👋 Hello world! We’re thrilled to announce the v0.4 release of fairseq2 — an open-source library from FAIR powering many projects at Meta. pip install fairseq2 and explore our trainer API, instruction & preference finetuning (up to 70B), and native vLLM integration.
12.02.2025 12:31 — 👍 4 🔁 2 💬 1 📌 2
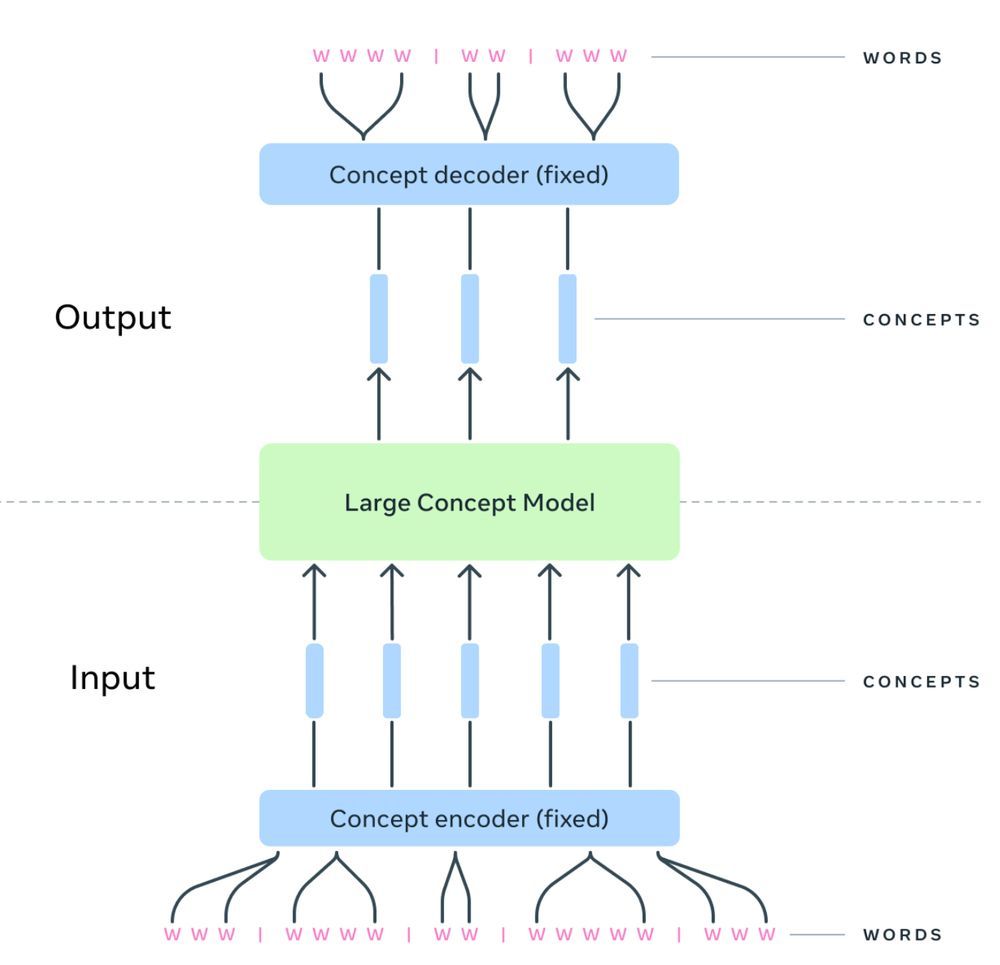
The LCM component here (green) is the only place where we have diffusion, i.e., denoising is only performed at the concept (sentence) level. The concept decoder is a regular subword-level decoder conditioning on a single vector (the sentence vector from the LCM).
16.12.2024 22:05 — 👍 1 🔁 0 💬 0 📌 0

3/3 Figure 13 from the paper shows the flops under different settings of "context size in sentences" & "average length of a sentence". It would definitely be much costlier if we had 1 sentence = 1-5 subwords.
16.12.2024 20:42 — 👍 1 🔁 0 💬 1 📌 0
1/3 Yes. The LCM denoises one concept at a time. A concept once denoised is dispatched to a sentence decoder to generate the corresponding text. No, it does not take 40x the flops of a traditional subword-level decoder.
16.12.2024 20:42 — 👍 1 🔁 0 💬 1 📌 0
8/ A massive shout-out to the amazing team who made this happen! Loic, Artyom, Paul-Ambroise, David, Tuan and many more awesome collaborators
14.12.2024 18:59 — 👍 0 🔁 0 💬 0 📌 0

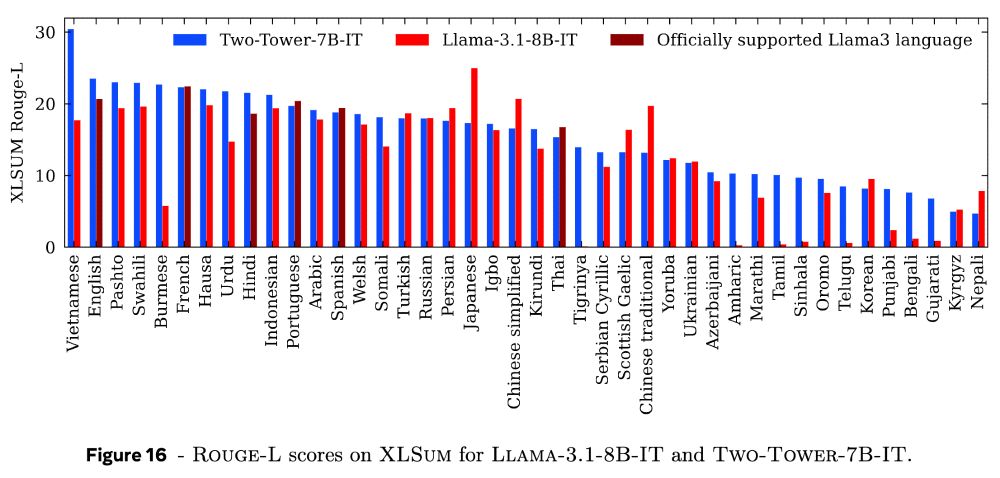
6/ We scale our two-tower diffusion LCM to 7B parameters, achieving competitive summarization performance with similarly sized LLMs. Most importantly, the LCM demonstrates remarkable zero-shot generalization capabilities, effectively handling unseen languages.
14.12.2024 18:59 — 👍 0 🔁 0 💬 2 📌 0

5/ One main challenge of the LCMs was coming up with search algorithms. We use an “end of document” concept and introduce a stopping criterion based on the distance to this special concept. Common inference parameters in diffusion models play a major role too (guidance scale, initial noise, ...)
14.12.2024 18:59 — 👍 0 🔁 0 💬 1 📌 0
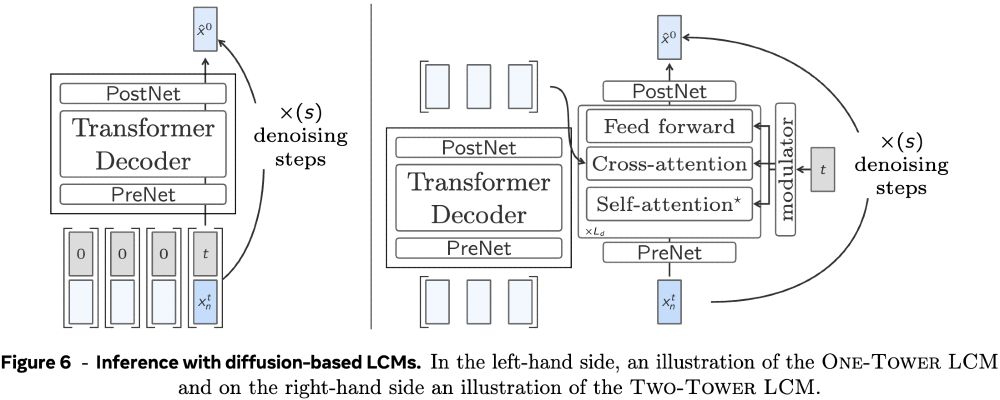
4/ Two diffusion architectures were proposed: “One-Tower” with a single Transformer decoder encoding the context and denoising the next concept at once, and “Two-tower” where we separate context encoding from denoising.
14.12.2024 18:59 — 👍 0 🔁 0 💬 1 📌 0
3/ We explored different designs for the LCM, a model that can generate the next continuous SONAR embedding conditioned on a sequence of preceding embeddings (MSE regression, diffusion, quantized SONAR). Our study revealed diffusion models to be the most effective approach.
14.12.2024 18:59 — 👍 0 🔁 0 💬 1 📌 0
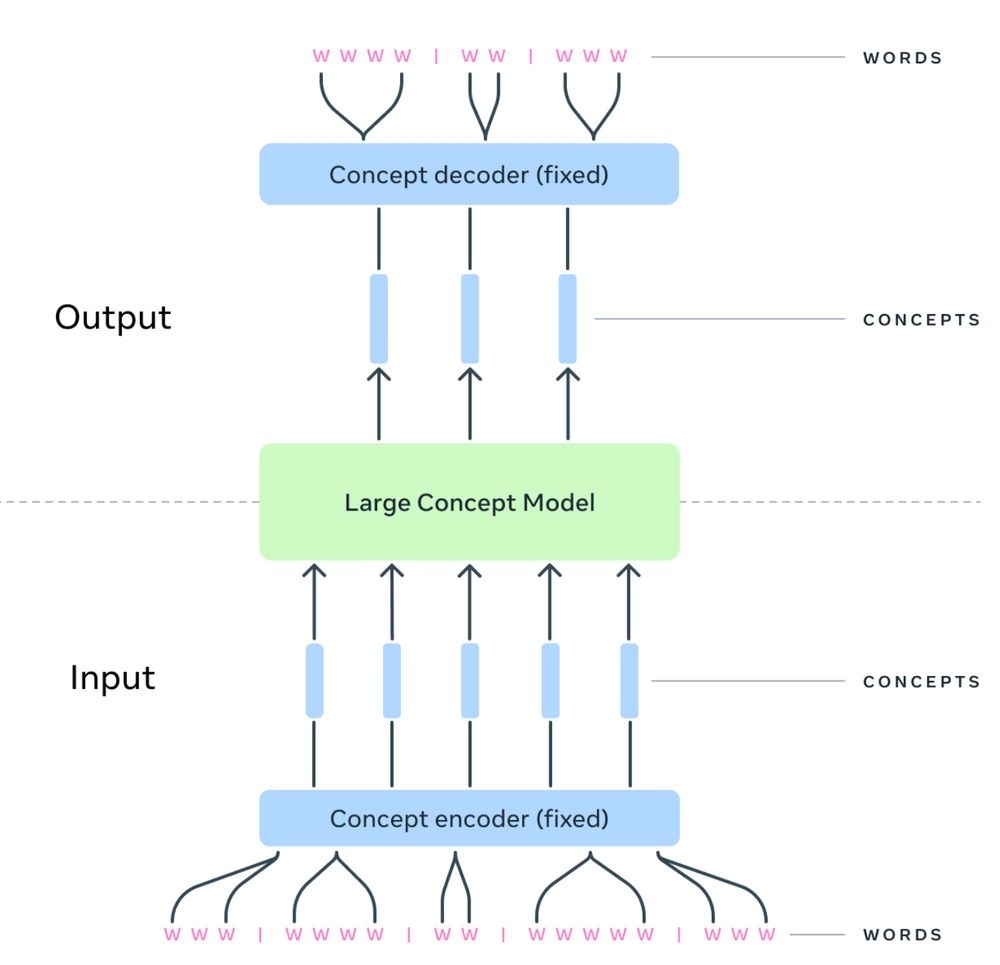
2/ Within the SONAR space, the LCM is trained to predict the next concept in a sequence. The LCM architecture is hierarchical, incorporating SONAR encoders and decoders to seamlessly map into and from the internal space where the LCM performs its computations.
14.12.2024 18:59 — 👍 1 🔁 1 💬 1 📌 0

1/ LCMs operate at the level of meaning or what we label “concepts”. This corresponds to a sentence in text or an utterance in speech. These units are then embedded into SONAR, a language- and modality-agnostic representation space. github.com/facebookrese...
14.12.2024 18:59 — 👍 1 🔁 0 💬 1 📌 0
Research Scientist @ Google DeepMind - working on video models for science. Worked on video generation; self-supervised learning; VLMs - 🦩; point tracking.
Research scientist at Meta, PhD candidate at Mila and Université de Montréal. Working on multimodal vision+language generation. Català a Zúric.
PhD student @jhuclsp. Previously @AIatMeta, @InriaParisNLP, @EM_LCT| #NLProc
FAIR Sequence Modeling Toolkit 2
Research Scientist at valeo.ai | Teaching at Polytechnique, ENS | Alumni at Mines Paris, Inria, ENS | AI for Autonomous Driving, Computer Vision, Machine Learning | Robotics amateur
⚲ Paris, France 🔗 abursuc.github.io
software designer @github.com • big nerd • skateboarder • opinions my own etc • danielfos.co on the web • 🇧🇷🇳🇱
Zealous modeler. Annoying statistician. Reluctant geometer. Support my writing at http://patreon.com/betanalpha. He/him.
Recently a principal scientist at Google DeepMind. Joining Anthropic. Most (in)famous for inventing diffusion models. AI + physics + neuroscience + dynamical systems.
Professor, Santa Fe Institute. Research on AI, cognitive science, and complex systems.
Website: https://melaniemitchell.me
Substack: https://aiguide.substack.com/
Safe and robust AI/ML, computational sustainability. Former President AAAI and IMLS. Distinguished Professor Emeritus, Oregon State University. https://web.engr.oregonstate.edu/~tgd/
So far I have not found the science, but the numbers keep on circling me.
Views my own, unfortunately.
Open source developer building tools to help journalists, archivists, librarians and others analyze, explore and publish their data. https://datasette.io […]
[bridged from https://fedi.simonwillison.net/@simon on the fediverse by https://fed.brid.gy/ ]
Always pondering startups, ML, Rust, Python, and 3D printing.
Independent ML researcher consulting on LMs + data.
Previously: Salesforce Research, MetaMind, CommonCrawl, Harvard. 🇦🇺 in SF. He/him.
Personal blog: https://state.smerity.com
Musician, math lover, cook, dancer, 🏳️🌈, and an ass prof of Computer Science at New York University
I lead Cohere For AI. Formerly Research
Google Brain. ML Efficiency, LLMs,
@trustworthy_ml.
DeepMind Professor of AI @Oxford
Scientific Director @Aithyra
Chief Scientist @VantAI
ML Lead @ProjectCETI
geometric deep learning, graph neural networks, generative models, molecular design, proteins, bio AI, 🐎 🎶
jmhessel.com
@Anthropic. Seattle bike lane enjoyer. Opinions my own.
Professor, Programmer in NYC.
Cornell, Hugging Face 🤗
CS professor at NYU. Large language models and NLP. he/him
I make sure that OpenAI et al. aren't the only people who are able to study large scale AI systems.