Only 10 days left to submit your work to our International Workshop on News Recommendation and Analytics! 🚀
▶️ More details: research.idi.ntnu.no/NewsTech/INR...
📆 Submission deadline: July 17th, 2025 AoE
📍 Event co-located with @recsys.bsky.social
in Prague on September 26th (tentative)!
07.07.2025 11:51 — 👍 4 🔁 5 💬 0 📌 1
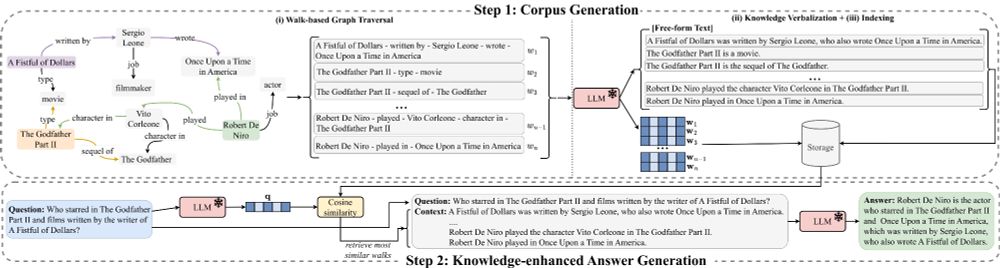
📢 Introducing Walk&Retrieve, a simple yet effective zero-shot #RAG framework based on #knowledgegraph walks!
Arxiv : arxiv.org/abs/2505.16849
GitHub: github.com/MartinBoeckl...
Joint work w/ @martinboeckling.bsky.social @heikopaulheim.bsky.social
Details 👇
23.05.2025 12:48 — 👍 6 🔁 4 💬 1 📌 0

Title slide: Processing Trans Languaging - Vagrant Gautam (they/xe), Saarland University, with a very brightly patterned background featuring colourful people and math symbols.
Come to my keynote tomorrow at the first official @queerinai.com workshop at #NAACL2025 to hear about how trans languaging is complex and cool, and how this makes it extra difficult to process computationally. I will have SO many juicy examples!
03.05.2025 20:52 — 👍 44 🔁 14 💬 3 📌 0
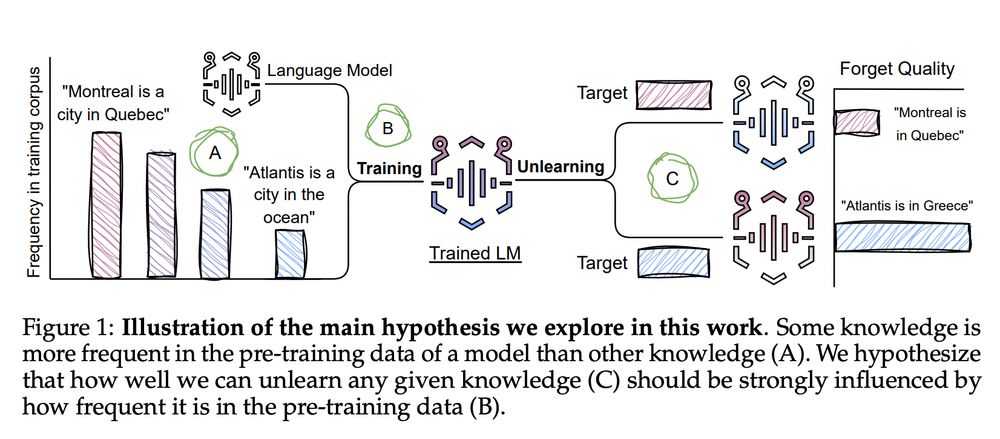
Diagram illustrating a hypothesis about knowledge unlearning in language models. The left side shows a training corpus with varying frequencies of facts, such as 'Montreal is a city in Quebec' (high frequency) and 'Atlantis is a city in the ocean' (lower frequency). The center shows a language model being trained on this data, then undergoing unlearning. The right side demonstrates the 'Forget Quality' results, where the model more effectively unlearns the less frequent fact ('Atlantis is in Greece') while retaining the more frequent knowledge. Labels A, B, and C mark key points in the hypothesis: A (frequency variations in training data), B (influence of frequency), and C (unlearning effectiveness).
Check out our new paper on unlearning for LLMs 🤖. We show that *not all data are unlearned equally* and argue that future work on LLM unlearning should take properties of the data to be unlearned into account. This work was lead by my intern @a-krishnan.bsky.social
🔗: arxiv.org/abs/2504.05058
09.04.2025 13:30 — 👍 32 🔁 5 💬 1 📌 1

📣 Call for Papers is out! 📣
Working on #news #recsys & their societal, legal, and ethical dimensions?
👉 Submit to the 13th INRA workshop, co-located w/ @recsys.bsky.social in Prague!
📅 Paper deadline: ** July 17th, 2025 **
More info: research.idi.ntnu.no/NewsTech/INR...
#INRA2025 #RecSys2025
05.05.2025 12:37 — 👍 3 🔁 5 💬 0 📌 1
Hello! INRA is a forum for researchers and practitioners to discuss technical innovations, societal, ethical, and legal aspects of news recommendation and analytics.
The upcoming 13th edition of our workshop will be co-located w/ @recsys.bsky.social in Prague.
Stay tuned to this channel!
02.05.2025 08:14 — 👍 3 🔁 5 💬 1 📌 0
Joint work with Florian Schneider, Chris Biemann, and @gglavas.bsky.social
My first paper on multilingual vision-language, and couldn't be happier how this work turned out!🙂
21.02.2025 07:45 — 👍 0 🔁 0 💬 0 📌 1
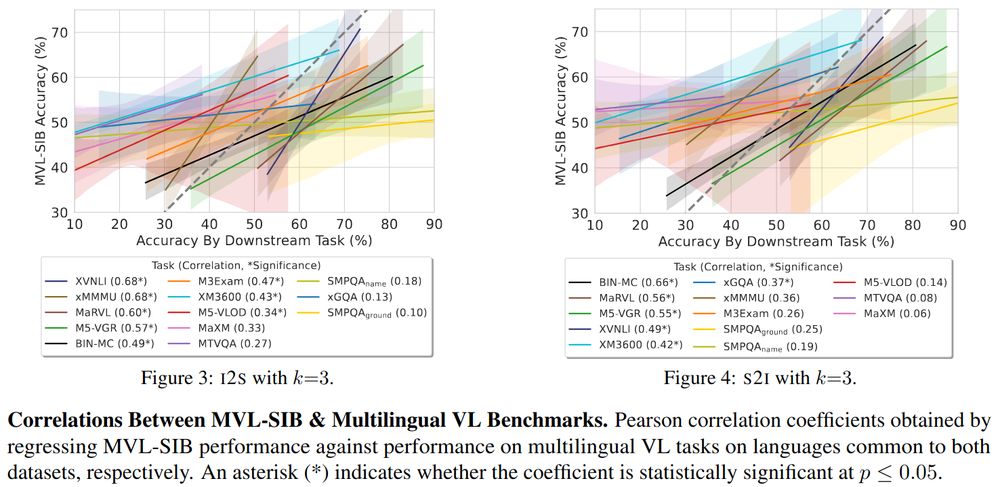
Cross-modal topic matching correlates well with other multilingual vision-language tasks!
🤗Images-To-Sentence (given Images, select topically fitting sentence) & Sentences-To-Image (given Sentences, pick topically matching image) probe complementary aspects in VLU
21.02.2025 07:45 — 👍 2 🔁 1 💬 1 📌 0

X-modal to text-only perf. *gap* shows that VL support decreases from high to low-resource language tiers:
Images/Topic→Sentence (for I/T, pick S): narrows with less textual support (left)
Sentences→Image/Topic (for S, pick I/T): increases with less VL support worse (right)
21.02.2025 07:45 — 👍 1 🔁 1 💬 1 📌 0
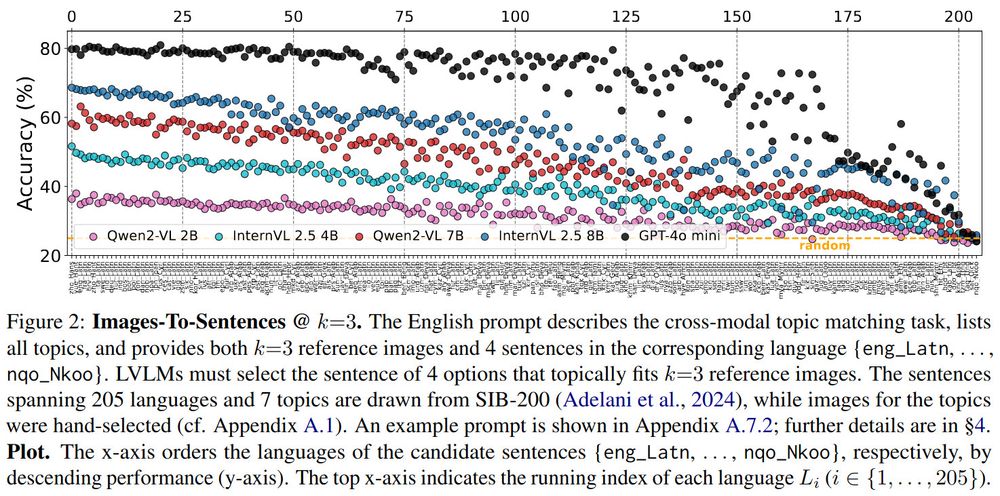
Strong vision-language models (VLMs) like GPT-4o-mini maintain good performance for top-150 languages, only to drop to performing no better than chance for the lowest resource languages!
21.02.2025 07:45 — 👍 1 🔁 1 💬 1 📌 0

Introducing MVL-SIB, a massively multilingual vision-language benchmark for cross-modal topic matching in 205 languages!
🤔Tasks: Given images (sentences), select topically matching sentence (image).
Arxiv: arxiv.org/abs/2502.12852
HF: huggingface.co/datasets/Wue...
Details👇
21.02.2025 07:45 — 👍 4 🔁 5 💬 1 📌 0
I'm making an unofficial starter pack with some of my colleagues at Mila. WIP for now but here's the link!
go.bsky.app/BHKxoss
20.11.2024 15:19 — 👍 69 🔁 29 💬 7 📌 1
International Workshop on News Recommendation and Analytics
Next edition: at ACM RecSys @ Prague, 22nd–26th September
https://research.idi.ntnu.no/NewsTech/INRA/index.html
Hello! I'm Cesare (pronounced Chez-array). I'm a PhD student at McGill/Mila working in NLP/computational pragmatics.
@mcgill-nlp.bsky.social
@mila-quebec.bsky.social
https://cesare-spinoso.github.io/
he/him
3rd and final year PhD Student
Researching on the applications and limitations of multimodal transformer encoder and decoder models.
Professor for Natural Language Processing @uniwuerzburg
Postdoc @ TakeLab, UniZG | previously: Technion; TU Darmstadt | PhD @ TakeLab, UniZG
Faithful explainability, controllability & safety of LLMs.
🔎 On the academic job market 🔎
https://mttk.github.io/
💻 PhD Student at @dh-fbk.bsky.social @mobs-fbk.bsky.social @land-fbk.bsky.social
🇮🇹 FBK, University of Trento
🇪🇺 @ellis.eu
☕ NLP, CSS and coffee
https://nicolopenzo.github.io/
Visiting researcher at Meta FAIR, PhD candidate at Mila and Université de Montréal. Working on multimodal vision+language learning. Català a Montreal.
Common Crawl is a non-profit foundation dedicated to the Open Web.
Senior Research Scientist at the Common Crawl Foundation. Weird coffee person ☕️, runner 🏃🏻♂️. (he/him) 🇫🇷🇪🇺🇨🇴
Research scientist @NVIDIA | PhD in machine learning @UofT. Previously @Google / @MetaAI. Opinions are my own. 🤖 💻 ☕️
CS PhD candidate @UCLA | Prev. Research Intern @MSFTResearch, Applied Scientist Intern @AWS | LLM post-training, multi-modal learning
https://yihedeng9.github.io
MSc Student in NeuroAI @ McGill & Mila
w/ Blake Richards & Shahab Bakhtiari
AI research @ Meta, Opinions @ my own
https://mega002.github.io
PhD in AI @mila-quebec.bsky.social RLHF and language grounding, whatever that means. Whitespace aficianado. mnoukhov.github.io
AI @ OpenAI, Tesla, Stanford
I make sure that OpenAI et al. aren't the only people who are able to study large scale AI systems.
Recently a principal scientist at Google DeepMind. Joining Anthropic. Most (in)famous for inventing diffusion models. AI + physics + neuroscience + dynamical systems.
PhD candidate at McGill and Mila (Quebec AI Institute) w/ Blake Richards and Doina Precup.
Doing research on AI and Neuroscience 🤖🧠
Based in Montreal. 🇨🇦






















