
Paper page - JuStRank: Benchmarking LLM Judges for System Ranking
Join the discussion on this paper page
Many more details are in the paper:
huggingface.co/papers/2412....
Thanks for the amazing collaborators: Ariel Gera, Odellia Boni, @yperlitz.bsky.social, Roy Bar-Haim, Lilach Eden, from IBM Research.
13.12.2024 10:16 — 👍 1 🔁 0 💬 1 📌 0

Overall, we found:
1⃣strong correlation between judge ranking abilities and decisiveness
2⃣and Negative correlation with its tendency for System-specific biases
13.12.2024 10:16 — 👍 0 🔁 0 💬 1 📌 0

Surprisingly, we found that self-bias is less prevalent than we thought
13.12.2024 10:16 — 👍 0 🔁 0 💬 1 📌 0
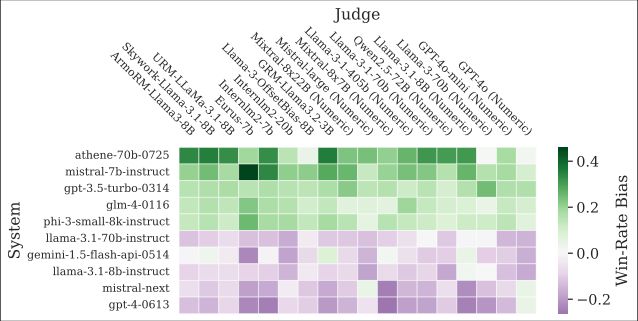
Secondly, we define a new type of Bias:
System-specific bias
Where a judge prefers or dislikes a specific system
Our results demonstrate large biases that affect systems-ranking
13.12.2024 10:16 — 👍 0 🔁 0 💬 1 📌 0
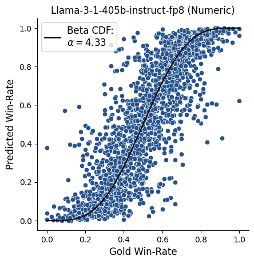
Analyzing these figures, we found an emergent judge behavior:
We call it decisiveness!
decisive judges prefer stronger systems, more than humans do!
We measure it based on the empirical fit
13.12.2024 10:16 — 👍 2 🔁 0 💬 1 📌 0

What does JuStRank tell us about general judge behavior?
For that, we turn to the system preference task
Given a pair of systems, which one is better!
We plot gold and judge predicted win-rates
13.12.2024 10:16 — 👍 0 🔁 0 💬 1 📌 0
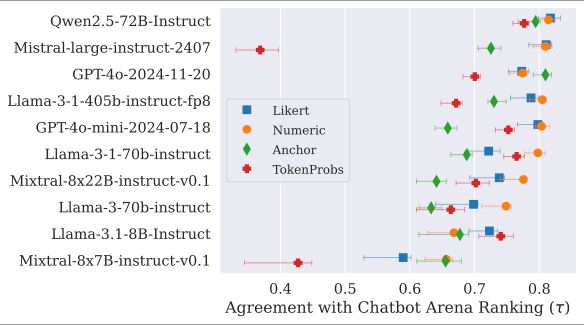
With JuStRank we found:
1⃣Smaller dedicated judges are on par with big ones
2⃣LLM judge's realization matters a lot
3⃣Comparative judgment is not the best for most judges
🕺💃
13.12.2024 10:16 — 👍 0 🔁 0 💬 1 📌 0
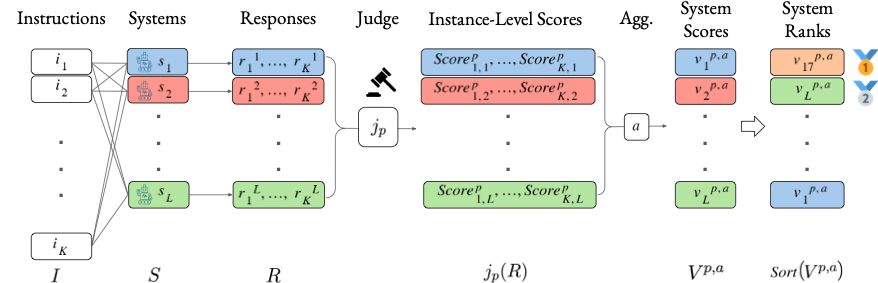
So how did we do it?
For LLMs, we took 4 unique realizations
➕ Reward models
they judge the responses of 64 systems
and got each judge's system ranking
Then we compare the ranking to Arena's gold rank
13.12.2024 10:16 — 👍 0 🔁 0 💬 1 📌 0

There are many new judge benchmarks
But most focus on evaluating the judge's ability to choose a better response
We focus on the judge's ability to choose a better system
13.12.2024 10:16 — 👍 0 🔁 0 💬 1 📌 0
#NLP Postdoc at Mila - Quebec AI Institute & McGill University
mariusmosbach.com
Breakthrough AI to solve the world's biggest problems.
› Join us: http://allenai.org/careers
› Get our newsletter: https://share.hsforms.com/1uJkWs5aDRHWhiky3aHooIg3ioxm
LM/NLP/ML researcher ¯\_(ツ)_/¯
yoavartzi.com / associate professor @ Cornell CS + Cornell Tech campus @ NYC / nlp.cornell.edu / associate faculty director @ arXiv.org / researcher @ ASAPP / starting @colmweb.org / building RecNet.io
I make sure that OpenAI et al. aren't the only people who are able to study large scale AI systems.
AI safety at Anthropic, on leave from a faculty job at NYU.
Views not employers'.
I think you should join Giving What We Can.
cims.nyu.edu/~sbowman
The NLP group at the Hebrew University of Jerusalem.
@royschwartznlp.bsky.social, @gabistanovsky.bsky.social, @tomhope.bsky.social and Prof. Omri Abend.
CS MSc student at the Hebrew University researching NLP @nlphuji.bsky.social | Former news editor
The Asia-Pacific Chapter of the Association for Computational Linguistics
The 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (AACL 2025)
https://www.afnlp.org/conferences/ijcnlp2025
#AACL2025 #NLProc #NLP
Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics
EMNLP 2025 - The annual Conference on Empirical Methods in Natural Language Processing
Dates: November 5-9, 2025 in Suzhou, China
Hashtags: #EMNLP2025 #NLP
Submission Deadline: May 19th, 2025
The Conference of the European Chapter of the Association for Computational Linguistics
Next event: Rabat, Morocco, March 24-29, 2026
Hashtags: #EACL2026 #NLProc
Faculty fellow at NYU CDS. Previously: PhD @ BIU NLP.
PhD student @ Penn
alonj.github.io
Ph.D.; AI Research Scientist @ IBM Research. http://eli-schwartz.com
NLP PhD Candidate at Tel Aviv University (Google PhD Fellow) | Working on LLM reasoning and Language Agents | Prev. Research intern at Meta FAIR and AI2
AI Planning and SDM research @ IBM Research
The NLP group at the University of Washington.
Computational Linguists—Natural Language—Machine Learning
 13.12.2024 13:06 — 👍 2 🔁 0 💬 1 📌 0
13.12.2024 13:06 — 👍 2 🔁 0 💬 1 📌 0




















