

The .txt team is growing. We're looking for a:
- Founding DevRel Engineer,
- Member of Technical Staff - LLM Inference, and
- a Rust Developer
Apply here: jobs.ashbyhq.com/dottxt
The .txt team is growing. We're looking for a:
- Founding DevRel Engineer,
- Member of Technical Staff - LLM Inference, and
- a Rust Developer
Apply here: jobs.ashbyhq.com/dottxt

Be our developer zero.
Join .txt as our Founding DevRel Engineer.
Apply here: jobs.ashbyhq.com/dottxt
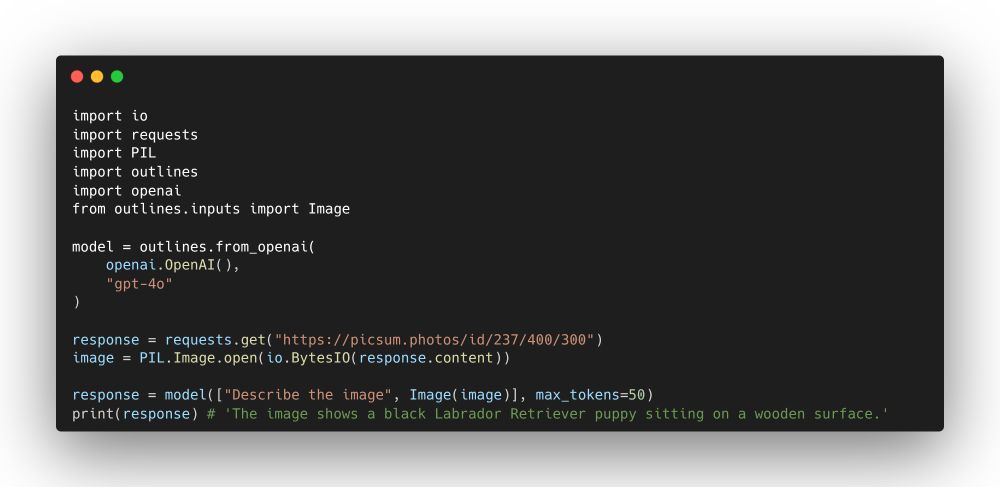
We changed the way we handle multimodal inputs in Outlines.
Most libraries will give the prompt a special role, separate it from the other inputs. We don’t anymore.
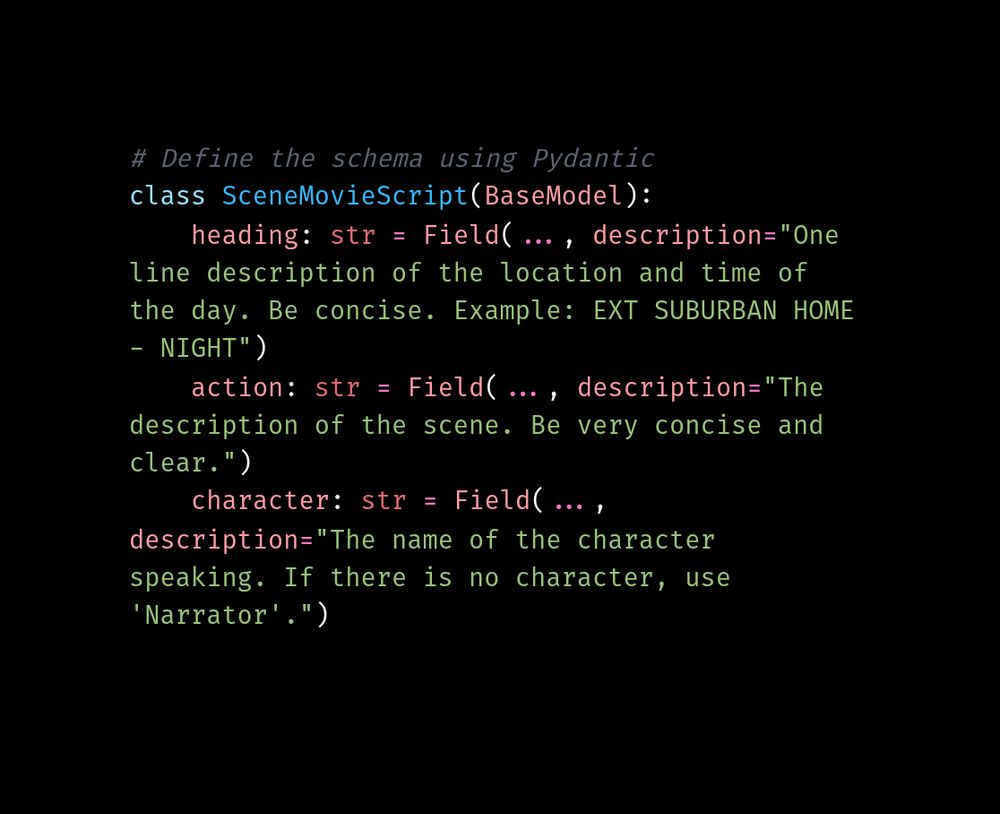
Check out this cool project by @aastroza.bsky.social to automatically convert any TV stream into a real-time movie script! Amazingly cool project using Outlines to enforce movie script formatting, and generally an impressive project.
Here's the entire JSON schema he uses.
github.com/aastroza/tvtxt

Another example from our internal context-free grammar hackathon. You can force a model to generate an acrostic, i.e. make each line start with a letter in a word -- HELLO in this case.
Grammars are cool.
We did make the machines in our own image
29.05.2025 20:57 — 👍 1 🔁 0 💬 0 📌 0
During our internal hackathon, one of our teams (named "Too Many Cooks") wrote a grammar-powered recipe generator. The language model can ONLY generate text consistent with this recipe format.
Here's a recipe for the universe.
🎵 Cameron with your eyes so bright
🎵 won't you join our Discord tonight
We've got a Discord channel if you want to talk about AI engineer, compound AI systems, low overhead agents (though who knows what that means), constrained decoding, or whatever you're building.
Come on by!
discord.gg/ErZ8XnCmkQ
Loved this paper. Smart idea.
Basically they "guess and check" whether a token would appease the compiler when an LLM is doing code generation.

Very cool paper. arxiv.org/abs/2504.09246
13.05.2025 16:06 — 👍 3 🔁 0 💬 0 📌 0
Here's a good example of a case where type-constrained decoding ensures that the program is semantically valid at generation time. Left is the unconstrained model, right is the type-constrained approach. Missing arguments, missing return values, missing type annotations. They fixed it for you.
13.05.2025 16:06 — 👍 1 🔁 0 💬 1 📌 0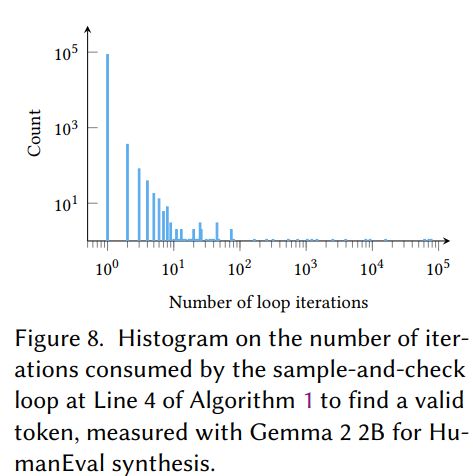
The authors here use rejection methods (guess and check), rather than the constrained decoding approach that modifies the token probabilities by disabling invalid tokens, like Outlines. Type checking is relatively cheap, and the model's first guess is correct 99.4% of the time.
13.05.2025 16:06 — 👍 1 🔁 0 💬 1 📌 0
The authors propose a novel solution to this, by rejecting tokens that would invalidate a type check. In the following example, num is known to be a number. Only one of these completions is valid, which is to convert the number to a string (as required by parseInt)
13.05.2025 16:06 — 👍 1 🔁 0 💬 1 📌 0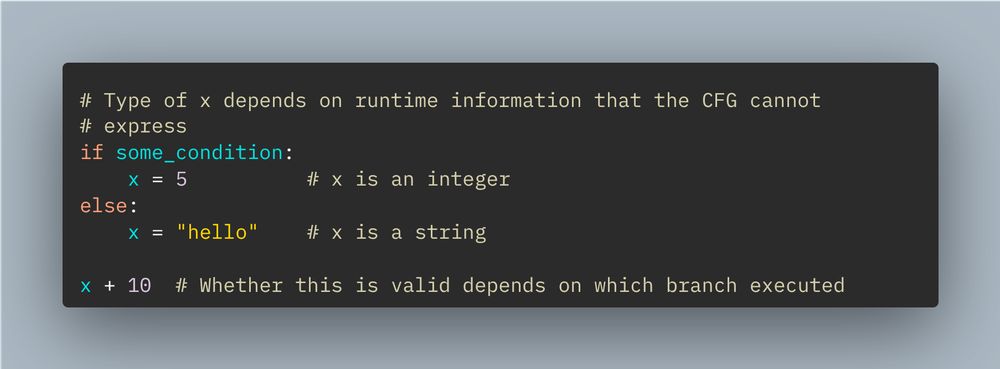
As an example, a context-free grammar cannot express the following type checking constraint, as there is no way of knowing ahead of time what the type of `x` is. Constrained decoding using a CFG cannot enforce the validity of "x+10".
13.05.2025 16:06 — 👍 1 🔁 0 💬 1 📌 0Context-free grammars are interesting in their own right. We'll do a thread about them at some point. For now, you should think of them as a "programming language for language" -- they describe the "shape" of text, such as code or natural language.
13.05.2025 16:06 — 👍 1 🔁 0 💬 1 📌 0Addressing this is an infamously difficult problem. Most programming languages are not "context-free", meaning that constraining a language model's output to be semantically valid cannot be done in advance using what is called a "context-free grammar".
13.05.2025 16:06 — 👍 1 🔁 0 💬 1 📌 0Most LLM-based failures in code generation are not syntactic errors (incorrect formatting). They are typically semantic failures (wrong types, missing arguments, etc). The paper notes that 94% of their compilation errors are due to incorrect types, with the remaining 6% due to syntax errors.
13.05.2025 16:06 — 👍 1 🔁 0 💬 1 📌 0
"Type-Constrained Code Generation with Language Models" is a relatively new paper that addresses a common challenge with LLM-generated code. The researchers are from ETH Zurich and UC Berkeley.
13.05.2025 16:06 — 👍 15 🔁 3 💬 1 📌 1
My talk "Building Knowledge Graph-Based Agents with Structured Text Generation" at PyData Global 2024 is now available on YouTube:
www.youtube.com/watch?v=94yu...
#PyData #PyDataGlobal @dottxtai.bsky.social @pydata.bsky.social
Do people like this type of thread? They're fun to write.
28.04.2025 20:40 — 👍 11 🔁 1 💬 2 📌 0
Grammar prompting is similar to chain-of-thought prompting, but with formal grammar as the intermediate reasoning step rather than natural language.
It's a cool paper, go take a look.
At inference time, the model generates a specialized grammar for the input, then generates output constrained by those grammar rules - creating a two-stage process of grammar selection + code generation.
Rather than input -> output, the model does input -> grammar -> output.
For each input/output example, they provide a context-free grammar that's minimally-sufficient for generating that specific output, teaching the LLM to understand grammar as a reasoning tool.
28.04.2025 19:00 — 👍 5 🔁 0 💬 1 📌 0The gist: LLMs struggle with DSLs because these formal languages have specialized syntax rarely seen in training data. Grammar prompting addresses this by teaching LLMs to work with Backus-Naur Form (BNF) grammars as an intermediate reasoning step.
28.04.2025 19:00 — 👍 3 🔁 0 💬 1 📌 0
"Grammar Prompting for Domain-Specific Language Generation with Large Language Models", by researchers from MIT and Google arxiv.org/abs/2305.19234
28.04.2025 19:00 — 👍 3 🔁 0 💬 1 📌 0
We recently came across an interesting paper that helps LLMs be better at handling domain-specific languages like database queries or probabilistic programming languages, using an approach called "grammar prompting".
Link + brief thread below.
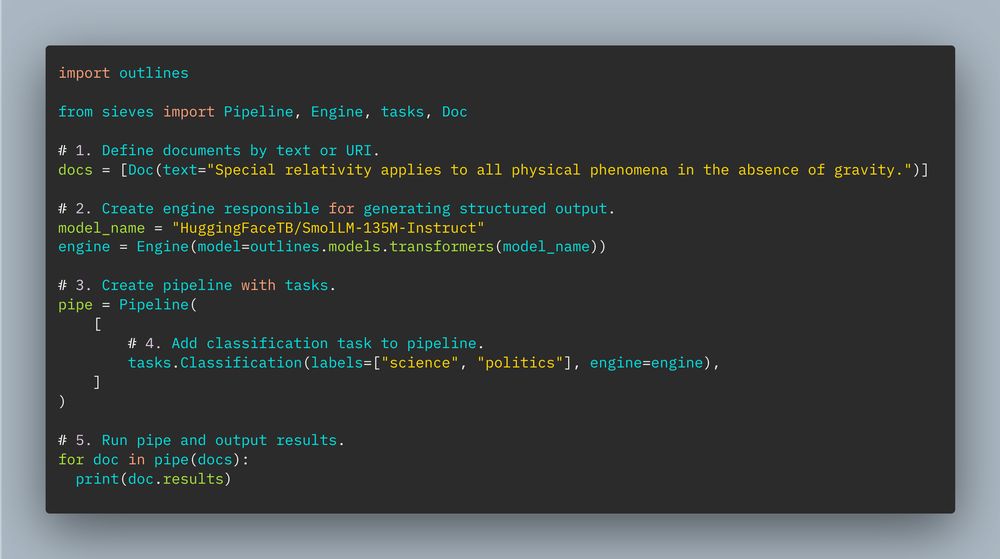
Check out the sieves library from Mantis NLP!
sieves is a library for structured document processing. It works with Outlines!
Go check out the library, it's pretty cool.
Repo: github.com/mantisai/sie...
llms.txt is an increasingly popular standard for making websites easily accessible to machine reading. We would provide provide an llms.txt file at the root of the docs page containing a condensed version of the documentation or website in Markdown format.
11.04.2025 19:01 — 👍 0 🔁 0 💬 0 📌 0
We're considering adding an llms.txt file to the upcoming Outlines v1.0 documentation to make it more machine readable! Opinions welcome.
github.com/dottxt-ai/ou...