Pretty shocking vulnerability that the community should be aware of!
11.03.2025 23:18 — 👍 3 🔁 0 💬 0 📌 0

Enabling Autoregressive Models to Fill In Masked Tokens
Historically, LLMs have been trained using either autoregressive (AR) or masked language modeling (MLM) objectives, with AR models gaining dominance in recent years. However, AR models are inherently ...
Please check out the rest of the paper! We propose: how MARIA can be used for test time scaling, how to initialize MARIA weights for efficient training, how MARIA representations differ, and more…
arxiv.org/abs/2502.06901
Thanks to my advisors Aditya Grover and @guyvdb.bsky.social
14.02.2025 00:28 — 👍 1 🔁 0 💬 0 📌 0
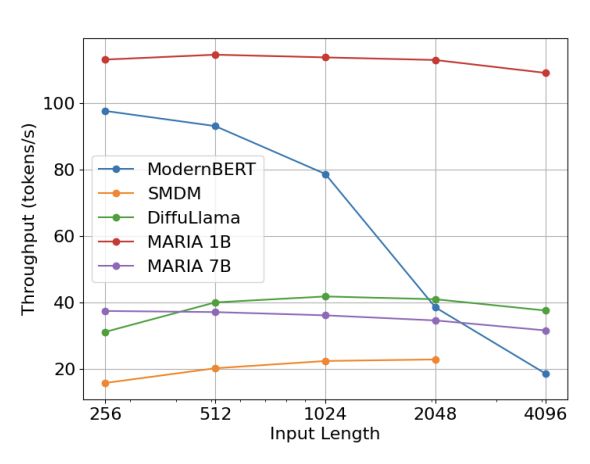
MARIA 1B achieves the best throughput numbers, and MARIA 7B achieves similar throughput to DiffuLlama, but better samples as previously noted. Here, we see that ModernBERT despite being much smaller does not scale well for masked infilling because it cannot KV cache.
14.02.2025 00:28 — 👍 0 🔁 0 💬 1 📌 0

We perform infilling on downstream data with words masked 50 percent. Using GPT4o-mini as a judge we compute the ELO scores for each model respectively. MARIA 7B and 1B have the highest rating ELO rating under the Bradley-Terry model.
14.02.2025 00:28 — 👍 0 🔁 0 💬 1 📌 0

MARIA achieves far better perplexity than just using ModernBERT autoregressively and discrete diffusion models on downstream masked infilling test sets. Based on parameter counts, MARIA presents the most effective way to scale models for masked token infilling.
14.02.2025 00:28 — 👍 0 🔁 0 💬 1 📌 0

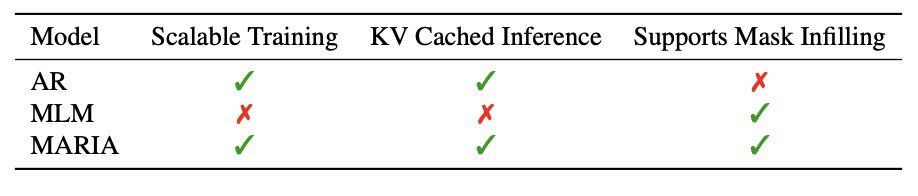
We can get the best of both worlds with MARIA: train a linear decoder to combine the hidden states of an AR and MLM model. This enables AR masked infilling with the advantages of a more scalable AR architecture, such as KV cached inference. We combine OLMo and ModernBERT.
14.02.2025 00:28 — 👍 1 🔁 0 💬 1 📌 0
Autoregressive (AR) LMs are more compute efficient to train than Masked LMs (MLM), which compute a loss on some fixed ratio e.g. 30% of the tokens instead of 100% like AR. Unlike MLM, AR models can also KV cache at inference time, but they cannot infill masked tokens.
14.02.2025 00:28 — 👍 0 🔁 0 💬 1 📌 0
“That’s one small [MASK] for [MASK], a giant [MASK] for mankind.” – [MASK] Armstrong
Can autoregressive models predict the next [MASK]? It turns out yes, and quite easily…
Introducing MARIA (Masked and Autoregressive Infilling Architecture)
arxiv.org/abs/2502.06901
14.02.2025 00:28 — 👍 6 🔁 1 💬 1 📌 0
Interesting. I always felt the reviews should be even more independent so that the aggregate score has lower variance
03.01.2025 21:21 — 👍 0 🔁 0 💬 0 📌 0
🇮🇹 Stats PhD @ University of Edinburgh 🏴
@ellis.eu PhD - visiting @avehtari.bsky.social 🇫🇮
🤔💭 Monte Carlo, probabilistic ML.
Interested in many things relating to probML, keen to learn applications in climate/science.
https://www.branchini.fun/about
https://cs.ucla.edu/~renatolg/
PhD student @ KU Leuven | maene.dev | #neurosymbolic learning & #probabilistic reasoning
First-year Ph.D. Student @ StarAI Lab, UCLA
Harvey Mudd College ‘24
data scientist studying how kids learn to speak, dad, jump roper, bayesian, tjmahr.com
computers and music are (still) fun
Teaching deep learning over here:
https://youtube.com/@deeplearningexplained?si=yzsA4kpGN_8VDEY0
Postdoc @ UCLA StarAI Lab, PhD in CS from Oxford. Probabilistic ML, Tractable Models, Causality
Post-doc @ VU Amsterdam, prev University of Edinburgh.
Neurosymbolic Machine Learning, Generative Models, commonsense reasoning
https://www.emilevankrieken.com/
Geometric deep learning + Computer vision
INSERM group leader @ Neuromodulation Institute and NeuroSpin (Paris) in computational neuroscience.
How and why are computations enabling cognition distributed across the brain?
Expect neuroscience and ML content.
jbarbosa.org
I lead Cohere For AI. Formerly Research
Google Brain. ML Efficiency, LLMs,
@trustworthy_ml.
Probabilistic + logical + algebraic reasoning/learning
Assistant prof. @ University of Trento, Marie Skłodowska-Curie fellow
https://paolomorettin.github.io/
Anti-cynic. Towards a weirder future. Reinforcement Learning, Autonomous Vehicles, transportation systems, the works. Asst. Prof at NYU
https://emerge-lab.github.io
https://www.admonymous.co/eugenevinitsky
Decision-making under uncertainty, machine learning theory, artificial intelligence · anti-ideological · Assistant Research Professor, Cornell
https://avt.im/ · https://scholar.google.com/citations?user=EGKYdiwAAAAJ&sortby=pubdate
Assistant Professor in Computer Science at UofT.
Group Leader, Generative AI | NeurIPS 2024 Program Chair | Principal Scientist & Director | Founder of Amsterdam AI Solutions
MTS @ OpenAI. Ex GDM. Ex Google Brain.
Come for the shitposts, stay for the shitposts.
Liable to post about random nerdy things.
Postdoc at ETH. Formerly, PhD student at the University of Cambridge :)





















