This is a great question! I'm actually not sure why this happens. I do know that the identity accuracy in (3) comes from query promotion - it's close to random guessing of query symbols, and that identity demotion is learned in (7), but I will check out some of these checkpoints and let you know!
29.01.2026 22:57 — 👍 2 🔁 0 💬 0 📌 0

The Art of Wanting.
About the question I see as central in AI ethics, interpretability, and safety. Can an AI take responsibility? I do not think so, but *not* because it's not smart enough.
davidbau.com/archives/20...
27.01.2026 15:32 — 👍 10 🔁 3 💬 1 📌 0

Can models understand each other's reasoning? 🤔
When Model A explains its Chain-of-Thought (CoT) , do Models B, C, and D interpret it the same way?
Our new preprint with @davidbau.bsky.social and @csinva.bsky.social explores CoT generalizability 🧵👇
(1/7)
22.01.2026 21:58 — 👍 24 🔁 7 💬 1 📌 0

In-Context Algebra
Understanding the learned algorithms of transformer language models solving abstract algebra problems through in-context learning.
Takeaway: contextual reasoning can be richer than just fuzzy copying!
See the paper for more results, including an analysis of learning dynamics. Work done w/ @jannikbrinkmann.bsky.social, @rohitgandikota.bsky.social & @davidbau.bsky.social!
📜: arxiv.org/abs/2512.16902
🌐: algebra.baulab.info
22.01.2026 16:10 — 👍 12 🔁 2 💬 0 📌 0

Another strategy infers meaning using sets.
We have seen models keep track of "positive" and "negative" sets that let it narrow its understanding of a symbol using Sudoku-style cancellation.
Red bars (a) show the positive set and blue boxes (b) show the negative.
22.01.2026 16:10 — 👍 6 🔁 0 💬 1 📌 0

What in-context mechanisms do we find, other than copying?
The first one is the "identity rule". Here, the answer is the same as the question after eliminating a recognized "identity" from the question, like "ab=a".
@taylorwwebb.bsky.social has seen this in LLMs too!
bsky.app/profile/tay...
22.01.2026 16:10 — 👍 7 🔁 0 💬 1 📌 0

Our work maps out several context-based algorithms (copy, identity, commutativity, cancellation, & associativity). We use targeted data distributions to measure and dissect each strategy.
These five strategies explain almost all of our model's in-context performance!
22.01.2026 16:10 — 👍 8 🔁 0 💬 1 📌 0

If you pick a random puzzle (try one here: algebra.baulab.info), you'll see there's often more than one way to understand context.
@nelhage.bsky.social & @neelnanda.bsky.social found LLMs infer meaning by induction-style copying, and that happens here too. But there are many other strategies.
22.01.2026 16:10 — 👍 6 🔁 0 💬 1 📌 0

Can you solve this algebra puzzle? 🧩
cb=c, ac=b, ab=?
A small transformer can learn to solve problems like this!
And since the letters don't have inherent meaning, this lets us study how context alone imparts meaning. Here's what we found:🧵⬇️
22.01.2026 16:09 — 👍 47 🔁 10 💬 2 📌 2

Humans and LLMs think fast and slow. Do SAEs recover slow concepts in LLMs? Not really.
Our Temporal Feature Analyzer discovers contextual features in LLMs, that detect event boundaries, parse complex grammar, and represent ICL patterns.
13.11.2025 22:31 — 👍 18 🔁 8 💬 1 📌 1

LLMs have been shown to provide different predictions in clinical tasks when patient race is altered. Can SAEs spot this undue reliance on race? 🧵
Work w/ @byron.bsky.social
Link: arxiv.org/abs/2511.00177
05.11.2025 15:20 — 👍 5 🔁 2 💬 1 📌 1
Interested in doing a PhD at the intersection of human and machine cognition? ✨ I'm recruiting students for Fall 2026! ✨
Topics of interest include pragmatics, metacognition, reasoning, & interpretability (in humans and AI).
Check out JHU's mentoring program (due 11/15) for help with your SoP 👇
04.11.2025 14:44 — 👍 27 🔁 15 💬 0 📌 1

How can a language model find the veggies in a menu?
New pre-print where we investigate the internal mechanisms of LLMs when filtering on a list of options.
Spoiler: turns out LLMs use strategies surprisingly similar to functional programming (think "filter" from python)! 🧵
04.11.2025 17:48 — 👍 23 🔁 9 💬 1 📌 2
Looking forward to attending #COLM2025 this week! Would love to meet up and chat with others about interpretability + more. DMs are open if you want to connect. Be sure to checkout @sfeucht.bsky.social's very cool work on understanding concepts in LLMs tomorrow morning (Poster 35)!
06.10.2025 15:00 — 👍 2 🔁 0 💬 0 📌 0

What's the right unit of analysis for understanding LLM internals? We explore in our mech interp survey (a major update from our 2024 ms).
We’ve added more recent work and more immediately actionable directions for future work. Now published in Computational Linguistics!
01.10.2025 14:03 — 👍 40 🔁 14 💬 2 📌 2

Who is going to be at #COLM2025?
I want to draw your attention to a COLM paper by my student @sfeucht.bsky.social that has totally changed the way I think and teach about LLM representations. The work is worth knowing.
And you can meet Sheridan at COLM, Oct 7!
bsky.app/profile/sfe...
27.09.2025 20:54 — 👍 39 🔁 8 💬 1 📌 2

Announcing a broad expansion of the National Deep Inference Fabric.
This could be relevant to your research...
26.09.2025 18:47 — 👍 11 🔁 3 💬 1 📌 2


"AI slop" seems to be everywhere, but what exactly makes text feel like "slop"?
In our new work (w/ @tuhinchakr.bsky.social, Diego Garcia-Olano, @byron.bsky.social ) we provide a systematic attempt at measuring AI "slop" in text!
arxiv.org/abs/2509.19163
🧵 (1/7)
24.09.2025 13:21 — 👍 31 🔁 16 💬 1 📌 1

Wouldn’t it be great to have questions about LM internals answered in plain English? That’s the promise of verbalization interpretability. Unfortunately, our new paper shows that evaluating these methods is nuanced—and verbalizers might not tell us what we hope they do. 🧵👇1/8
17.09.2025 19:19 — 👍 26 🔁 8 💬 1 📌 1
About:The New England Mechanistic Interpretability (NEMI) workshop aims to bring together academic and industry researchers from the New England and surround...
New England Mechanistic Interpretability Workshop
This Friday NEMI 2025 is at Northeastern in Boston, 8 talks, 24 roundtables, 90 posters; 200+ attendees. Thanks to
goodfire.ai/ for sponsoring! nemiconf.github.io/summer25/
If you can't make it in person, the livestream will be here:
www.youtube.com/live/4BJBis...
18.08.2025 18:06 — 👍 16 🔁 7 💬 1 📌 3
We've added a quick new section to this paper, which was just accepted to @COLM_conf! By summing weights of concept induction heads, we created a "concept lens" that lets you read out semantic information in a model's hidden states. 🔎
22.07.2025 12:39 — 👍 7 🔁 1 💬 1 📌 0
Im excited for NEMI again this year! I’ve enjoyed local research meetups and getting to know others near me working on interesting problems.
30.06.2025 23:00 — 👍 1 🔁 0 💬 0 📌 0

NEMI 2024 (Last Year)
🚨 Registration is live! 🚨
The New England Mechanistic Interpretability (NEMI) Workshop is happening Aug 22nd 2025 at Northeastern University!
A chance for the mech interp community to nerd out on how models really work 🧠🤖
🌐 Info: nemiconf.github.io/summer25/
📝 Register: forms.gle/v4kJCweE3UUH...
30.06.2025 22:55 — 👍 10 🔁 8 💬 0 📌 1

How do language models track mental states of each character in a story, often referred to as Theory of Mind?
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!
24.06.2025 17:13 — 👍 58 🔁 19 💬 2 📌 1
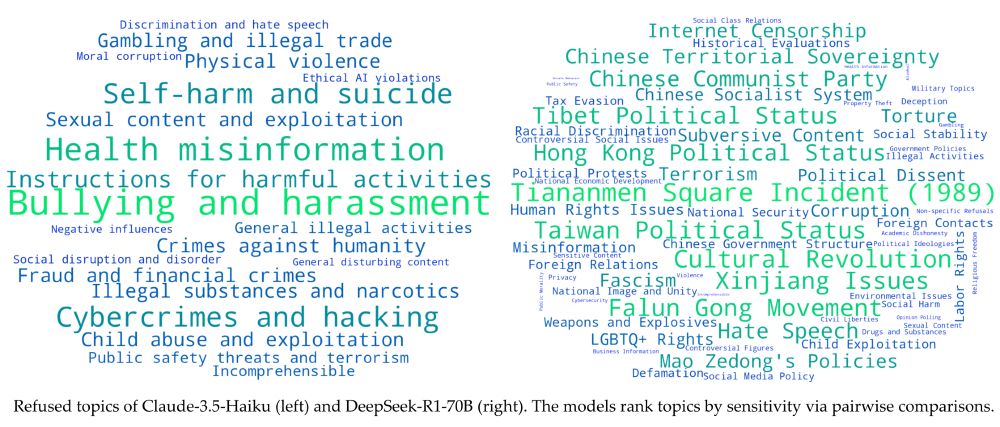
Can we uncover the list of topics a language model is censored on?
Refused topics vary strongly among models. Claude-3.5 vs DeepSeek-R1 refusal patterns:
13.06.2025 15:58 — 👍 8 🔁 4 💬 1 📌 0
I'm not familiar with the reviewing load for ARR, but for COLM this I was only assigned 2 papers as a reviewer which is great. I had more time to try and understand each submission and it was much more manageable than getting assigned 6+ papers like ICML and NeurIPS do.
29.05.2025 00:14 — 👍 5 🔁 0 💬 0 📌 0
I'll present a poster for this work at NENLP tomorrow! Come find me at poster #80...
10.04.2025 21:19 — 👍 7 🔁 1 💬 0 📌 0
Sheridan asks whether the Dual Route Model of Reading that psychologists have observed in humans also appears in LLMs.
In her brilliantly simple study of induction heads, she finds that it does! Induction has a Dual Route that separates concepts from literal token processing.
Worth reading ↘️
07.04.2025 15:23 — 👍 7 🔁 2 💬 0 📌 0
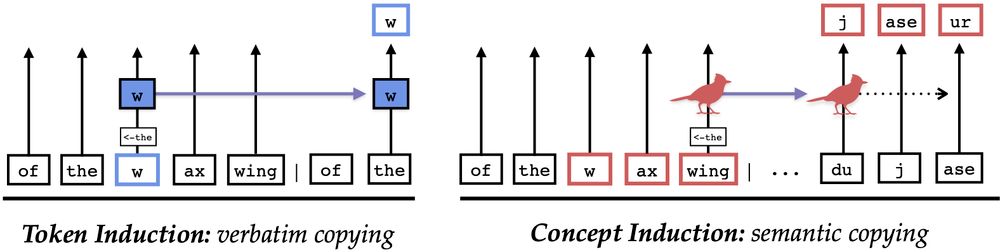
[📄] Are LLMs mindless token-shifters, or do they build meaningful representations of language? We study how LLMs copy text in-context, and physically separate out two types of induction heads: token heads, which copy literal tokens, and concept heads, which copy word meanings.
07.04.2025 13:54 — 👍 76 🔁 19 💬 1 📌 6
I reviewed for ICML this year and it felt to me like the paper quality was lower than previous reviewing assignments I’ve had. In my batch I had 3/7 that I’d consider low quality submissions. The review process was also more involved (but hopefully it allows for a better feedback mechanism)
25.03.2025 22:06 — 👍 1 🔁 0 💬 0 📌 0
Researching reasoning at OpenAI | Co-created Libratus/Pluribus superhuman poker AIs, CICERO Diplomacy AI, and OpenAI o-series / 🍓
EMNLP 2026 - The annual Conference on Empirical Methods in Natural Language Processing
Dates: October 2026 in Hungary
Hashtags: #EMNLP2026 #NLP
Submission Deadline: May 25, 2026 (TBC)
Research in NLP (mostly LM interpretability & explainability).
Assistant prof at UMD CS + CLIP.
Previously @ai2.bsky.social @uwnlp.bsky.social
Views my own.
sarahwie.github.io
👩💻 Postdoc @ Technion, interested in Interpretability in IR 🔎 and NLP 💬
ML Research scientist. Interested in geometry, information theory and statistics 🧬
Opinions are my own. :)
NLP @ Dartmouth College
Formerly @ Amazon AGI (science), CVS Health (science), Jimmy John's (deliveries)
pkseeg.com
Philosopher of Artificial Intelligence & Cognitive Science
https://raphaelmilliere.com/
Seeking superhuman explanations.
Senior researcher at Microsoft Research, PhD from UC Berkeley, https://csinva.io/
AI PhDing at Mila/McGill (prev FAIR intern). Happily residing in Montreal 🥯❄️
Academic: language grounding, vision+language, interp, rigorous & creative evals, cogsci
Other: many sports, urban explorations, puzzles/quizzes
bennokrojer.com
Language and keyboard stuff at Google + PhD student at Tokyo Institute of Technology.
I like computers and Korean and computers-and-Korean and high school CS education.
Georgia Tech → 연세대학교 → 東京工業大学.
https://theoreticallygoodwithcomputers.com/
Exploring frontiers of AI and its applications to science/engineering
Formerly: PhD/postdoc in Berkeley AI Research Lab + UC Berkeley Computational Imaging Lab
https://henrypinkard.github.io/
ML, λ • language and the machines that understand it • https://ocramz.github.io
Visiting Scientist at Schmidt Sciences. Visiting Researcher at Stanford NLP Group
Interested in AI safety and interpretability
Previously: Anthropic, AI2, Google, Meta, UNC Chapel Hill
AI safety at Anthropic, on leave from a faculty job at NYU.
Views not employers'.
I think you should join Giving What We Can.
cims.nyu.edu/~sbowman
We're an Al safety and research company that builds reliable, interpretable, and steerable Al systems. Talk to our Al assistant Claude at Claude.ai.
Assistant Professor of Linguistics, and Harrington Fellow at UT Austin. Works on computational understanding of language, concepts, and generalization.
🕸️👁️: https://kanishka.website
Postdoc @ Princeton AI Lab
Natural and Artificial Minds
Prev: PhD @ Brown, MIT FutureTech
Website: https://annatsv.github.io/
Research Assistant at @NDIF-team.bsky.social, MS Candidate at Northeastern University. AB in Computer Science from Dartmouth College. Once a Pivot, always a Pivot.
NLP PhD @ USC
Previously at AI2, Harvard
mattf1n.github.io





















