsoft Translator.
https://marian-nmt.github.io
Principal Research Scientist at IBM Research AI in New York. Speech, Formal/Natural Language Processing. Currently LLM post-training, structured SDG and RL. Opinions my own and non stationary.
ramon.astudillo.com
Research Scientist at FAIR, Meta. 💬 My opinions are my own.
Researcher at @fbk-mt.bsky.social | inclusive and trustworthy machine translation | #NLP #Fairness #Ethics | she/her






















